Originally posted as a reply here: https://forum.proxmox.com/threads/migration-fails-pve-6-2-12-query-migrate-failed.78954/post-429694
"We're seeing this as well, though without the overflow during RAM transmission. More info further into this reply."
This problem was discovered following a cluster-of-4 upgrade wave from PVE 6.4 latest to 7.0 latest.
Upgrades went successfully however the problem has emerged since completion. Many VMs moved around before, during and after the migration without problems, however this issue that we can replicate is occurring between 2 of the 4 nodes in particular, in a single direction.
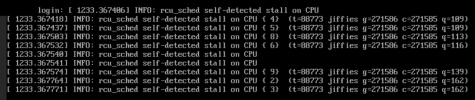
Weirdly, VMs will move between most nodes and in most directions, however in this instance the VM's SSD will move successfully and before it starts the RAM transfer the VM suddenly dies, which results in a failed live migration. To me, that smells of a kernel fault or something else similarly low-level, as the VM cannot continue.
(SSD moved successfully as part of live migration ahead of this log excerpt, with VM427 running fine as always.)
The VM was then powered down (crashed, etc) on the old host node. To clarify, this VM is ordinarily stable.
We were able to replicate the problem with another VM of different SSD/RAM sizes.
pveversion -v as below, noting that node1 had an extra older kernel that node 3 did not. Removed and thus output is now identical, problem re-verified to exist following the removal of that extra kernel version (pve-kernel-5.4.34-1-pve) (which autoremove wasn't talking about... odd).
No VM has the QEMU guest agent installed or configured, so I'd say it's not relevant here.
As for the kernel versions on the VMs, they're all patched via KernelCare. We could boot into an alternative kernel instead. OS is always RHEL-based (CloudLinux, AlmaLinux, etc), nothing older than RHEL7 family. I wouldn't have thought that the VM would have any/much insight into the migration happening in the background?
We're hunting around here, and would appreciate any pointers around what could be causing the problem. Thank you!
"We're seeing this as well, though without the overflow during RAM transmission. More info further into this reply."
This problem was discovered following a cluster-of-4 upgrade wave from PVE 6.4 latest to 7.0 latest.
Upgrades went successfully however the problem has emerged since completion. Many VMs moved around before, during and after the migration without problems, however this issue that we can replicate is occurring between 2 of the 4 nodes in particular, in a single direction.
Weirdly, VMs will move between most nodes and in most directions, however in this instance the VM's SSD will move successfully and before it starts the RAM transfer the VM suddenly dies, which results in a failed live migration. To me, that smells of a kernel fault or something else similarly low-level, as the VM cannot continue.
(SSD moved successfully as part of live migration ahead of this log excerpt, with VM427 running fine as always.)
Code:
all 'mirror' jobs are ready
2021-11-12 11:20:25 starting online/live migration on unix:/run/qemu-server/427.migrate
2021-11-12 11:20:25 set migration capabilities
2021-11-12 11:20:25 migration speed limit: 600.0 MiB/s
2021-11-12 11:20:25 migration downtime limit: 100 ms
2021-11-12 11:20:25 migration cachesize: 4.0 GiB
2021-11-12 11:20:25 set migration parameters
2021-11-12 11:20:25 start migrate command to unix:/run/qemu-server/427.migrate
query migrate failed: VM 427 not running
2021-11-12 11:20:26 query migrate failed: VM 427 not running
query migrate failed: VM 427 not running
2021-11-12 11:20:28 query migrate failed: VM 427 not running
query migrate failed: VM 427 not running
2021-11-12 11:20:30 query migrate failed: VM 427 not running
query migrate failed: VM 427 not running
2021-11-12 11:20:32 query migrate failed: VM 427 not running
query migrate failed: VM 427 not running
2021-11-12 11:20:34 query migrate failed: VM 427 not running
query migrate failed: VM 427 not running
2021-11-12 11:20:36 query migrate failed: VM 427 not running
2021-11-12 11:20:36 ERROR: online migrate failure - too many query migrate failures - aborting
2021-11-12 11:20:36 aborting phase 2 - cleanup resources
2021-11-12 11:20:36 migrate_cancel
2021-11-12 11:20:36 migrate_cancel error: VM 427 not running
drive-scsi0: Cancelling block job
2021-11-12 11:20:36 ERROR: VM 427 not running
2021-11-12 11:20:59 ERROR: migration finished with problemsThe VM was then powered down (crashed, etc) on the old host node. To clarify, this VM is ordinarily stable.
