Hello everyone,
I moved a passthrough disk to another VM and the web GUI frozen and then forced a reboot. the issue is that system is now stuck in an endless loop.
1) server is booting, I can see my ASRock logo and boot options
2) I can see the countdown to enter PVE
3) my NICs stops
4) system reboots
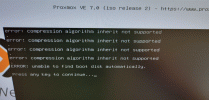
I tried to use the rescue boot but it just fails with a message:
"error: compression algorithm inherit not supported" (this message appears 4 times)
"error: unable to find boot disk automatically"
"press any key to continue..."
so it doesn't even reach the point where I can investigate the conf files.
another thing is that if I wait a bit, and choose the "rescue boot" it runs, and then it abruptly restarts (I can see that the NICs lights are gone at the same time),
So now I have no idea how to access the files, or how to start and troubleshoot this issue.
I'm not an expert and not sure what I did wrong or this is just bad luck")
any suggestions?
[UPDATE]
I've managed to login quickly via ssh to the node.
I did zfs pool status and this was the result (I unplugged one of my raid drives, so I guess that's why it shows "degraded"?)
but still I'm not able to login to the web UI and it just rebooted again.
Linux proxmox 5.11.22-4-pve #1 SMP PVE 5.11.22-8 (Fri, 27 Aug 2021 11:51:34 +020 0) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Mon Apr 11 16:52:55 2022 from 192.168.0.41
root@proxmox:~# zpool status
pool: local_vm_storage_1tb_sam
state: DEGRADED
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:10:57 with 0 errors on Sun Feb 13 00:34:58 2022
config:
NAME STATE READ WRITE CKSU M
local_vm_storage_1tb_sam DEGRADED 0 0 0
ata-Samsung_SSD_860_EVO_1TB_S599NZFNA00416T DEGRADED 0 0 0 too many errors
errors: No known data errors
pool: rpool
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J
scan: resilvered 141M in 00:00:01 with 0 errors on Mon Apr 11 14:28:09 2022
config:
NAME STATE READ WRI TE CKSUM
rpool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
ata-KINGSTON_SA400S37120G_50026B778404BFFD-part3 ONLINE 0 0 0
7041556851563507203 UNAVAIL 0 0 0 was /dev/disk/by-id/ata-INTEL_SSDSC2CW120A3_CVCV224405EK120BGN-part3
errors: No known data errors
root@proxmox:~#
I'm stuck.
_________________________________________________________________________________________________
another update (some progress I guess?)
I manage to have about 10 minutes of ssh time and I can access the files via SCP.
It's not enough time for me to create backups for my VMs as the connection drops unexpectedly and ruins the backup.
What should I copy from the node?
maybe there's still a chance for me to recover my existing env.?
if I will re-install PVE, would the data on the other storage drives be accessible without formatting or initializing the drives? (like in windows)
if that's the case, I wouldn't mind just re-installing and attaching the drives, since all my actual data are on them (I learned my lesson to have data separated from the actual VM so in cases like these I might a silver lining)
Please advise!
Regards,
Didi
I moved a passthrough disk to another VM and the web GUI frozen and then forced a reboot. the issue is that system is now stuck in an endless loop.
1) server is booting, I can see my ASRock logo and boot options
2) I can see the countdown to enter PVE
3) my NICs stops
4) system reboots
I tried to use the rescue boot but it just fails with a message:
"error: compression algorithm inherit not supported" (this message appears 4 times)
"error: unable to find boot disk automatically"
"press any key to continue..."
so it doesn't even reach the point where I can investigate the conf files.
another thing is that if I wait a bit, and choose the "rescue boot" it runs, and then it abruptly restarts (I can see that the NICs lights are gone at the same time),
So now I have no idea how to access the files, or how to start and troubleshoot this issue.
I'm not an expert and not sure what I did wrong or this is just bad luck
any suggestions?
[UPDATE]
I've managed to login quickly via ssh to the node.
I did zfs pool status and this was the result (I unplugged one of my raid drives, so I guess that's why it shows "degraded"?)
but still I'm not able to login to the web UI and it just rebooted again.
Linux proxmox 5.11.22-4-pve #1 SMP PVE 5.11.22-8 (Fri, 27 Aug 2021 11:51:34 +020 0) x86_64
The programs included with the Debian GNU/Linux system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Debian GNU/Linux comes with ABSOLUTELY NO WARRANTY, to the extent
permitted by applicable law.
Last login: Mon Apr 11 16:52:55 2022 from 192.168.0.41
root@proxmox:~# zpool status
pool: local_vm_storage_1tb_sam
state: DEGRADED
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:10:57 with 0 errors on Sun Feb 13 00:34:58 2022
config:
NAME STATE READ WRITE CKSU M
local_vm_storage_1tb_sam DEGRADED 0 0 0
ata-Samsung_SSD_860_EVO_1TB_S599NZFNA00416T DEGRADED 0 0 0 too many errors
errors: No known data errors
pool: rpool
state: DEGRADED
status: One or more devices could not be used because the label is missing or
invalid. Sufficient replicas exist for the pool to continue
functioning in a degraded state.
action: Replace the device using 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-4J
scan: resilvered 141M in 00:00:01 with 0 errors on Mon Apr 11 14:28:09 2022
config:
NAME STATE READ WRI TE CKSUM
rpool DEGRADED 0 0 0
mirror-0 DEGRADED 0 0 0
ata-KINGSTON_SA400S37120G_50026B778404BFFD-part3 ONLINE 0 0 0
7041556851563507203 UNAVAIL 0 0 0 was /dev/disk/by-id/ata-INTEL_SSDSC2CW120A3_CVCV224405EK120BGN-part3
errors: No known data errors
root@proxmox:~#
I'm stuck.
_________________________________________________________________________________________________
another update (some progress I guess?)
I manage to have about 10 minutes of ssh time and I can access the files via SCP.
It's not enough time for me to create backups for my VMs as the connection drops unexpectedly and ruins the backup.
What should I copy from the node?
maybe there's still a chance for me to recover my existing env.?
if I will re-install PVE, would the data on the other storage drives be accessible without formatting or initializing the drives? (like in windows)
if that's the case, I wouldn't mind just re-installing and attaching the drives, since all my actual data are on them (I learned my lesson to have data separated from the actual VM so in cases like these I might a silver lining
)Please advise!
Regards,
Didi
Attachments
Last edited: