Hi,
I have a fresh setup of Proxmox VE 4.2-15 cluster with two nodes running, Proxmox01 and Proxmox02.
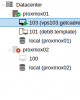
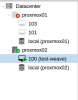
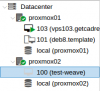
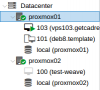
Using Proxmox01's UI as my management UI, I'm able to deploy and setup a VM on Proxmox01 with no sweat. However, I'm having an issue deploying a VM in Proxmox02 (using Proxmox01's UI). I was able to create a VM under Proxmox02 node. But, as soon as I click on the Start Proxmox02 suddenly gets offline (there's a red x icon in the name of the node from the left pane).
Looking at the corosync and pve-cluster log on Proxmox01, I noticed these bunch of messages/errors:
---------
Jul 28 03:07:50 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [status] notice: received log
Jul 28 03:07:56 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Invalid packet data
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] FAILED TO RECEIVE
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25220) was formed. Members left: 2
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Failed to receive the leave message. failed: 2
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [dcdb] notice: members: 1/109069
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [status] notice: members: 1/109069
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] This node is within the non-primary component and will NOT provide any services.
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] Members[1]: 1
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [status] notice: node lost quorum
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [MAIN ] Completed service synchronization, ready to provide service.
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25224) was formed. Members joined: 2
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Invalid packet data
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Digest does not match
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Received message has invalid digest... ignoring.
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Invalid packet data
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] FAILED TO RECEIVE
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25228) was formed. Members left: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Failed to receive the leave message. failed: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] Members[1]: 1
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [MAIN ] Completed service synchronization, ready to provide service.
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25232) was formed. Members joined: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] FAILED TO RECEIVE
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25236) was formed. Members left: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Failed to receive the leave message. failed: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] Members[1]: 1
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [MAIN ] Completed service synchronization, ready to provide service.
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25240) was formed. Members joined: 2
---------
I've alslo lost the second node looking from Proxmox01
root@proxmox01:~# pvecm status
Quorum information
------------------
Date: Thu Jul 28 02:54:29 2016
Quorum provider: corosync_votequorum
Nodes: 1
Node ID: 0x00000001
Ring ID: 25036
Quorate: No
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 1
Quorum: 2 Activity blocked
Flags:
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 10.2.4.1 (local)
It continues to fill-up the logs, until initiated a Stop on the VM via Proxmox02's management UI. By then, from Proxmox01 management UI second node (proxmox02) became on-line again. and the cluster appears to be healthy:
root@proxmox01:~# pvecm status
Quorum information
------------------
Date: Thu Jul 28 03:11:34 2016
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 0x00000001
Ring ID: 26136
Quorate: Yes
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 10.2.4.1 (local)
0x00000002 1 10.2.4.2
Right now, I'm quite puzzled what have caused this? And how can I avoid this from happening as I prefer to control/create the VMs in a single management UI (Proxmox01) without breaking the other nodes.
TIA!
Cheers,
Paulo
I have a fresh setup of Proxmox VE 4.2-15 cluster with two nodes running, Proxmox01 and Proxmox02.
Using Proxmox01's UI as my management UI, I'm able to deploy and setup a VM on Proxmox01 with no sweat. However, I'm having an issue deploying a VM in Proxmox02 (using Proxmox01's UI). I was able to create a VM under Proxmox02 node. But, as soon as I click on the Start Proxmox02 suddenly gets offline (there's a red x icon in the name of the node from the left pane).
Looking at the corosync and pve-cluster log on Proxmox01, I noticed these bunch of messages/errors:
---------
Jul 28 03:07:50 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [status] notice: received log
Jul 28 03:07:56 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Invalid packet data
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] FAILED TO RECEIVE
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25220) was formed. Members left: 2
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Failed to receive the leave message. failed: 2
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [dcdb] notice: members: 1/109069
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [status] notice: members: 1/109069
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] This node is within the non-primary component and will NOT provide any services.
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] Members[1]: 1
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com pmxcfs[109069]: [status] notice: node lost quorum
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [MAIN ] Completed service synchronization, ready to provide service.
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25224) was formed. Members joined: 2
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Invalid packet data
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Digest does not match
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Received message has invalid digest... ignoring.
Jul 28 03:07:57 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Invalid packet data
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] FAILED TO RECEIVE
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25228) was formed. Members left: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Failed to receive the leave message. failed: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] Members[1]: 1
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [MAIN ] Completed service synchronization, ready to provide service.
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25232) was formed. Members joined: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] FAILED TO RECEIVE
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25236) was formed. Members left: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] Failed to receive the leave message. failed: 2
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [QUORUM] Members[1]: 1
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [MAIN ] Completed service synchronization, ready to provide service.
Jul 28 03:07:58 proxmox01.ewr1.getcadre.com corosync[5254]: [TOTEM ] A new membership (10.2.4.1:25240) was formed. Members joined: 2
---------
I've alslo lost the second node looking from Proxmox01
root@proxmox01:~# pvecm status
Quorum information
------------------
Date: Thu Jul 28 02:54:29 2016
Quorum provider: corosync_votequorum
Nodes: 1
Node ID: 0x00000001
Ring ID: 25036
Quorate: No
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 1
Quorum: 2 Activity blocked
Flags:
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 10.2.4.1 (local)
It continues to fill-up the logs, until initiated a Stop on the VM via Proxmox02's management UI. By then, from Proxmox01 management UI second node (proxmox02) became on-line again. and the cluster appears to be healthy:
root@proxmox01:~# pvecm status
Quorum information
------------------
Date: Thu Jul 28 03:11:34 2016
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 0x00000001
Ring ID: 26136
Quorate: Yes
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 2
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000001 1 10.2.4.1 (local)
0x00000002 1 10.2.4.2
Right now, I'm quite puzzled what have caused this? And how can I avoid this from happening as I prefer to control/create the VMs in a single management UI (Proxmox01) without breaking the other nodes.
TIA!
Cheers,
Paulo