Hi everybody,
a while ago we set up a three node Proxmox cluster and as storage backend we use the built in ceph features.
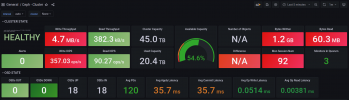
After a while we noticed a strong decreasing of I/O Perfomance in the VMs when it comes to writes of small files.
Writing a single big file at once seems to perform quit normal, also does reading in all cases.
When moving complete VM Disks from Ceph to another external storage and back also performs very good, no problems here.
A concrete test case:
Having a test VM with a plain Debian installation, we install gimp ("apt install gimp"). The extraction of these 116 packages, mostly each of them just a few KB in size takes much longer as it should. This is even worse when removing gimp and all dependencies completely ("apt autoremove gimp").
What is to be mentioned: When we do this little test, it doesn't matter if this Test VM is running completely alone in the cluster or if there are other VMs running; performance is always the same bad.
This is our architecture:
Three identical HP ProLiant DL380 Gen9, each of them:
a while ago we set up a three node Proxmox cluster and as storage backend we use the built in ceph features.
After a while we noticed a strong decreasing of I/O Perfomance in the VMs when it comes to writes of small files.
Writing a single big file at once seems to perform quit normal, also does reading in all cases.
When moving complete VM Disks from Ceph to another external storage and back also performs very good, no problems here.
A concrete test case:
Having a test VM with a plain Debian installation, we install gimp ("apt install gimp"). The extraction of these 116 packages, mostly each of them just a few KB in size takes much longer as it should. This is even worse when removing gimp and all dependencies completely ("apt autoremove gimp").
What is to be mentioned: When we do this little test, it doesn't matter if this Test VM is running completely alone in the cluster or if there are other VMs running; performance is always the same bad.
This is our architecture:
Three identical HP ProLiant DL380 Gen9, each of them:
- CPU: 2x Intel(R) Xeon(R) CPU E5-2673 v3 @ 2.40GHz
- RAM: 128GB DDR4 2133 MHz
- Storage
- HDD Controller: HP Smart HBA H240 (current firmware v 7.20) with these HDDs:
- 4 identical 3TB SAS 7.200 rpm (Model: HP MB3000FCWDH)
- 1xNVMe 240GB
- 1xNVMe 1TB
- 1xNVMe 2TB
- HDD Controller: HP Smart HBA H240 (current firmware v 7.20) with these HDDs:
- Network:
- HPE Ethernet 1Gb 4-port 331i Adapter - NIC
- HP InfiniBand FDR/Ethernet 40Gb 2-port 544+FLR-QSFP
- Proxmox VE 7.3-4 OS installed at the 240GB NVMe
- Proxmox 3 Node Cluster:

- Network config:
- 1Gb Ports of 331i connected to a switch for Proxmox and "outside" traffic, as a LACP bond (Network 172.20.4.0/24)
- 40 Gb Ports of InfiniBand directly connected between the 3 servers as a RSTP Loop for Ceph Cluster Traffic (Network 172.20.81.0/24), as described here: https://pve.proxmox.com/wiki/Full_Mesh_Network_for_Ceph_Server

- Ceph config:
- cluster_network: 172.20.81.0/24 (The 40Gb InfiniBand RSTP Loop)
- public_network: 172.20.4.0/24 (The 1Gb LACP Bond)

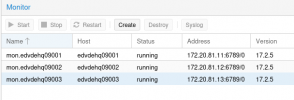
- 1 Monitor and Manager Service running on each Proxmox node in 172.20.81.0/24 Net:


- 1 MDS on each node for cephfs running in 172.20.4.0/24 Net:

- OSD: 4xSAS HDDs and 2 remaining NVMes (1x 1TB, 1x2TB) on each Node:

- Pools / Proxmox Storage:
- 1 Pool just using NVMes (crush rules)
- 1 Pool just using HDDs (crush rules)

Attachments

Last edited:


")