Hallo liebes Forum,
ich muss mal wieder eure Hilfe in Anspruch nehmen.
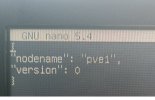
Ich habe ein Proxmox-Cluster aus derzeit 2 PVE´s.
Aktuell habe ich keine Ahnung, wo der Fehler liegt.
Ich habe smnp installiert, sonst gab es keine Veränderungen und mein PVE lief seit Monaten ohne Probleme.
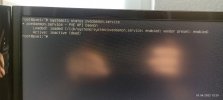
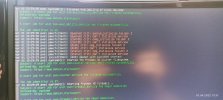
Nach dem mein Switch gestern Abend ein automatisches Update gemacht hat, war mein PVE1 samt LXC´s und VM´s nicht mehr erreichbar.
Auf die Weboberfläche bin ich auch nicht mehr gekommen. Was ich gar nicht verstehe, die Weboberfläche meines PVE2 öffnet sich, ich kann mich aber nicht mehr anmelden "Anmeldung fehlgeschlagen ...". Mit Putty kann ich mich aber am PVE2 anmelden.
Kann mir jemand einen Tipp geben?
Gruß Frank

ich muss mal wieder eure Hilfe in Anspruch nehmen.
Ich habe ein Proxmox-Cluster aus derzeit 2 PVE´s.
Aktuell habe ich keine Ahnung, wo der Fehler liegt.
Ich habe smnp installiert, sonst gab es keine Veränderungen und mein PVE lief seit Monaten ohne Probleme.
Nach dem mein Switch gestern Abend ein automatisches Update gemacht hat, war mein PVE1 samt LXC´s und VM´s nicht mehr erreichbar.
Auf die Weboberfläche bin ich auch nicht mehr gekommen. Was ich gar nicht verstehe, die Weboberfläche meines PVE2 öffnet sich, ich kann mich aber nicht mehr anmelden "Anmeldung fehlgeschlagen ...". Mit Putty kann ich mich aber am PVE2 anmelden.
Kann mir jemand einen Tipp geben?
Gruß Frank