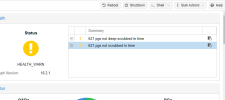
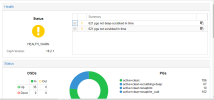
We’ve been receiving warnings about 621 PGs not being deep-scrubbed and 621 PGs not being scrubbed in time for a while now, and the issue doesn't seem to be resolving. Is there a command that can address this problem? There are over 600 PGs showing this error—will manually scrubbing each PG resolve the issue?
Thank you
Thank you

") I'm gonna go out on a limb and say that wasnt the cause of the issues you observed.
I'm gonna go out on a limb and say that wasnt the cause of the issues you observed.