Hi,
I'm running a Proxmox 7.2-7 cluster with Ceph 16.2.9 "Pacific".
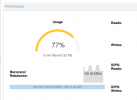
I can't tell the difference between Ceph > Usage and Ceph > Pools > Used (see screenshots).
Can someone please explain what's the actual space used in my Ceph storage? Do you think that 90% used pool is potentially dangerous or normal? Consider that I have now 74TB of raw disks with the OSDs but I'm going to expand it further in the next few days. In fact, the pool is rebalancing as I'm replacing some OSDs with bigger ones.
Thank you!
I'm running a Proxmox 7.2-7 cluster with Ceph 16.2.9 "Pacific".
I can't tell the difference between Ceph > Usage and Ceph > Pools > Used (see screenshots).
Can someone please explain what's the actual space used in my Ceph storage? Do you think that 90% used pool is potentially dangerous or normal? Consider that I have now 74TB of raw disks with the OSDs but I'm going to expand it further in the next few days. In fact, the pool is rebalancing as I'm replacing some OSDs with bigger ones.
Thank you!

")
 So I'm forced to restart.
So I'm forced to restart.