We have been using Proxmox for years and have a 3 nodes cluster that had been healthy for a while then recently we noticed that VMs couldn't be deleted (destroyed) by any means (GUI, CLI, or the API)
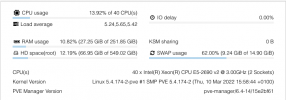
We don't see any storage issues that could refer to a problem with file locking, The VM disk image is getting deleted however the configuration file stays so the VM remains in the VM list even though no disk is attached, Disk capacity is 5% utilized - CPU and memory are not taxed

We are using local disks on each server, as well as a simple Ceph cluster with 2 RBDs per node - the network is stable and has been tested for a long time
What we have tested so far :
- Destroy from GUI, CLI, API
- Restart the PVE, cluster, ceph services
- Upgraded the node to the latest version
- Rebooted all the nodes (Was painful as they we have to migrate VMs)
Note: After reboot destroy worked for a short time then stopped working
Checking the logs is not giving any errors or clues
Any hint or assistance would be appreciated
---------------------
pveversion -v
proxmox-ve: 6.4-1 (running kernel: 5.4.174-2-pve)
pve-manager: 6.4-14 (running version: 6.4-14/15e2bf61)
pve-kernel-5.4: 6.4-15
pve-kernel-helper: 6.4-15
pve-kernel-5.4.174-2-pve: 5.4.174-2
pve-kernel-5.4.114-1-pve: 5.4.114-1
ceph: 15.2.15-pve1~bpo10
ceph-fuse: 15.2.15-pve1~bpo10
corosync: 3.1.5-pve2~bpo10+1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: residual config
ifupdown2: 3.0.0-1+pve4~bpo10
libjs-extjs: 6.0.1-10
libknet1: 1.22-pve2~bpo10+1
libproxmox-acme-perl: 1.1.0
libproxmox-backup-qemu0: 1.1.0-1
libpve-access-control: 6.4-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.4-4
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.2-3
libpve-network-perl: 0.6.0
libpve-storage-perl: 6.4-1
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.1.13-2
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.6-2
pve-cluster: 6.4-1
pve-container: 3.3-6
pve-docs: 6.4-2
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-4
pve-firmware: 3.3-2
pve-ha-manager: 3.1-1
pve-i18n: 2.3-1
pve-qemu-kvm: 5.2.0-6
pve-xtermjs: 4.7.0-3
qemu-server: 6.4-2
smartmontools: 7.2-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.7-pve1
We don't see any storage issues that could refer to a problem with file locking, The VM disk image is getting deleted however the configuration file stays so the VM remains in the VM list even though no disk is attached, Disk capacity is 5% utilized - CPU and memory are not taxed
We are using local disks on each server, as well as a simple Ceph cluster with 2 RBDs per node - the network is stable and has been tested for a long time
What we have tested so far :
- Destroy from GUI, CLI, API
- Restart the PVE, cluster, ceph services
- Upgraded the node to the latest version
- Rebooted all the nodes (Was painful as they we have to migrate VMs)
Note: After reboot destroy worked for a short time then stopped working
Checking the logs is not giving any errors or clues
Any hint or assistance would be appreciated
---------------------
pveversion -v
proxmox-ve: 6.4-1 (running kernel: 5.4.174-2-pve)
pve-manager: 6.4-14 (running version: 6.4-14/15e2bf61)
pve-kernel-5.4: 6.4-15
pve-kernel-helper: 6.4-15
pve-kernel-5.4.174-2-pve: 5.4.174-2
pve-kernel-5.4.114-1-pve: 5.4.114-1
ceph: 15.2.15-pve1~bpo10
ceph-fuse: 15.2.15-pve1~bpo10
corosync: 3.1.5-pve2~bpo10+1
criu: 3.11-3
glusterfs-client: 5.5-3
ifupdown: residual config
ifupdown2: 3.0.0-1+pve4~bpo10
libjs-extjs: 6.0.1-10
libknet1: 1.22-pve2~bpo10+1
libproxmox-acme-perl: 1.1.0
libproxmox-backup-qemu0: 1.1.0-1
libpve-access-control: 6.4-3
libpve-apiclient-perl: 3.1-3
libpve-common-perl: 6.4-4
libpve-guest-common-perl: 3.1-5
libpve-http-server-perl: 3.2-3
libpve-network-perl: 0.6.0
libpve-storage-perl: 6.4-1
libqb0: 1.0.5-1
libspice-server1: 0.14.2-4~pve6+1
lvm2: 2.03.02-pve4
lxc-pve: 4.0.6-2
lxcfs: 4.0.6-pve1
novnc-pve: 1.1.0-1
proxmox-backup-client: 1.1.13-2
proxmox-mini-journalreader: 1.1-1
proxmox-widget-toolkit: 2.6-2
pve-cluster: 6.4-1
pve-container: 3.3-6
pve-docs: 6.4-2
pve-edk2-firmware: 2.20200531-1
pve-firewall: 4.1-4
pve-firmware: 3.3-2
pve-ha-manager: 3.1-1
pve-i18n: 2.3-1
pve-qemu-kvm: 5.2.0-6
pve-xtermjs: 4.7.0-3
qemu-server: 6.4-2
smartmontools: 7.2-pve2
spiceterm: 3.1-1
vncterm: 1.6-2
zfsutils-linux: 2.0.7-pve1
")