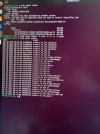
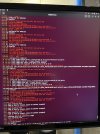
Hey so thank you ahead of time for reading this. So in my homelab I run a 3 node Proxmox and Ceph cluster with all 3 nodes each running on a 2 SSD drive ZFS mirror. About a week ago one of my nodes had a kernel panic, I'm kicking myself that I didn't take a screen shot but I rebooted and haven't been able to get it to fully boot back up.
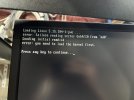
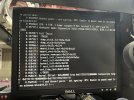
When I boot up and I choose the advance boot options for PVE I can boot from 3 different kernels. From those 3 kernels 2 of them end in a kernel panic(screenshot attached) and the last on ends with "error: failure reading sector 0xb4f20 from 'hd0'" (screenshot attached). So I started to do some troubleshooting with booting up a Live environment to see if I could import the zfs pool since it seems like that is the problem.
I tried booting from a USB with PVE using the debug console and a SystemResuce+ZFS as well as pulling the drives from the node and putting them into my Ubuntu test machine and all 3 I have not been able to import the rpool. When I use the command 'zpool import' rpool shows as online and when I use 'zpool import -R /mnt -N -f' it hangs for a bit but seems to complete. The problem is when I use 'zpool status' or 'zfs list' nothing shows up, both return " no pools available" / "no datasets available". The weird thing is that after a reboot or hot unplug/plug the pool will come back up showing as online like the import never happened.
I also ran a SMART test on both of the SSDs to see if anything turned up from that but that just showed that nothing was wrong with them besides having 3+ years of run time on them. So the only other thing I could think of to do is use the -F recovery mode flag on my 'zpool import' command but I have never used that before. So before I use that I was hoping to get some insight on possible things to try or ways to proceed?
Thanks for your time!
When I boot up and I choose the advance boot options for PVE I can boot from 3 different kernels. From those 3 kernels 2 of them end in a kernel panic(screenshot attached) and the last on ends with "error: failure reading sector 0xb4f20 from 'hd0'" (screenshot attached). So I started to do some troubleshooting with booting up a Live environment to see if I could import the zfs pool since it seems like that is the problem.
I tried booting from a USB with PVE using the debug console and a SystemResuce+ZFS as well as pulling the drives from the node and putting them into my Ubuntu test machine and all 3 I have not been able to import the rpool. When I use the command 'zpool import' rpool shows as online and when I use 'zpool import -R /mnt -N -f' it hangs for a bit but seems to complete. The problem is when I use 'zpool status' or 'zfs list' nothing shows up, both return " no pools available" / "no datasets available". The weird thing is that after a reboot or hot unplug/plug the pool will come back up showing as online like the import never happened.
I also ran a SMART test on both of the SSDs to see if anything turned up from that but that just showed that nothing was wrong with them besides having 3+ years of run time on them. So the only other thing I could think of to do is use the -F recovery mode flag on my 'zpool import' command but I have never used that before. So before I use that I was hoping to get some insight on possible things to try or ways to proceed?
Thanks for your time!
Attachments
Last edited: