My network has some issues. When the network traffic increases, the network connections tend to be very slow even though it's an 10GB network. I'm not sure whether it's proxmox-related or not.
Example:
VMx = virtual machine x
VHx = proxmox virtual host x
VM1 = 192.168.0.51 (E2:A9:CC:75:79:AF) - on VH1
VM2 = 192.168.0.8 (8A:1D:1B:44:64:A7) - on VH2
VM3 & VM4 = different ip's and mac-adresses (same subnet/vlan) - on VH3
- There's traffic between VM1 (VH1) and VM2 (VH2) (HTTP) - this is normal and always the case
- Some traffic is (also?) being delivered to i.e. VM3, VM4 (VH3) - this seems to me as very strange (not always, more machines are involved)
I've set up an Proxmox-firewall on VM3 and VM4 and based on this. I also enabled mac/ip-firewall-filters. I can see this happening:
(i changed the networkadapters-vm-numbers in the logs to be consistent with my example)
Based on this, my first question is:
Q1. After this package arrives at VH2 (even though it shouldn't be here): is it normal that these packages are being delivered to VM3 and VM4 even though the MAC-addresses/IP's don't correspond with those vm's?
I guess this could be normal behavior because the virtual host can't find the mac-address locally because it's not on the node (it resides on another node).
I've already checked:
- the arp-cache on all proxmox nodes doesn't seem to include any vm's (= normal/default?).
- tap3i0-interface seems to be in promisc-mode (= normal/default?), the fwpr3i0, fwln3i0, fwbr3i0 devices are not in promisc (= normal/default?).
--
Q2. I guess the bigger problem is: the network traffic should have never entered VH3. Is should be traffic between VH1 and VH2. How could it have gone to VH3?
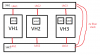
I've connected all proxmox nodes using LACP (active+active) to 2 cisco-switches, that are connected in stack using 2 fiber connections. See simplified diagram in attachment. The relevant network is all in the same subnet/vlan.
My guess is that there must be going something wrong on the switch, because the switch should have already seen the traffic has an destination on VH2 and not VH3.
I think that should work based on ARP, but the ARP table on the switch seems to be correct (the mac's are pointing to the right lacp-connections/LAG's). So I don't know why the packages are being delivered wrong.
Example:
VMx = virtual machine x
VHx = proxmox virtual host x
VM1 = 192.168.0.51 (E2:A9:CC:75:79:AF) - on VH1
VM2 = 192.168.0.8 (8A:1D:1B:44:64:A7) - on VH2
VM3 & VM4 = different ip's and mac-adresses (same subnet/vlan) - on VH3
- There's traffic between VM1 (VH1) and VM2 (VH2) (HTTP) - this is normal and always the case
- Some traffic is (also?) being delivered to i.e. VM3, VM4 (VH3) - this seems to me as very strange (not always, more machines are involved)
I've set up an Proxmox-firewall on VM3 and VM4 and based on this. I also enabled mac/ip-firewall-filters. I can see this happening:
Code:
120 4 tap120i0-IN 29/Jun/2020:08:56:48 +0200 policy REJECT: IN=fwbr3i0 OUT=fwbr3i0 PHYSIN=fwln3i0 PHYSOUT=tap3i0 MAC=8a:1d:1b:44:64:a7:e2:a9:cc:75:79:af:08:00 SRC=192.168.0.51 DST=192.168.0.8 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=14385 DF PROTO=TCP SPT=36186 DPT=80 SEQ=980641566 ACK=0 WINDOW=29200 SYN
130 4 tap130i0-IN 29/Jun/2020:08:56:48 +0200 policy REJECT: IN=fwbr4i0 OUT=fwbr4i0 PHYSIN=fwln4i0 PHYSOUT=tap4i0 MAC=8a:1d:1b:44:64:a7:e2:a9:cc:75:79:af:08:00 SRC=192.168.0.51 DST=192.168.0.8 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=14385 DF PROTO=TCP SPT=36186 DPT=80 SEQ=980641566 ACK=0 WINDOW=29200 SYNBased on this, my first question is:
Q1. After this package arrives at VH2 (even though it shouldn't be here): is it normal that these packages are being delivered to VM3 and VM4 even though the MAC-addresses/IP's don't correspond with those vm's?
I guess this could be normal behavior because the virtual host can't find the mac-address locally because it's not on the node (it resides on another node).
I've already checked:
- the arp-cache on all proxmox nodes doesn't seem to include any vm's (= normal/default?).
- tap3i0-interface seems to be in promisc-mode (= normal/default?), the fwpr3i0, fwln3i0, fwbr3i0 devices are not in promisc (= normal/default?).
--
Q2. I guess the bigger problem is: the network traffic should have never entered VH3. Is should be traffic between VH1 and VH2. How could it have gone to VH3?
I've connected all proxmox nodes using LACP (active+active) to 2 cisco-switches, that are connected in stack using 2 fiber connections. See simplified diagram in attachment. The relevant network is all in the same subnet/vlan.
My guess is that there must be going something wrong on the switch, because the switch should have already seen the traffic has an destination on VH2 and not VH3.
I think that should work based on ARP, but the ARP table on the switch seems to be correct (the mac's are pointing to the right lacp-connections/LAG's). So I don't know why the packages are being delivered wrong.
Attachments
Last edited:


") )
)