Hi, as i've stated in the title i'm having some problems which i can't really pinpoint on a specific server.
The server has been off for around 10 days during summer vacations, and when i turned it back on one of the VMs didn't want to turn on.
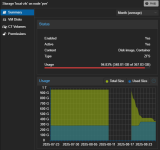
After a reboot, the incriminated vm booted without problems, but now i'm looking at the storage graph and they are shrinking
everyday, as you can see in the attached screenshots.
HDD_Backup is formatted as ext4.
This morning i found the webui unresponsive, as i couldn't log into it.
I've successfully logged via SSH, looked at journalctl, and found the following error after the scheduled backup onto HDD_Backup.
Does anyone have any idea on what to look at, or at what to try to fix this?
I guess one of the disks is failing, i can't understand if its the local-lvm (mirror with 2 SSDs) or the HDD for backups.
Thanks in advance to everybody! ^^
Have a great day
The server has been off for around 10 days during summer vacations, and when i turned it back on one of the VMs didn't want to turn on.
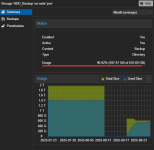
After a reboot, the incriminated vm booted without problems, but now i'm looking at the storage graph and they are shrinking
everyday, as you can see in the attached screenshots.
HDD_Backup is formatted as ext4.
This morning i found the webui unresponsive, as i couldn't log into it.
I've successfully logged via SSH, looked at journalctl, and found the following error after the scheduled backup onto HDD_Backup.
Aug 27 12:04:35 pve pve-ha-lrm[1748]: unable to write lrm status file - unable to open file '/etc/pve/nodes/pve/lrm_status.tmp.1748' - Input/output errorDoes anyone have any idea on what to look at, or at what to try to fix this?
I guess one of the disks is failing, i can't understand if its the local-lvm (mirror with 2 SSDs) or the HDD for backups.
Thanks in advance to everybody! ^^
Have a great day