Hello,
I work for multiple clients and one of them wanted us to create a Proxmox cluster to assure them fault tolerance and a good hypervisor that's cost-efficient.
It's the first time we put a Proxmox cluster in Production environment for a client. We've only used single node proxmox. Client wanted to use physical HDD of the servers as storage, and we made a Ceph cluster.
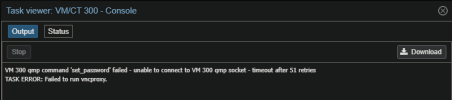
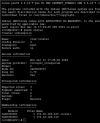
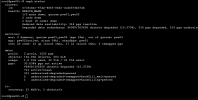
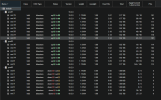
When I try to test HA on failure of a full node, I shut the server down using IDRAC or shutdown command in shell. The quorum stays up, OSDs go down on the shut down node but they stay IN (at least 2 OSDs everytime stay in). In that state, the running VM/CT are migrated succsefully but arent running well. (vm icon is up but vm error on start in logs).
When i put the OSDs out manually, everything goes well again and goes up on my 2 remaining nodes.
I've searched everywhere for information about that but I don't see anything that can help me.
Feel free to ask me for more information in order to help.
I have everything on the latest version available today.
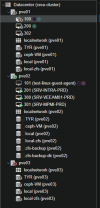
Nodes : 3
mon and mgr : 3
mon_osd_down_out_interval : 120
OSDS : 8 on node 1 and 3. 7 on node 2.
Problem appears on all nodes when I shut them down (one by one to keep quorum.)
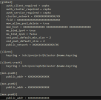
Ceph public network on management network
Ceph network on a dedicated vlan
But I only have 1 sfp+ configured right now where all the network goes through.
I hope it's not a foggy explanation.
Thank you !
I work for multiple clients and one of them wanted us to create a Proxmox cluster to assure them fault tolerance and a good hypervisor that's cost-efficient.
It's the first time we put a Proxmox cluster in Production environment for a client. We've only used single node proxmox. Client wanted to use physical HDD of the servers as storage, and we made a Ceph cluster.
When I try to test HA on failure of a full node, I shut the server down using IDRAC or shutdown command in shell. The quorum stays up, OSDs go down on the shut down node but they stay IN (at least 2 OSDs everytime stay in). In that state, the running VM/CT are migrated succsefully but arent running well. (vm icon is up but vm error on start in logs).
When i put the OSDs out manually, everything goes well again and goes up on my 2 remaining nodes.
I've searched everywhere for information about that but I don't see anything that can help me.
Feel free to ask me for more information in order to help.
I have everything on the latest version available today.
Nodes : 3
mon and mgr : 3
mon_osd_down_out_interval : 120
OSDS : 8 on node 1 and 3. 7 on node 2.
Problem appears on all nodes when I shut them down (one by one to keep quorum.)
Ceph public network on management network
Ceph network on a dedicated vlan
But I only have 1 sfp+ configured right now where all the network goes through.
I hope it's not a foggy explanation.
Thank you !