We were able to replicate the problem with another VM of different SSD/RAM sizes.
Code:
root@node1:~# qm config 427
balloon: 0
bootdisk: scsi0
cores: 5
memory: 24576
name: vm427
net0: e1000=*removed*,bridge=vmbr0,rate=200
numa: 0
ostype: l26
scsi0: local-lvm:vm-427-disk-0,backup=0,format=raw,size=500G,ssd=1
scsihw: virtio-scsi-pci
smbios1: uuid=3dcb69d6-671a-4b23-8ed4-6cfcfc85683d
sockets: 2
vmgenid: 5c7e1dbb-a9e4-4517-bb95-030748de1db1
root@node1:~#pveversion -v as below, noting that node1 had an extra older kernel that node 3 did not. Removed and thus output is now identical, problem re-verified to exist following the removal of that extra kernel version (pve-kernel-5.4.34-1-pve) (which autoremove wasn't talking about... odd).
Code:
# pveversion -v
proxmox-ve: 7.0-2 (running kernel: 5.11.22-7-pve)
pve-manager: 7.0-14+1 (running version: 7.0-14+1/08975a4c)
pve-kernel-helper: 7.1-4
pve-kernel-5.11: 7.0-10
pve-kernel-5.4: 6.4-7
pve-kernel-5.11.22-7-pve: 5.11.22-12
pve-kernel-5.4.143-1-pve: 5.4.143-1
pve-kernel-5.4.106-1-pve: 5.4.106-1
ceph-fuse: 14.2.21-1
corosync: 3.1.5-pve2
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown: residual config
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.22-pve2
libproxmox-acme-perl: 1.4.0
libproxmox-backup-qemu0: 1.2.0-1
libpve-access-control: 7.0-6
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.0-12
libpve-guest-common-perl: 4.0-2
libpve-http-server-perl: 4.0-3
libpve-storage-perl: 7.0-13
libqb0: 1.0.5-1
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 4.0.9-4
lxcfs: 4.0.8-pve2
novnc-pve: 1.2.0-3
proxmox-backup-client: 2.0.13-1
proxmox-backup-file-restore: 2.0.13-1
proxmox-mini-journalreader: 1.2-1
proxmox-widget-toolkit: 3.3-6
pve-cluster: 7.0-3
pve-container: 4.1-1
pve-docs: 7.0-5
pve-edk2-firmware: 3.20210831-1
pve-firewall: 4.2-5
pve-firmware: 3.3-3
pve-ha-manager: 3.3-1
pve-i18n: 2.5-1
pve-qemu-kvm: 6.1.0-1
pve-xtermjs: 4.12.0-1
qemu-server: 7.0-18
smartmontools: 7.2-pve2
spiceterm: 3.2-2
vncterm: 1.7-1
zfsutils-linux: 2.1.1-pve3No VM has the QEMU guest agent installed or configured, so I'd say it's not relevant here.
As for the kernel versions on the VMs, they're all patched via KernelCare. We could boot into an alternative kernel instead. OS is always RHEL-based (CloudLinux, AlmaLinux, etc), nothing older than RHEL7 family. I wouldn't have thought that the VM would have any/much insight into the migration happening in the background?
We're hunting around here, and would appreciate any pointers around what could be causing the problem. Thank you!
")