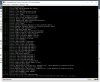
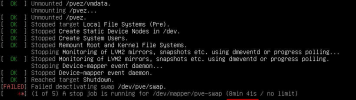
Hi to all,
in a 3 node ceph cluster buit on 3 identical hp gen8 dl360p servers, I'm always receiving the error attached everytime I'm rebooting a node. Before rebooting the node I always move all the vms to another node, so when I press reboot there is no running VM. To fix this I have to force an hardware restart, cause after 30 minutes it still stucks on this error.
Is there a way to fix this? many thanks
**edit: the error happens with all those HPs servers but in the same cluster I have another node without ceph, only for utility stuffs, and this will reboot without problems.
in a 3 node ceph cluster buit on 3 identical hp gen8 dl360p servers, I'm always receiving the error attached everytime I'm rebooting a node. Before rebooting the node I always move all the vms to another node, so when I press reboot there is no running VM. To fix this I have to force an hardware restart, cause after 30 minutes it still stucks on this error.
Is there a way to fix this? many thanks
**edit: the error happens with all those HPs servers but in the same cluster I have another node without ceph, only for utility stuffs, and this will reboot without problems.