Hello everyone. I am a bit new to the Proxmox community so please pardon me should I miss something regarding forum or community etiquette/decorum.
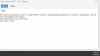
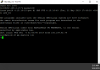
A Proxmox Cluster setup I have been charged with supporting has developed a strange and unexplained issue that I have been unable to find a solution for. Notably several days ago all of the nodes within the cluster (7 in total) became unresponsive to command input from either the WebGUI or the CLI (both via SSH, and KVM). This issue primarily manifests with CLI commands relating to Proxmox such as 'qm status' or attempting to delete nodes using the GUI. Attached are screenshots of attempts to destroy a VM via CLI and perform a backup via GUI. Both hold as depicted indefinitely, and both are action that on the same cluster took less than five minutes in full.
Please note the actual VMs themselves appear to be functioning normally. A reboot was attempted on the least critical node, 0x00000005, however after reboot the situation was not resolved and it was not possible to execute commands locally on the server. Additionally post reboot the VMs on the server began exhibiting abnormal behavior.
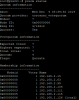
To my knowledge no hardware of software changes have been made to the cluster in a time-frame that would explain this recent abnormal behavior. However based upon the fact that the entire cluster is effected it has to be something with the clustering. To this end I have looked into the quorum with the 'pvecm status' command and appended the output below. From these results it appears that the cluster is successfully quorum-ed and I am at a loss to explain this behavior.
Any ideas about what could cause this or where to look would be much appreciated. Even if it would be possible to get backups running again that would be fantastic as it would be possible to reload Proxmox and migrate to fresh installs.
root@pve22:~# pvecm status
Quorum information
------------------
Date: Wed Dec 4 05:39:50 2019
Quorum provider: corosync_votequorum
Nodes: 7
Node ID: 0x00000006
Ring ID: 4/12612
Quorate: Yes
Votequorum information
----------------------
Expected votes: 7
Highest expected: 7
Total votes: 7
Quorum: 4
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000004 1 192.168.2.15
0x00000008 1 192.168.2.63
0x00000001 1 192.168.2.99
0x00000002 1 192.168.2.104
0x00000003 1 192.168.2.111
0x00000005 1 192.168.2.115
0x00000006 1 192.168.2.126 (local)
Thank you for taking the time to read this and for any insight shared, it is much appreciated.
Addendum: All servers in cluster are running Proxmox Virtual Environment 5.4-6.
A Proxmox Cluster setup I have been charged with supporting has developed a strange and unexplained issue that I have been unable to find a solution for. Notably several days ago all of the nodes within the cluster (7 in total) became unresponsive to command input from either the WebGUI or the CLI (both via SSH, and KVM). This issue primarily manifests with CLI commands relating to Proxmox such as 'qm status' or attempting to delete nodes using the GUI. Attached are screenshots of attempts to destroy a VM via CLI and perform a backup via GUI. Both hold as depicted indefinitely, and both are action that on the same cluster took less than five minutes in full.
Please note the actual VMs themselves appear to be functioning normally. A reboot was attempted on the least critical node, 0x00000005, however after reboot the situation was not resolved and it was not possible to execute commands locally on the server. Additionally post reboot the VMs on the server began exhibiting abnormal behavior.
To my knowledge no hardware of software changes have been made to the cluster in a time-frame that would explain this recent abnormal behavior. However based upon the fact that the entire cluster is effected it has to be something with the clustering. To this end I have looked into the quorum with the 'pvecm status' command and appended the output below. From these results it appears that the cluster is successfully quorum-ed and I am at a loss to explain this behavior.
Any ideas about what could cause this or where to look would be much appreciated. Even if it would be possible to get backups running again that would be fantastic as it would be possible to reload Proxmox and migrate to fresh installs.
root@pve22:~# pvecm status
Quorum information
------------------
Date: Wed Dec 4 05:39:50 2019
Quorum provider: corosync_votequorum
Nodes: 7
Node ID: 0x00000006
Ring ID: 4/12612
Quorate: Yes
Votequorum information
----------------------
Expected votes: 7
Highest expected: 7
Total votes: 7
Quorum: 4
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000004 1 192.168.2.15
0x00000008 1 192.168.2.63
0x00000001 1 192.168.2.99
0x00000002 1 192.168.2.104
0x00000003 1 192.168.2.111
0x00000005 1 192.168.2.115
0x00000006 1 192.168.2.126 (local)
Thank you for taking the time to read this and for any insight shared, it is much appreciated.
Addendum: All servers in cluster are running Proxmox Virtual Environment 5.4-6.