That is very strange, I don't see any cpu usage at all on any of my CPUs and if I test a VM with 8 CPUs vs. PVE host it is running on with 32 is no noticeable difference. I'm not testing the TLS, it is limited by the network speed to PBS, yet everything else stays (also) the same. I would have suspected that it would scale somehow.My PBS running in a container on PVE (Ryzen 5950X) gives for TLS 348 MB/s (28%) with 1 core, 726 MB/s (59%) with 2 cores and 839 MB/s (68%) with 3 cores or more. I guess there is some parallelization going on.
Abysmally slow restore from backup
- Thread starter damarrin
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.

Hello @fabian and thank you for responding.
I only now have time to read through and will try to reply to your messages. It's going to be longish, I appologize in advance.
- LACP will never utilize more than a single link capacity, because there's only one connection / one stream of data going on
- congested links (think offsite backups) backup traffic will end up worse when competing for bandwidth with other traffic, then it would end up in case there were more connections in parallel instead of just 1
- also, server network hardware and drivers may as well benefit from multiple TCP streams, as then it could handle them by multiple CPU-s
All of these points matter (and there are possibly other points I did not identify) and none of them can't benefit because of this choice that was made - to always use only 1 TCP connection for backup traffic. You can't ignore all of these other points and pretend there's a problem only a high latency links.
On "Why your TLS benchmark speed is so low I cannot say - it might be that your CPU just can't handle the throughput for the chosen cipher/crypto?" I also don't know why it's slow. I can only tell you that what I have observed and that is: my CPU has free cycles. And that clearly means there is room for improvement. Because if my CPUs are not all 100% utilized, what that means is that PBS is not using all the available hardware. But it should. Or, we'd love that it does. Because then things would run faster - and that's the goal, right ? So, it doesn't matter what CPU type I have and how old it is. If it's idling, then it's not the "CPU-s age" that is at fault, it's the solution can't utilize the CPU fully. Yes it will run better on a better CPU, what doesn't, but that's no solution - it can also run faster on a newer CPU if software was using the CPU potential better.
CPU age is not a valid answer for poor performance. With some exceptions around instructions, if the CPU doesn't support them, but that doesn't apply here - and it shouldn't apply if CPU is not fully utilized in any case.
If you are aiming for "this way we can guarantee that no bad actor changed the contents of the file" I am willing to argue against that. When someone has access to files in your backup datastore you are more or less doomed at that point already, how does crypto hash help ? Trying to protect against intentional modification of protected data at rest, with crypto hashes, is... very debatable, at a minimum. Especially when/if it causes high costs (in newer servers and CPU power) for a user. Yes, SHA means that someone with access to chunks will have a harder time making files corrupt while retaining the hash, then with a non cryptographic checksum. But don't tell me that's the reason...
I know the benefits though: speed of calculation is orders of magnitude higher than SHA. Therefore I actually think it's very valid for this application, if not perfect. You say it is not - so, please explain what is the reason behind SHA-256 as I must be missing something.
Even if we don't agree on this, I think users should still have a choice to decide on their own. "I'll use the less secure hash because it's 50x faster" is something I might choose to do, given my level of trust in other protections I put in place of my backup machines - and based on my own risk evaluation. We should all do test restores anyway (that includes starting the VM/CT) as best practice, right ? so... what exactly are we loosing with a fast non-crypto hasher ? what is so important that you won't even consider a non-crypto hash in this case - I wish to know. Sorry I'm an engineer, so dogma is not an answer I can work with.
With backward compatibility I mean: newer PBS version will be able to read and work with a datastore that was used with previous versions - not vice versa, obviously. But that's ok, that's pretty standard behavior. In a case where newer client created a chunk and an older client then tries to restore it - that wouldn't work, true. But you could configure the system NOT to use the new format by default, so one has to turn it on consciously - maybe even make a new datastore, if you wish, to unlock the new features. Then, make sure older clients can't use the new datastore and you're set. Nothing breaks then. In my opinion at least, that's not prohibitively complicated.
I might also note that you will hardy find "something that offers substantial improvements" if you don't agree to try anything. I think this would offer substantial improvements. With this being:
- xxHash for checksums
- multiple TCP streams (they can remain HTTP/2 connections if you wish, just use more of them in parallel)
- an option to disable TLS for transfer (it doesn't have to be complex, just use another port for non-TLS API access and put a listener without TLS there; later you could block API routes and selectively leave only those for chunk transfer accessible on non-TLS API, but for testing... it shouldn't at all be complicated to bring up a non-TLS API endpoint)
Try it. Then tell me if it qualifies as substantial improvement - or not. Test on some older lab hardware as well.
