We use the PVE8.2+CEPH hyper-converged architecture in the production environment, with a total of 8 physical nodes. These 8 physical nodes use exactly the same hardware configuration. THE SERVER MODEL IS DELL R750
However, in the past six months or so, there has been a physical node crash, and the frequency of crashes is irregular, sometimes for more than ten hours, sometimes for a day, sometimes even for days or a month. However, there are no hardware alarms under IDRAC. We contacted DELL engineers to troubleshoot the hardware issue and told us that there were no hardware issues. So we started with software. After the faulty host is removed from the cluster, the PVE host is rebuilt and added to the cluster. But a few days later, it started to freeze again, and this solution did not solve the problem. The cluster is also connected to Huawei's FC SAN storage, and only the faulty node cannot be powered on and automatically connected to the FC SAN. At this time, we replaced the FC HBA card, and the problem of not being able to automatically connect to the storage after the replacement was completed, and the second and third days after the replacement were completed, and there were crashes on the second and third days, respectively. This was followed by no crashes for 1 month. But we recently replaced a new R750 server, but because the CPU of the new machine failed, we used the old CPU to install on the new server, but the next day it crashed again. So how do I troubleshoot my freeze issue?
Description of the crash: It is a network outage, pressing the enter key under the monitor does not respond, and the server must be restarted to restore the system and network
I'm sorry, I'm from China, I'm using Microsoft Translator to communicate with you, please understand. I'll attach some screenshots of the glitch
But since the fault screenshot may not be complete, I will attach a screenshot of the time when the new machine encounters a crash
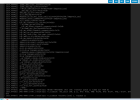
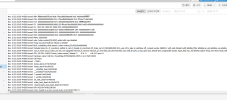
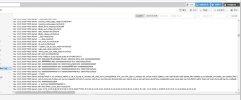
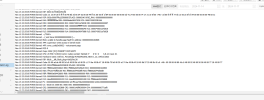
I uploaded the system log of the most recent crash attached to it
However, in the past six months or so, there has been a physical node crash, and the frequency of crashes is irregular, sometimes for more than ten hours, sometimes for a day, sometimes even for days or a month. However, there are no hardware alarms under IDRAC. We contacted DELL engineers to troubleshoot the hardware issue and told us that there were no hardware issues. So we started with software. After the faulty host is removed from the cluster, the PVE host is rebuilt and added to the cluster. But a few days later, it started to freeze again, and this solution did not solve the problem. The cluster is also connected to Huawei's FC SAN storage, and only the faulty node cannot be powered on and automatically connected to the FC SAN. At this time, we replaced the FC HBA card, and the problem of not being able to automatically connect to the storage after the replacement was completed, and the second and third days after the replacement were completed, and there were crashes on the second and third days, respectively. This was followed by no crashes for 1 month. But we recently replaced a new R750 server, but because the CPU of the new machine failed, we used the old CPU to install on the new server, but the next day it crashed again. So how do I troubleshoot my freeze issue?
Description of the crash: It is a network outage, pressing the enter key under the monitor does not respond, and the server must be restarted to restore the system and network
I'm sorry, I'm from China, I'm using Microsoft Translator to communicate with you, please understand. I'll attach some screenshots of the glitch
But since the fault screenshot may not be complete, I will attach a screenshot of the time when the new machine encounters a crash
I uploaded the system log of the most recent crash attached to it