Hi!
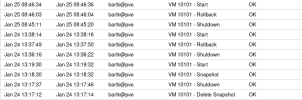
In the past days, we've had three separate VMs where the disk of the VM was corrupt after reverting to a snapshot. On one of these, we had reverted to this snapshot before, succesfully. All three VM's are on Ceph storage. The settings are mixed - two Windows VMs with a virtio driver, one Linux VM with the scsi driver and discard=on. Writeback cache is used on all disks.
The Linux disk seems to be just nulls, the Windows disks still have data in them. None of them have a valid partition table now.
On the Ceph side things don't look the same either. The Linux disk has no rbd data blocks, the Windows disks do, as confirmed by using
All of this is in line with the backups we make with proxmox-backup-server: backups made before the revert look ok and it is possible to do a file restore from them in the GUI, but it is not possible to do a file restore from backups made after the revert.
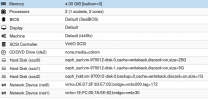
This is Proxmox 6 with Ceph Octopus (output of pveversion -v is attached).
I'd be grateful for any hints on where to start figuring out how this could have happened!
Thanks a lot, Roel
In the past days, we've had three separate VMs where the disk of the VM was corrupt after reverting to a snapshot. On one of these, we had reverted to this snapshot before, succesfully. All three VM's are on Ceph storage. The settings are mixed - two Windows VMs with a virtio driver, one Linux VM with the scsi driver and discard=on. Writeback cache is used on all disks.
The Linux disk seems to be just nulls, the Windows disks still have data in them. None of them have a valid partition table now.
On the Ceph side things don't look the same either. The Linux disk has no rbd data blocks, the Windows disks do, as confirmed by using
rbd info and rbd rados ls.All of this is in line with the backups we make with proxmox-backup-server: backups made before the revert look ok and it is possible to do a file restore from them in the GUI, but it is not possible to do a file restore from backups made after the revert.
This is Proxmox 6 with Ceph Octopus (output of pveversion -v is attached).
I'd be grateful for any hints on where to start figuring out how this could have happened!
Thanks a lot, Roel
")