Hi all,
been running ProxMox since more or less five years, now I wanted to try my first real cluster:
I've got three Supermicro 1HE Xeon 4 drive 3.5" Server's with dualPort 10G Card's for CEPH, all just freshly reinstalled each with a SSD as their install drive and 4 Drive's in the cage. Setup went smooth so far, did the basic setup using Ansible: adding my user, his ssh-key and some additional Apps like tmux, htop and telegraf.
Then I created the cluster and on top of that setup Ceph, and as I tried to restore my first LXC, (8GB Debian CT) it took 8h to restore the 8GB... :-(
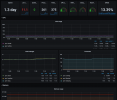
Then I had my first look on my Grafana Dashboard and realized the IOwait of up to 20%... So today I dove into it:
So the Webinterface doesn't really give a good feedback as it tends to run in 500 errors. But it all boils down to the Mon on PVE2 seems to run but doesn't make it through to the others:
And a lot of the OSD's are down...
So I'm really hoping to get some guidance here, as I don't know where to start with all that...
been running ProxMox since more or less five years, now I wanted to try my first real cluster:
I've got three Supermicro 1HE Xeon 4 drive 3.5" Server's with dualPort 10G Card's for CEPH, all just freshly reinstalled each with a SSD as their install drive and 4 Drive's in the cage. Setup went smooth so far, did the basic setup using Ansible: adding my user, his ssh-key and some additional Apps like tmux, htop and telegraf.
Then I created the cluster and on top of that setup Ceph, and as I tried to restore my first LXC, (8GB Debian CT) it took 8h to restore the 8GB... :-(
Then I had my first look on my Grafana Dashboard and realized the IOwait of up to 20%... So today I dove into it:
Code:
root@pve1|2|3:~# pveversion
pve-manager/6.4-6/be2fa32c (running kernel: 5.4.106-1-pve)So the Webinterface doesn't really give a good feedback as it tends to run in 500 errors. But it all boils down to the Mon on PVE2 seems to run but doesn't make it through to the others:
Code:
root@pve2:~# service ceph-mon@pve2 status
● ceph-mon@pve2.service - Ceph cluster monitor daemon
Loaded: loaded (/lib/systemd/system/ceph-mon@.service; enabled; vendor preset: enabled)
Drop-In: /usr/lib/systemd/system/ceph-mon@.service.d
└─ceph-after-pve-cluster.conf
Active: active (running) since Thu 2021-05-27 11:26:18 CEST; 21min ago
Main PID: 531557 (ceph-mon)
Tasks: 26
Memory: 79.9M
CGroup: /system.slice/system-ceph\x2dmon.slice/ceph-mon@pve2.service
└─531557 /usr/bin/ceph-mon -f --cluster ceph --id pve2 --setuser ceph --setgroup cep
May 27 11:26:18 pve2 systemd[1]: Started Ceph cluster monitor daemon.
Code:
root@pve1:~# ceph -s
cluster:
id: 95b97ce6-42d5-47fb-b97d-cc040dd50455
health: HEALTH_WARN
2 osds down
1 host (4 osds) down
Slow OSD heartbeats on back (longest 16716.332ms)
Slow OSD heartbeats on front (longest 17096.120ms)
Reduced data availability: 13 pgs inactive, 12 pgs down
Degraded data redundancy: 642/2223 objects degraded (28.880%), 112 pgs degraded, 113 pgs undersized
2 daemons have recently crashed
1 slow ops, oldest one blocked for 6180 sec, osd.10 has slow ops
services:
mon: 2 daemons, quorum pve1,pve3 (age 3m)
mgr: pve2(active, since 19m), standbys: pve3, pve1
osd: 12 osds: 6 up (since 97m), 8 in (since 2h); 4 remapped pgs
data:
pools: 2 pools, 129 pgs
objects: 741 objects, 2.8 GiB
usage: 12 GiB used, 5.4 TiB / 5.5 TiB avail
pgs: 10.078% pgs not active
642/2223 objects degraded (28.880%)
29/2223 objects misplaced (1.305%)
112 active+undersized+degraded
12 down
4 active+clean+remapped
1 undersized+peered
progress:
PG autoscaler decreasing pool 1 PGs from 128 to 32 (17m)
[............................]And a lot of the OSD's are down...
Code:
root@pve1:~# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 10.91638 root default
-3 3.63879 host pve1
0 ssd 0.90970 osd.0 down 1.00000 1.00000
1 ssd 0.90970 osd.1 down 0 1.00000
2 ssd 0.90970 osd.2 down 0 1.00000
3 ssd 0.90970 osd.3 down 1.00000 1.00000
-7 3.63879 host pve2
4 hdd 0.90970 osd.4 up 1.00000 1.00000
5 hdd 0.90970 osd.5 up 1.00000 1.00000
6 hdd 0.90970 osd.6 up 1.00000 1.00000
11 hdd 0.90970 osd.11 up 1.00000 1.00000
-10 3.63879 host pve3
7 hdd 0.90970 osd.7 down 0 1.00000
8 hdd 0.90970 osd.8 up 1.00000 1.00000
9 hdd 0.90970 osd.9 down 0 1.00000
10 hdd 0.90970 osd.10 up 1.00000 1.00000So I'm really hoping to get some guidance here, as I don't know where to start with all that...
Attachments
Last edited:







")
")