Let's not argue about NVMe vs HDD speeds in general, we all agree on that. But when doing PBS restore - in my testing - there was no significant difference between the two. Therefore the bottleneck must be somewhere else:
- Network ? - 10 Gbps (alas, in second try it was 10 Gbps)
- CPU ? - not fully utilized
- Disks ? - might be the reason... let's try with enterprise NVMe hardware -> same result
And that's why I (re)opened this whole topic.
Once you see what I've seen, explained above, you then go to the forums and communicate that. Because it's not normal for software not to utilize hardware fully (or... it is quite normal unfortunately, but that's another topic). PVE being quite performant even on older machines, Linux-based, OSS inspired and all - I thought I won't have to explain to anyone that - software that is not utilizing the full hardware potential might be seen as something you'd actually want to look into, not try to reject.
I otherwise agree with you, that I can't tell for sure where the problem lies. In past experience it turned out I do have a good nose for this stuff. My nose is currently sniffing about: hashing, TLS and single-connection transfer. In a couple of years perhaps you can tell me how far off I was. At this point - neither of us knows. Right now I'm just sniffing and giving my advice. And you're... trying to find ways to reject it, more or less, it would seem.
")
But that's not the point, anyway, something else is. Just because things seem difficult at first doesn't mean they actually are difficult to implement, and above all, it absolutely doesn't mean we shouldn't dig there. Quite the opposite. In my company we dig a lot. My team always hates the idea - initially. Always. Then they are super happy a couple of days later about how they solved the big complex issue. It's not always like that, of course, but I can confidently say that more than 50% of time I get the "are you crazy, this will take us 6 months, no chance", then usually the same night I receive tons of messages from one of developers, who then also finishes the change either the same night or within a few days in total euphoria with "this is great, this will work awesomely now" and everyone else suddenly agreeing. Same people that were 100% against even thinking about touching it, just 2 days before, are in epiphany. Just saying... Most of the time things look much more difficult then they actually are. And thinking in advance it's complex, difficult and spreading such information around - it blocks developers from even considering changes in code. And then there's laziness that helps a lot to quickly agree on the point. That's actually the biggest single thing that stops progress in existing code. Don't think that way, don't say it until you know for sure what it actually takes to make the change. Also I know which things are complex, which are not. Implementing another hash shouldn't be that complex -> after a developer is allowed to dig a bit in to the code and see what actually needs to be done. That should be before he is given assumptions, before thinking "it's more complicated than it looks". Because actually, in most occasions, it's not that complicated after all.
And as we know the CPU is not fully utilized I can actually put this here: the CPU is not the bottleneck, so let's move away from that assumption.
I understand that some part of processing might be single core bound (although, by monitoring CPU usage, I'm not seeing that here) - hence, the CPU was the bottleneck, you see, I told you. But in that case we should investigate ways to enable processing to utilize multiple cores. That might be achievable without changing much code (not saying it is). But the mere "your CPU is actually rather old", while at the same time my CPU is wasting cycles, well... That's maybe fine answer for an end customer looking for a quick solution - now. Go buy new hardware and try. Fine. But for an engineer, a developer, someone who's trying to make software perform better with hardware that is at it's disposal ? Not a valid answer. The CPU is not hitting the roof, so... let's try to find the cause and let's see how we can make better usage of the CPU.
For that: we need to identify where most time is spent during processing and what is waiting for what. Here, profiling the process, measuring different parts, etc is needed. This is where developers would need to jump in.
Or we can "blindly" (trusting my nose) try something to see if it helps.
I could test with another TLS benchmark just to make sure the numbers agree. The way you describe it it seems a web server with TLS configured and me trying to download a file from it - should get me roughly the same result in terms of GBps. I'll try to test when I have time and report back. This is just to discard the TLS implementation itself as a potential issue (I don't expect to find an issue, this is just to be thorough).
There are still potential gains with faster hashing and without TLS, if you would be willing to try with such code.
Kind regards
(edited some typpos and grammar mistakes to make text easier to read)
I only now have time to read through and will try to reply to your messages. It's going to be longish, I appologize in advance.
