D
Deleted member 60080
Guest
Hello,
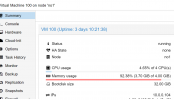
I'm kind of a noob in the proxmox shell. I just got my R710 that was going to upgrade to from my 2950 that I have had for a super long time. I installed Proxmox on my new server and created a cluster on my 2950. I was having issues connecting the two so I decided to scrap the idea and thought it would just be best to create VZdump backup files on an external hard drive. I followed this tutorial (1st reply) to delete the cluster on the 2950 (I never connected the R710 to the 2950) but when I restarted the 2950, I could no longer access the web UI. I went to the shell and typed in pvecm status but I get the error:
Cannot initialize CMAP service
When I try and start any vm using qm start, I get this error:
cluster not ready - no quorum?
When I try pvecm e 1 and then pvecm status again, I get the same cannot initialize CMAP service error.
What do you think I should do? I don't need to restore the server, I just need all of my VMs so I can put them on the new server.
I'm kind of a noob in the proxmox shell. I just got my R710 that was going to upgrade to from my 2950 that I have had for a super long time. I installed Proxmox on my new server and created a cluster on my 2950. I was having issues connecting the two so I decided to scrap the idea and thought it would just be best to create VZdump backup files on an external hard drive. I followed this tutorial (1st reply) to delete the cluster on the 2950 (I never connected the R710 to the 2950) but when I restarted the 2950, I could no longer access the web UI. I went to the shell and typed in pvecm status but I get the error:
Cannot initialize CMAP service
When I try and start any vm using qm start, I get this error:
cluster not ready - no quorum?
When I try pvecm e 1 and then pvecm status again, I get the same cannot initialize CMAP service error.
What do you think I should do? I don't need to restore the server, I just need all of my VMs so I can put them on the new server.