Hello!
We have a three node cluster, the storage for the vms is ceph. I have migrated lot of physical server to pve with clonezilla, i have also converted round about 15 vmware vms to pve. In the past without issues.
Now we had the problem (the third problem/server after a while) - an ubuntu 18.04 hangs up, kernel panic and wont reboot - no bootable disk. I tried a lot of different iso images to boot the vm and try to "enter" the disk, but the whole disk is empty.
One week later, another vm with sles 12 SP3, it hangs up. It is not available, no ping, the vm looks like that it is in a freeze state. Ok, i would like to reboot the vm, but the same error during boot, no bootable device... i tried also to boot with live iso .... no chance, only to restore the vm with backup helps.
Today the same issue, it looks like that the vm hangs or is in freeze state, stop and start does not work. No bootable device, now the restore is running..
Does anyone have same issues with vm´s with ceph? I never had this in the past, it is not clear why the vms loose all data on the ceph disk after a reboot because the vm hangs.
Thanks for any help!
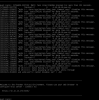
proxmox-ve: 5.4-2 (running kernel: 4.15.18-18-pve)
pve-manager: 5.4-13 (running version: 5.4-13/aee6f0ec)
pve-kernel-4.15: 5.4-6
pve-kernel-4.15.18-18-pve: 4.15.18-44
pve-kernel-4.15.18-17-pve: 4.15.18-43
pve-kernel-4.15.18-16-pve: 4.15.18-41
pve-kernel-4.15.18-15-pve: 4.15.18-40
pve-kernel-4.15.18-14-pve: 4.15.18-39
pve-kernel-4.15.18-10-pve: 4.15.18-32
ceph: 12.2.12-pve1
corosync: 2.4.4-pve1
We have a three node cluster, the storage for the vms is ceph. I have migrated lot of physical server to pve with clonezilla, i have also converted round about 15 vmware vms to pve. In the past without issues.
Now we had the problem (the third problem/server after a while) - an ubuntu 18.04 hangs up, kernel panic and wont reboot - no bootable disk. I tried a lot of different iso images to boot the vm and try to "enter" the disk, but the whole disk is empty.
One week later, another vm with sles 12 SP3, it hangs up. It is not available, no ping, the vm looks like that it is in a freeze state. Ok, i would like to reboot the vm, but the same error during boot, no bootable device... i tried also to boot with live iso .... no chance, only to restore the vm with backup helps.
Today the same issue, it looks like that the vm hangs or is in freeze state, stop and start does not work. No bootable device, now the restore is running..
Does anyone have same issues with vm´s with ceph? I never had this in the past, it is not clear why the vms loose all data on the ceph disk after a reboot because the vm hangs.
Thanks for any help!
proxmox-ve: 5.4-2 (running kernel: 4.15.18-18-pve)
pve-manager: 5.4-13 (running version: 5.4-13/aee6f0ec)
pve-kernel-4.15: 5.4-6
pve-kernel-4.15.18-18-pve: 4.15.18-44
pve-kernel-4.15.18-17-pve: 4.15.18-43
pve-kernel-4.15.18-16-pve: 4.15.18-41
pve-kernel-4.15.18-15-pve: 4.15.18-40
pve-kernel-4.15.18-14-pve: 4.15.18-39
pve-kernel-4.15.18-10-pve: 4.15.18-32
ceph: 12.2.12-pve1
corosync: 2.4.4-pve1
Last edited:



") I really dont know why - the screenshots of the two VMs see above.
I really dont know why - the screenshots of the two VMs see above.