Hi everyone,
I have a simple 3 node cluster that has always worked for many years and successfully passed the updates starting from proxmox 4. After updating to version 7 of proxmox and pacific ceph, the system is affected by this issue:
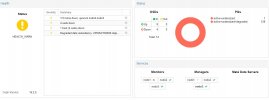
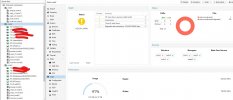
every time I reboot a node for any reason (ie updating to a new kernel) when the node is completely rebooted and ceph starts to resynch, the cluster becomes unstable and I cannot access the vms. In the gui something works and something doesn't, ie node summary always seems to go, while the ceph pannel is switching beetwen grayed out with error "mon dump down" and warning with a lot of errors. All this instability occurs during the ceph resynch phase, after this phase the system returns to 100% stable until the next node reboot. The resynch times are not that different from what I would expect, the problem is that during the system it is inaccessible and I feel scared. I have already passed 3 kernel updates and the problem is always the same. So in this moment I'm only restarting servers at night when I know that my colleagues aren't working on them.
I'm 100% sure that my hdd are good and that there is no network failure(I can always ping each cluster with ping <0.01ms ) or cpu overload
Servers are hp gen8 with an HP Ethernet 10Gb 2-port 530FLR-SFP+ Adapter for the ceph network(meshed) and a 2 of 4 ports from an HP NC365T 4-port Ethernet Server Adapter for the proxmox cluster network(meshed), so I'm not using any kind of switch for the clusters network.
I'm attaching some pics of the errors that I got.
I would really appreciate advice
I have a simple 3 node cluster that has always worked for many years and successfully passed the updates starting from proxmox 4. After updating to version 7 of proxmox and pacific ceph, the system is affected by this issue:
every time I reboot a node for any reason (ie updating to a new kernel) when the node is completely rebooted and ceph starts to resynch, the cluster becomes unstable and I cannot access the vms. In the gui something works and something doesn't, ie node summary always seems to go, while the ceph pannel is switching beetwen grayed out with error "mon dump down" and warning with a lot of errors. All this instability occurs during the ceph resynch phase, after this phase the system returns to 100% stable until the next node reboot. The resynch times are not that different from what I would expect, the problem is that during the system it is inaccessible and I feel scared. I have already passed 3 kernel updates and the problem is always the same. So in this moment I'm only restarting servers at night when I know that my colleagues aren't working on them.
I'm 100% sure that my hdd are good and that there is no network failure(I can always ping each cluster with ping <0.01ms ) or cpu overload
Servers are hp gen8 with an HP Ethernet 10Gb 2-port 530FLR-SFP+ Adapter for the ceph network(meshed) and a 2 of 4 ports from an HP NC365T 4-port Ethernet Server Adapter for the proxmox cluster network(meshed), so I'm not using any kind of switch for the clusters network.
I'm attaching some pics of the errors that I got.
I would really appreciate advice