This morning I noticed a problem that I have seen before, but could not isolate it the first time...
1. Back-up speed randomly slowing down mid-backup
The back-up to my (remote) PBS server is starting well at 00.00 o'clock and continues doing well untill 02.43 with an average speed of 25MiB/s. After that time, the speed is only 520.5 KiB/s and the Back-up proceeds very slowly.
2. Unresponsive VM (Docker/Nextcloud)
The VM is running Docker with NextCloud on it. I can access the VM via SSH so it is not completely 'frozen'. However, at the moment, the NextCloud interface isn't working anymore because: 'Timeout of 48000ms exceeded'. This is something that never happens so this must be related to the very slow back-up at the moment.
This is the full output log of the (still running) back-up. (check the last line)
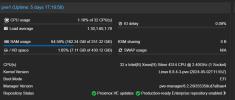
For those wondering; no, the server isn't 'overloaded' at all. (see screenshot)
1. Back-up speed randomly slowing down mid-backup
The back-up to my (remote) PBS server is starting well at 00.00 o'clock and continues doing well untill 02.43 with an average speed of 25MiB/s. After that time, the speed is only 520.5 KiB/s and the Back-up proceeds very slowly.
2. Unresponsive VM (Docker/Nextcloud)
The VM is running Docker with NextCloud on it. I can access the VM via SSH so it is not completely 'frozen'. However, at the moment, the NextCloud interface isn't working anymore because: 'Timeout of 48000ms exceeded'. This is something that never happens so this must be related to the very slow back-up at the moment.
This is the full output log of the (still running) back-up. (check the last line)
Code:
INFO: starting new backup job: vzdump --notes-template '{{guestname}}' --storage pbs1 --mailto info@domain.nl --mode snapshot --all 1 --exclude 100,101,102,205 --fleecing 0 --quiet 1 --mailnotification failure
INFO: Starting Backup of VM 210 (qemu)
INFO: Backup started at 2024-06-26 00:00:03
INFO: status = running
INFO: VM Name: Tony
INFO: include disk 'scsi0' 'tank-personal-data:210/vm-210-disk-0.qcow2' 32G
INFO: include disk 'scsi1' 'tank-personal-data:210/vm-210-disk-1.qcow2' 4T
INFO: backup mode: snapshot
INFO: ionice priority: 7
INFO: snapshots found (not included into backup)
INFO: creating Proxmox Backup Server archive 'vm/210/2024-06-25T22:00:03Z'
INFO: issuing guest-agent 'fs-freeze' command
INFO: issuing guest-agent 'fs-thaw' command
INFO: started backup task '01080f17-d6a4-4d93-8cd9-4592165b6c46'
INFO: resuming VM again
INFO: scsi0: dirty-bitmap status: OK (2.1 GiB of 32.0 GiB dirty)
INFO: scsi1: dirty-bitmap status: OK (680.6 GiB of 4.0 TiB dirty)
INFO: using fast incremental mode (dirty-bitmap), 682.7 GiB dirty of 4.0 TiB total
INFO: 0% (224.0 MiB of 682.7 GiB) in 3s, read: 74.7 MiB/s, write: 74.7 MiB/s
INFO: 1% (6.8 GiB of 682.7 GiB) in 2m 31s, read: 45.8 MiB/s, write: 42.0 MiB/s
INFO: 2% (13.7 GiB of 682.7 GiB) in 5m 13s, read: 43.7 MiB/s, write: 43.2 MiB/s
INFO: 3% (20.5 GiB of 682.7 GiB) in 7m 54s, read: 43.0 MiB/s, write: 40.0 MiB/s
INFO: 4% (27.3 GiB of 682.7 GiB) in 10m 50s, read: 39.7 MiB/s, write: 38.1 MiB/s
INFO: 5% (34.2 GiB of 682.7 GiB) in 13m 44s, read: 40.3 MiB/s, write: 35.9 MiB/s
