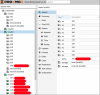
Hi,
suddenly one node in my Proxmox 5.1 cluster becomes unavailable into the web interface and it's icon becomes grey with a question mark, like in the following screenshots:

This happened three times on three different nodes (on node01 and node02, I rebooted them to solve the problem).
All virtual machines on the node are running good, and the web interface on the failed node is reachable, but it shows the same (if I connect to the node03 web interface all nodes are green except itself).
All nodes are correctly pingable from node03.
In the datacenter summary all 11 nodes are Online.
I don't see any error in /var/log/syslog on node03.
The call to the status API (https://node1:8006/api2/json/cluster/status) returns all nodes online but node03 is marked as local cand has "level":null instead of "level":"":
This is the pvecm status output from node03:
All nodes are updated to the last version of Proxmox, the last version of the kernel (I updated all packages yesterday):
Could you help me please?
Thanks!
suddenly one node in my Proxmox 5.1 cluster becomes unavailable into the web interface and it's icon becomes grey with a question mark, like in the following screenshots:
This happened three times on three different nodes (on node01 and node02, I rebooted them to solve the problem).
All virtual machines on the node are running good, and the web interface on the failed node is reachable, but it shows the same (if I connect to the node03 web interface all nodes are green except itself).
All nodes are correctly pingable from node03.
In the datacenter summary all 11 nodes are Online.
I don't see any error in /var/log/syslog on node03.
The call to the status API (https://node1:8006/api2/json/cluster/status) returns all nodes online but node03 is marked as local cand has "level":null instead of "level":"":
Code:
{"data":[{"nodes":11,"id":"cluster","type":"cluster","name":"mycluster","version":11,"quorate":1},
{"nodeid":6,"id":"node/node10","local":0,"name":"node10","online":1,"ip":"192.168.60.10","level":"","type":"node"},
{"ip":"192.168.60.2","level":"","type":"node","nodeid":10,"id":"node/node02","local":0,"name":"node02","online":1},
{"ip":"192.168.60.11","level":"","type":"node","nodeid":2,"id":"node/node11","local":0,"name":"node11","online":1},
{"ip":"192.168.60.3","level":null,"type":"node","nodeid":7,"id":"node/node03","local":0,"name":"node03","online":1},
{"online":1,"nodeid":8,"id":"node/node01","name":"node01","local":1,"ip":"192.168.60.1","level":"","type":"node"},
{"name":"node09","local":0,"nodeid":11,"id":"node/node09","online":1,"type":"node","level":"","ip":"192.168.60.9"},
{"level":"","type":"node","ip":"192.168.60.5","id":"node/node05","nodeid":1,"local":0,"name":"node05","online":1},
{"ip":"192.168.60.6","level":"","type":"node","id":"node/node06","nodeid":3,"name":"node06","local":0,"online":1},
{"ip":"192.168.60.8","type":"node","level":"","online":1,"local":0,"name":"node08","id":"node/node08","nodeid":5},
{"level":"","type":"node","ip":"192.168.60.4","nodeid":9,"id":"node/node04","local":0,"name":"node04","online":1},
{"ip":"192.168.60.7","type":"node","level":"","name":"node07","local":0,"id":"node/node07","nodeid":4,"online":1}]}This is the pvecm status output from node03:
Code:
root@node03:~# pvecm status
Quorum information
------------------
Date: Mon Feb 5 10:09:54 2018
Quorum provider: corosync_votequorum
Nodes: 11
Node ID: 0x00000007
Ring ID: 8/1256
Quorate: Yes
Votequorum information
----------------------
Expected votes: 11
Highest expected: 11
Total votes: 11
Quorum: 6
Flags: Quorate
Membership information
----------------------
Nodeid Votes Name
0x00000008 1 192.168.60.1
0x0000000a 1 192.168.60.2
0x00000007 1 192.168.60.3 (local)
0x00000009 1 192.168.60.4
0x00000001 1 192.168.60.5
0x00000003 1 192.168.60.6
0x00000004 1 192.168.60.7
0x00000005 1 192.168.60.8
0x0000000b 1 192.168.60.9
0x00000006 1 192.168.60.10
0x00000002 1 192.168.60.11All nodes are updated to the last version of Proxmox, the last version of the kernel (I updated all packages yesterday):
Code:
root@node03:~# pveversion -v
proxmox-ve: 5.1-38 (running kernel: 4.13.13-5-pve)
pve-manager: 5.1-43 (running version: 5.1-43/bdb08029)
pve-kernel-4.13.4-1-pve: 4.13.4-26
pve-kernel-4.13.13-2-pve: 4.13.13-33
pve-kernel-4.13.13-5-pve: 4.13.13-38
pve-kernel-4.13.13-3-pve: 4.13.13-34
libpve-http-server-perl: 2.0-8
lvm2: 2.02.168-pve6
corosync: 2.4.2-pve3
libqb0: 1.0.1-1
pve-cluster: 5.0-19
qemu-server: 5.0-20
pve-firmware: 2.0-3
libpve-common-perl: 5.0-25
libpve-guest-common-perl: 2.0-14
libpve-access-control: 5.0-7
libpve-storage-perl: 5.0-17
pve-libspice-server1: 0.12.8-3
vncterm: 1.5-3
pve-docs: 5.1-16
pve-qemu-kvm: 2.9.1-6
pve-container: 2.0-18
pve-firewall: 3.0-5
pve-ha-manager: 2.0-4
ksm-control-daemon: 1.2-2
glusterfs-client: 3.8.8-1
lxc-pve: 2.1.1-2
lxcfs: 2.0.8-1
criu: 2.11.1-1~bpo90
novnc-pve: 0.6-4
smartmontools: 6.5+svn4324-1
zfsutils-linux: 0.7.4-pve2~bpo9Could you help me please?
Thanks!
Last edited: