2022-08-22T11:01:16+01:00: verify group storage_cold:vm/141 (18 snapshots)
2022-08-22T11:01:16+01:00: verify storage_cold:vm/141/2022-08-22T09:26:40Z
2022-08-22T11:01:16+01:00: check qemu-server.conf.blob
2022-08-22T11:01:16+01:00: check drive-tpmstate0-backup.img.fidx
2022-08-22T11:01:16+01:00: verified 0.00/4.00 MiB in 0.03 seconds, speed 0.15/149.22 MiB/s (0 errors)
2022-08-22T11:01:16+01:00: check drive-scsi0.img.fidx
2022-08-22T11:02:54+01:00: verified 7490.60/15424.00 MiB in 97.77 seconds, speed 76.62/157.77 MiB/s (0 errors)
2022-08-22T11:02:54+01:00: check drive-efidisk0.img.fidx
2022-08-22T11:02:54+01:00: verified 0.01/0.52 MiB in 0.01 seconds, speed 0.59/36.35 MiB/s (0 errors)
2022-08-22T11:02:54+01:00: percentage done: 5.56% (1/18 snapshots)
2022-08-22T11:02:54+01:00: verify storage_cold:vm/141/2022-08-21T21:03:31Z
2022-08-22T11:02:54+01:00: check qemu-server.conf.blob
2022-08-22T11:02:54+01:00: check drive-tpmstate0-backup.img.fidx
2022-08-22T11:02:54+01:00: verified 0.00/4.00 MiB in 0.03 seconds, speed 0.13/128.11 MiB/s (0 errors)
2022-08-22T11:02:54+01:00: check drive-scsi0.img.fidx
2022-08-22T11:02:55+01:00: verified 53.92/176.00 MiB in 1.00 seconds, speed 54.06/176.45 MiB/s (0 errors)
2022-08-22T11:02:55+01:00: check drive-efidisk0.img.fidx
2022-08-22T11:02:55+01:00: verified 0.01/0.52 MiB in 0.01 seconds, speed 0.59/36.63 MiB/s (0 errors)
2022-08-22T11:02:55+01:00: percentage done: 11.11% (2/18 snapshots)
2022-08-22T11:02:55+01:00: verify storage_cold:vm/141/2022-08-20T21:42:21Z
2022-08-22T11:02:55+01:00: check qemu-server.conf.blob
2022-08-22T11:02:55+01:00: check drive-tpmstate0-backup.img.fidx
2022-08-22T11:02:55+01:00: verified 0.00/4.00 MiB in 0.03 seconds, speed 0.13/130.42 MiB/s (0 errors)
2022-08-22T11:02:55+01:00: check drive-scsi0.img.fidx
2022-08-22T11:02:57+01:00: verified 59.05/180.00 MiB in 1.31 seconds, speed 45.07/137.37 MiB/s (0 errors)
2022-08-22T11:02:57+01:00: check drive-efidisk0.img.fidx
2022-08-22T11:02:57+01:00: verified 0.01/0.52 MiB in 0.01 seconds, speed 0.88/54.24 MiB/s (0 errors)
2022-08-22T11:02:57+01:00: percentage done: 16.67% (3/18 snapshots)
2022-08-22T11:02:57+01:00: verify storage_cold:vm/141/2022-08-19T09:20:50Z
2022-08-22T11:02:57+01:00: check qemu-server.conf.blob
2022-08-22T11:02:57+01:00: check drive-tpmstate0-backup.img.fidx
2022-08-22T11:02:57+01:00: verified 0.00/4.00 MiB in 0.03 seconds, speed 0.12/120.28 MiB/s (0 errors)
2022-08-22T11:02:57+01:00: check drive-scsi0.img.fidx
2022-08-22T11:02:59+01:00: verified 144.74/392.00 MiB in 2.36 seconds, speed 61.24/165.85 MiB/s (0 errors)
2022-08-22T11:02:59+01:00: check drive-efidisk0.img.fidx
2022-08-22T11:02:59+01:00: verified 0.01/0.52 MiB in 0.01 seconds, speed 1.43/88.06 MiB/s (0 errors)
2022-08-22T11:02:59+01:00: percentage done: 22.22% (4/18 snapshots)
2022-08-22T11:02:59+01:00: verify storage_cold:vm/141/2022-08-18T12:08:21Z
2022-08-22T11:02:59+01:00: check qemu-server.conf.blob
2022-08-22T11:02:59+01:00: check drive-tpmstate0-backup.img.fidx
2022-08-22T11:02:59+01:00: verified 0.00/4.00 MiB in 0.03 seconds, speed 0.14/136.33 MiB/s (0 errors)
2022-08-22T11:02:59+01:00: check drive-scsi0.img.fidx
2022-08-22T11:03:02+01:00: verified 172.81/488.00 MiB in 3.15 seconds, speed 54.79/154.73 MiB/s (0 errors)
2022-08-22T11:03:02+01:00: check drive-efidisk0.img.fidx
2022-08-22T11:03:02+01:00: verified 0.01/0.52 MiB in 0.01 seconds, speed 1.20/74.41 MiB/s (0 errors)
2022-08-22T11:03:02+01:00: percentage done: 27.78% (5/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-18T09:27:18Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 33.33% (6/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-17T09:53:02Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 38.89% (7/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-16T22:45:00Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 44.44% (8/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-16T22:38:48Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 50.00% (9/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-16T22:32:59Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 55.56% (10/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-11T01:24:22Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 61.11% (11/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-10T11:43:05Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 66.67% (12/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-10T09:18:58Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 72.22% (13/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-09T22:09:12Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 77.78% (14/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-09T09:26:16Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 83.33% (15/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-08T12:14:00Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 88.89% (16/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-08T10:51:57Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 94.44% (17/18 snapshots)
2022-08-22T11:03:02+01:00: SKIPPED: verify storage_cold:vm/141/2022-08-08T10:20:26Z (recently verified)
2022-08-22T11:03:02+01:00: percentage done: 100.00% (18/18 snapshots)
2022-08-22T11:03:02+01:00: TASK OK
 ).
).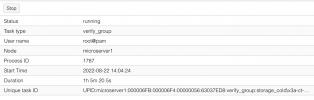
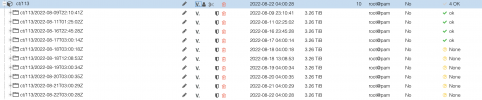
") chunks are only skipped if they have already been verified as part of the same verification task (so if you verify a group, all the "shared" chunks are only verified once when they are first encountered, and not for each snapshot that shares it). snapshots are skipped based on the criteria you give. there is no way to say "only verify new chunks", as verification status is on the snapshot level, not chunk level (we can't say the new snapshot is verified if we only check 1% of its chunks - that would be misleading!).
chunks are only skipped if they have already been verified as part of the same verification task (so if you verify a group, all the "shared" chunks are only verified once when they are first encountered, and not for each snapshot that shares it). snapshots are skipped based on the criteria you give. there is no way to say "only verify new chunks", as verification status is on the snapshot level, not chunk level (we can't say the new snapshot is verified if we only check 1% of its chunks - that would be misleading!).")