Hallo liebe Community ") ,
,
wir haben aktuell eine Situation, bei welcher die SCSI Disks innerhalb einer Windows VM (11 und 10), bei verhältnismäßigen kleinen Auslastungen, im Task Manager bei 100% sind, bzw. immer unverhältnismäßig hoch. (Bei ein paar wenigen MB/s oder KB/s geht das bereits auf 100%)
Die VMs liegen auf einem LVM over iSCSI Volume (SAN). Das SAN hat 12x HDDs im RAID6. => Verbunden über 2x 10Gbit/s via Multipathing.
Entsprechend sind die Reaktionszeiten teilweise bei mehreren hundert ms manchmal. Es laufen keine Datenbanken darauf, daher noch ganz verkraftbar.
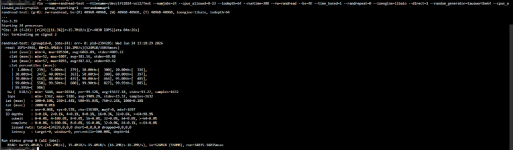
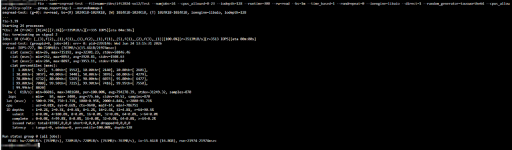
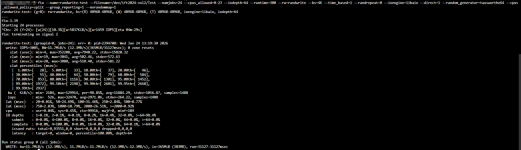
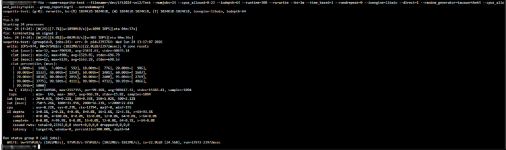
Die Tests in einer dieser VMs zeigen eine gute Performance, für das was gegeben ist, natürlich erreicht es hier die 100% im Taks Manager bereits weit vorher:

Ich gehe davon aus, dass Windows hier einfach keine richtigen Referenzwerte hat und die Berechnung der Disk-Auslastung einfach murks ist?
Weiß evenutell jemand, wie diese Berechnung stattfindet? Hat jemand ähnliche Erfahrungen und kann dieses "Phänomen" bestätigen?
Verwendet wurde der VirtIO Treiber 271.
Das ist mal eine Beispiel VM, allerdings tritt das auch bei einer migrierten Windows 11 VM (von VMware) und einer frisch erstellen Windows 11 VM auf.
Vielen Dank schonmal
,wir haben aktuell eine Situation, bei welcher die SCSI Disks innerhalb einer Windows VM (11 und 10), bei verhältnismäßigen kleinen Auslastungen, im Task Manager bei 100% sind, bzw. immer unverhältnismäßig hoch. (Bei ein paar wenigen MB/s oder KB/s geht das bereits auf 100%)
Die VMs liegen auf einem LVM over iSCSI Volume (SAN). Das SAN hat 12x HDDs im RAID6. => Verbunden über 2x 10Gbit/s via Multipathing.
Entsprechend sind die Reaktionszeiten teilweise bei mehreren hundert ms manchmal. Es laufen keine Datenbanken darauf, daher noch ganz verkraftbar.
Die Tests in einer dieser VMs zeigen eine gute Performance, für das was gegeben ist, natürlich erreicht es hier die 100% im Taks Manager bereits weit vorher:
Ich gehe davon aus, dass Windows hier einfach keine richtigen Referenzwerte hat und die Berechnung der Disk-Auslastung einfach murks ist?
Weiß evenutell jemand, wie diese Berechnung stattfindet? Hat jemand ähnliche Erfahrungen und kann dieses "Phänomen" bestätigen?
Verwendet wurde der VirtIO Treiber 271.
Das ist mal eine Beispiel VM, allerdings tritt das auch bei einer migrierten Windows 11 VM (von VMware) und einer frisch erstellen Windows 11 VM auf.
Code:
agent: 1
bios: ovmf
boot: order=sata0;scsi1;scsi2;scsi0
cores: 2
cpu: x86-64-v3
efidisk0: ift2024-vol2:vm-199-disk-0,efitype=4m,size=4M
machine: pc-i440fx-11.0
memory: 4096
meta: creation-qemu=11.0.0,ctime=1782131041
name: [red]
net0: virtio=[red],bridge=vmbr0
net1: virtio=[red],bridge=vmbr150
numa: 0
ostype: win10
scsi0: none,media=cdrom
scsi1: ift2024-vol2:vm-199-disk-1,iothread=1,size=200G
scsihw: virtio-scsi-single
smbios1: uuid=[red]
sockets: 1
vmgenid: [red]
Code:
# pveversion --verbose
proxmox-ve: 9.2.0 (running kernel: 7.0.2-6-pve)
pve-manager: 9.2.2 (running version: 9.2.2/b9984c6d90a4bd80)
proxmox-kernel-helper: 9.1.0+fde2
proxmox-kernel-7.0: 7.0.2-6
proxmox-kernel-7.0.2-6-pve-signed: 7.0.2-6
amd64-microcode: 3.20250311.1
ceph-fuse: 19.2.3-pve4
corosync: 3.1.10-pve2
criu: 4.1.1-1
frr-pythontools: 10.6.1-1+pve2
ifupdown2: 3.3.0-1+pmx12
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libproxmox-acme-perl: 1.7.1
libproxmox-backup-qemu0: 2.0.2
libproxmox-rs-perl: 0.4.1
libpve-access-control: 9.1.1
libpve-apiclient-perl: 3.4.2
libpve-cluster-api-perl: 9.1.5
libpve-cluster-perl: 9.1.5
libpve-common-perl: 9.1.12
libpve-guest-common-perl: 6.0.3
libpve-http-server-perl: 6.0.5
libpve-network-perl: 1.6.5
libpve-notify-perl: 9.1.5
libpve-rs-perl: 0.15.3
libpve-storage-perl: 9.1.5
libspice-server1: 0.15.2-1+b1
lvm2: 2.03.31-2+pmx1
lxc-pve: 7.0.0-2
lxcfs: 7.0.0-pve1
novnc-pve: 1.7.0-1
proxmox-backup-client: 4.2.0-1
proxmox-backup-file-restore: 4.2.0-1
proxmox-backup-restore-image: 1.0.0
proxmox-firewall: 1.2.3
proxmox-kernel-helper: 9.1.0+fde2
proxmox-mail-forward: 1.0.3
proxmox-mini-journalreader: 1.6
proxmox-offline-mirror-helper: 0.7.4
proxmox-widget-toolkit: 5.2.2
pve-cluster: 9.1.5
pve-container: 6.1.10
pve-docs: 9.2.1
pve-edk2-firmware: 4.2025.05-2
pve-esxi-import-tools: 1.0.1
pve-firewall: 6.0.4
pve-firmware: 3.18-3
pve-ha-manager: 5.2.4
pve-i18n: 3.7.4
pve-qemu-kvm: 11.0.0-3
pve-xtermjs: 6.0.0-1
qemu-server: 9.1.15
smartmontools: 7.5-pve2
spiceterm: 3.4.2
swtpm: 0.8.0+pve3
vncterm: 1.9.2
zfsutils-linux: 2.4.2-pve1Vielen Dank schonmal