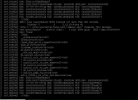
Hi there.
We have 2 Proxmox clusters. I updated packages on one cluster with no problems. Then I started updating packages on the 2nd cluster, and after I upgraded the 1st node, the whole cluster went berserk.
Initially, some of the nodes appeared up, some down, and some with a "?", even though all nodes appear operational. cluster has quorum. Some pve commands are hung on the node that I updated, reboot does not help. After a while I lost the credentials on the web interface of that node. and I cannot login. In fact, I cannot login in any of the node's web interfaces. Still, "pvecm status" claims I have quorum.
Containers start, but VMs hang on startup.
Cluster has ceph installed and running. Seems that ceph is not affected.
Cluster has 12 nodes.
any help is appreciated!
George
We have 2 Proxmox clusters. I updated packages on one cluster with no problems. Then I started updating packages on the 2nd cluster, and after I upgraded the 1st node, the whole cluster went berserk.
Initially, some of the nodes appeared up, some down, and some with a "?", even though all nodes appear operational. cluster has quorum. Some pve commands are hung on the node that I updated, reboot does not help. After a while I lost the credentials on the web interface of that node. and I cannot login. In fact, I cannot login in any of the node's web interfaces. Still, "pvecm status" claims I have quorum.
Containers start, but VMs hang on startup.
Cluster has ceph installed and running. Seems that ceph is not affected.
Cluster has 12 nodes.
any help is appreciated!
George