You are only viewing this from a single perspective problem, that of higher latency links, even though I already gave you some other examples previously. Let me repeat them here:HTTP/2 as only transport mechanism for the backup and reader sessions is not set in stone. But any replacement/additional transport must have clear benefits without blowing up code complexity. We are aware that HTTP/2 performs (a lot) worse over higher latency connections, because in order to handle multiple streams over a single connection, round trips to handle stream capacity are needed. Why your TLS benchmark speed is so low I cannot say - it might be that your CPU just can't handle the throughput for the chosen cipher/crypto?
- LACP will never utilize more than a single link capacity, because there's only one connection / one stream of data going on
- congested links (think offsite backups) backup traffic will end up worse when competing for bandwidth with other traffic, then it would end up in case there were more connections in parallel instead of just 1
- also, server network hardware and drivers may as well benefit from multiple TCP streams, as then it could handle them by multiple CPU-s
All of these points matter (and there are possibly other points I did not identify) and none of them can't benefit because of this choice that was made - to always use only 1 TCP connection for backup traffic. You can't ignore all of these other points and pretend there's a problem only a high latency links.
On "Why your TLS benchmark speed is so low I cannot say - it might be that your CPU just can't handle the throughput for the chosen cipher/crypto?" I also don't know why it's slow. I can only tell you that what I have observed and that is: my CPU has free cycles. And that clearly means there is room for improvement. Because if my CPUs are not all 100% utilized, what that means is that PBS is not using all the available hardware. But it should. Or, we'd love that it does. Because then things would run faster - and that's the goal, right ? So, it doesn't matter what CPU type I have and how old it is. If it's idling, then it's not the "CPU-s age" that is at fault, it's the solution can't utilize the CPU fully. Yes it will run better on a better CPU, what doesn't, but that's no solution - it can also run faster on a newer CPU if software was using the CPU potential better.
CPU age is not a valid answer for poor performance. With some exceptions around instructions, if the CPU doesn't support them, but that doesn't apply here - and it shouldn't apply if CPU is not fully utilized in any case.
Could you elaborate more on this please ? What else are you protecting ?xxHash is not a valid choice for this application - we do actually really need a cryptographic hash, because the digest is not just there to protect against bit rot.
If you are aiming for "this way we can guarantee that no bad actor changed the contents of the file" I am willing to argue against that. When someone has access to files in your backup datastore you are more or less doomed at that point already, how does crypto hash help ? Trying to protect against intentional modification of protected data at rest, with crypto hashes, is... very debatable, at a minimum. Especially when/if it causes high costs (in newer servers and CPU power) for a user. Yes, SHA means that someone with access to chunks will have a harder time making files corrupt while retaining the hash, then with a non cryptographic checksum. But don't tell me that's the reason...
I know the benefits though: speed of calculation is orders of magnitude higher than SHA. Therefore I actually think it's very valid for this application, if not perfect. You say it is not - so, please explain what is the reason behind SHA-256 as I must be missing something.
Even if we don't agree on this, I think users should still have a choice to decide on their own. "I'll use the less secure hash because it's 50x faster" is something I might choose to do, given my level of trust in other protections I put in place of my backup machines - and based on my own risk evaluation. We should all do test restores anyway (that includes starting the VM/CT) as best practice, right ? so... what exactly are we loosing with a fast non-crypto hasher ? what is so important that you won't even consider a non-crypto hash in this case - I wish to know. Sorry I'm an engineer, so dogma is not an answer I can work with.
No, it doesn't need to break existing clients or servers. I even noted in my previous post an example of how this could be achieved. Without looking at the code, really, but there are many ways how backward compatibility can be retained when introducing a new feature (in this case a new hash or compression algorithm for chunks).Compression or checksum algorithms changes mean breaking existing clients (and servers), so those will only happen if we find something that offers substantial improvements.
With backward compatibility I mean: newer PBS version will be able to read and work with a datastore that was used with previous versions - not vice versa, obviously. But that's ok, that's pretty standard behavior. In a case where newer client created a chunk and an older client then tries to restore it - that wouldn't work, true. But you could configure the system NOT to use the new format by default, so one has to turn it on consciously - maybe even make a new datastore, if you wish, to unlock the new features. Then, make sure older clients can't use the new datastore and you're set. Nothing breaks then. In my opinion at least, that's not prohibitively complicated.
I might also note that you will hardy find "something that offers substantial improvements" if you don't agree to try anything. I think this would offer substantial improvements. With this being:
- xxHash for checksums
- multiple TCP streams (they can remain HTTP/2 connections if you wish, just use more of them in parallel)
- an option to disable TLS for transfer (it doesn't have to be complex, just use another port for non-TLS API access and put a listener without TLS there; later you could block API routes and selectively leave only those for chunk transfer accessible on non-TLS API, but for testing... it shouldn't at all be complicated to bring up a non-TLS API endpoint)
Try it. Then tell me if it qualifies as substantial improvement - or not. Test on some older lab hardware as well.