INFO: 6% (41.0 GiB of 682.7 GiB) in 17m 18s, read: 32.7 MiB/s, write: 32.7 MiB/s
INFO: 7% (47.8 GiB of 682.7 GiB) in 20m 34s, read: 35.6 MiB/s, write: 35.5 MiB/s
INFO: 8% (54.6 GiB of 682.7 GiB) in 23m 44s, read: 36.9 MiB/s, write: 36.9 MiB/s
INFO: 9% (61.5 GiB of 682.7 GiB) in 27m 19s, read: 32.5 MiB/s, write: 32.5 MiB/s
INFO: 10% (68.3 GiB of 682.7 GiB) in 31m 48s, read: 25.9 MiB/s, write: 25.9 MiB/s
INFO: 11% (75.1 GiB of 682.7 GiB) in 36m 10s, read: 26.7 MiB/s, write: 26.7 MiB/s
INFO: 12% (81.9 GiB of 682.7 GiB) in 40m 29s, read: 26.9 MiB/s, write: 26.9 MiB/s
INFO: 13% (88.8 GiB of 682.7 GiB) in 44m 51s, read: 26.7 MiB/s, write: 26.6 MiB/s
INFO: 14% (95.6 GiB of 682.7 GiB) in 49m 8s, read: 27.2 MiB/s, write: 27.2 MiB/s
INFO: 15% (102.4 GiB of 682.7 GiB) in 53m 25s, read: 27.3 MiB/s, write: 27.3 MiB/s
INFO: 16% (109.3 GiB of 682.7 GiB) in 57m 38s, read: 27.6 MiB/s, write: 27.6 MiB/s
INFO: 17% (116.1 GiB of 682.7 GiB) in 1h 1m 41s, read: 28.8 MiB/s, write: 28.8 MiB/s
INFO: 18% (122.9 GiB of 682.7 GiB) in 1h 5m 57s, read: 27.2 MiB/s, write: 27.2 MiB/s
INFO: 19% (129.7 GiB of 682.7 GiB) in 1h 10m 37s, read: 25.0 MiB/s, write: 25.0 MiB/s
INFO: 20% (136.5 GiB of 682.7 GiB) in 1h 15m 7s, read: 25.9 MiB/s, write: 25.9 MiB/s
INFO: 21% (143.4 GiB of 682.7 GiB) in 1h 19m 47s, read: 25.0 MiB/s, write: 25.0 MiB/s
INFO: 22% (150.2 GiB of 682.7 GiB) in 1h 24m 26s, read: 25.1 MiB/s, write: 25.1 MiB/s
INFO: 23% (157.0 GiB of 682.7 GiB) in 1h 29m 5s, read: 25.1 MiB/s, write: 25.1 MiB/s
INFO: 24% (163.9 GiB of 682.7 GiB) in 1h 33m 40s, read: 25.4 MiB/s, write: 25.4 MiB/s
INFO: 25% (170.7 GiB of 682.7 GiB) in 1h 38m 15s, read: 25.5 MiB/s, write: 25.5 MiB/s
INFO: 26% (177.5 GiB of 682.7 GiB) in 1h 42m 49s, read: 25.4 MiB/s, write: 25.4 MiB/s
INFO: 27% (184.3 GiB of 682.7 GiB) in 1h 47m 23s, read: 25.6 MiB/s, write: 25.6 MiB/s
INFO: 28% (191.2 GiB of 682.7 GiB) in 1h 51m 59s, read: 25.3 MiB/s, write: 25.3 MiB/s
INFO: 29% (198.0 GiB of 682.7 GiB) in 1h 56m 34s, read: 25.4 MiB/s, write: 25.4 MiB/s
INFO: 30% (204.8 GiB of 682.7 GiB) in 2h 1m 10s, read: 25.4 MiB/s, write: 25.4 MiB/s
INFO: 31% (211.6 GiB of 682.7 GiB) in 2h 4m 52s, read: 31.4 MiB/s, write: 31.4 MiB/s
INFO: 32% (218.5 GiB of 682.7 GiB) in 2h 8m 50s, read: 29.4 MiB/s, write: 29.4 MiB/s
INFO: 33% (225.3 GiB of 682.7 GiB) in 2h 12m 38s, read: 30.8 MiB/s, write: 30.8 MiB/s
INFO: 34% (232.1 GiB of 682.7 GiB) in 2h 16m 38s, read: 29.1 MiB/s, write: 29.1 MiB/s
INFO: 35% (238.9 GiB of 682.7 GiB) in 2h 21m 4s, read: 26.2 MiB/s, write: 26.2 MiB/s
INFO: 36% (245.8 GiB of 682.7 GiB) in 2h 25m 30s, read: 26.3 MiB/s, write: 26.3 MiB/s
INFO: 37% (252.6 GiB of 682.7 GiB) in 2h 30m, read: 25.9 MiB/s, write: 25.9 MiB/s
INFO: 38% (259.4 GiB of 682.7 GiB) in 2h 34m 27s, read: 26.1 MiB/s, write: 26.1 MiB/s
INFO: 39% (266.3 GiB of 682.7 GiB) in 2h 39m 1s, read: 25.5 MiB/s, write: 25.5 MiB/s
INFO: 40% (273.1 GiB of 682.7 GiB) in 2h 43m 33s, read: 25.8 MiB/s, write: 25.7 MiB/s
INFO: 41% (279.9 GiB of 682.7 GiB) in 6h 32m 25s, read: 520.5 KiB/s, write: 504.7 KiB/sFor those wondering; no, the server isn't 'overloaded' at all. (see screenshot)
Attachments
Last edited:
")