In some nodes, it allows adding them, and I can see real-time metrics on the VMs, but I do not get the usage history, neither of the node nor of the VMs. I find this error in the logs:
Jan 16 20:56:01 datacentermanager proxmox-datacenter-api[523]: failed to collect metrics for XXXXXX: api error (status = 501 Not Implemented): Method 'GET /cluster/metrics/export' not implemented
Are your PVE-nodes up-to-date?:
hi All,
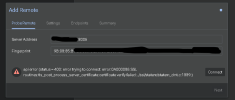
Need your help to solve the Metric didnt shown on the PVE Datacenter Manager Dasboard, and showing this syslog error.
View attachment 80075
View attachment 80073
is there any adjustment needed on my PVE node or datacenter?
View attachment 80074
As stated in the initial release post, we require up-to-date Proxmox VE remotes. The metric export API endpoint was introduced in
pve-manager 8.2.5, it seems like you are using a version older than that.Hope this helps!

")