I said "in my testing". Restore speed from NVMe datastore was not any faster than restoring from HDD datastore. Reason for this is probably that HDD datastore is on ZFS that had all metadata from .chunks already in RAM. That is roughly the same as having ZFS with HDD-s + special vdev on NVMe or SSD (I say roughly the same, as RAM is still faster, but metadata on SSD does help a lot when metadata cache is empty).That's not true at all. For many of the tasks PBS does, spinning rust is orders of magnitudes slower than flash. You might not notice the difference for small incremental backup runs, where very little actual I/O happens, but PBS basically does random I/O with 1-4MB of data when writing/accessing backup contents, and random I/O on tons of small files for things like GC and verify.
Let's not argue about NVMe vs HDD speeds in general, we all agree on that. But when doing PBS restore - in my testing - there was no significant difference between the two. Therefore the bottleneck must be somewhere else:
- Network ? - 10 Gbps (alas, in second try it was 10 Gbps)
- CPU ? - not fully utilized
- Disks ? - might be the reason... let's try with enterprise NVMe hardware -> same result
And that's why I (re)opened this whole topic.
Once you see what I've seen, explained above, you then go to the forums and communicate that. Because it's not normal for software not to utilize hardware fully (or... it is quite normal unfortunately, but that's another topic). PVE being quite performant even on older machines, Linux-based, OSS inspired and all - I thought I won't have to explain to anyone that - software that is not utilizing the full hardware potential might be seen as something you'd actually want to look into, not try to reject.
The answer about a hashsum is pure dogma - no arguments given. You can't use a "no argument" as an argument in further conversation - really.I just want to point out - what might seem "obvious" to you might actually be factually wrong (see the hashsum algorithm point above).
I otherwise agree with you, that I can't tell for sure where the problem lies. In past experience it turned out I do have a good nose for this stuff. My nose is currently sniffing about: hashing, TLS and single-connection transfer. In a couple of years perhaps you can tell me how far off I was. At this point - neither of us knows. Right now I'm just sniffing and giving my advice. And you're... trying to find ways to reject it, more or less, it would seem.
Yeah, I lead a development team. I hear this a lot. I'll... politely skip the part where I tell you which of the above turns out to be true most of the time - in my experienceIf things seem suboptimal, it's usually not because we are too lazy to do a simple change, but because fixing them is more complicated than it looks
But that's not the point, anyway, something else is. Just because things seem difficult at first doesn't mean they actually are difficult to implement, and above all, it absolutely doesn't mean we shouldn't dig there. Quite the opposite. In my company we dig a lot. My team always hates the idea - initially. Always. Then they are super happy a couple of days later about how they solved the big complex issue. It's not always like that, of course, but I can confidently say that more than 50% of time I get the "are you crazy, this will take us 6 months, no chance", then usually the same night I receive tons of messages from one of developers, who then also finishes the change either the same night or within a few days in total euphoria with "this is great, this will work awesomely now" and everyone else suddenly agreeing. Same people that were 100% against even thinking about touching it, just 2 days before, are in epiphany. Just saying... Most of the time things look much more difficult then they actually are. And thinking in advance it's complex, difficult and spreading such information around - it blocks developers from even considering changes in code. And then there's laziness that helps a lot to quickly agree on the point. That's actually the biggest single thing that stops progress in existing code. Don't think that way, don't say it until you know for sure what it actually takes to make the change. Also I know which things are complex, which are not. Implementing another hash shouldn't be that complex -> after a developer is allowed to dig a bit in to the code and see what actually needs to be done. That should be before he is given assumptions, before thinking "it's more complicated than it looks". Because actually, in most occasions, it's not that complicated after all.
As long as CPU is not 100% utilized then, by definition, the CPU can not be said to be the bottleneck.I am not saying this to make you angry - but your CPU is actually rather old, and I suspect, the bottle neck in this case.
And as we know the CPU is not fully utilized I can actually put this here: the CPU is not the bottleneck, so let's move away from that assumption.
I understand that some part of processing might be single core bound (although, by monitoring CPU usage, I'm not seeing that here) - hence, the CPU was the bottleneck, you see, I told you. But in that case we should investigate ways to enable processing to utilize multiple cores. That might be achievable without changing much code (not saying it is). But the mere "your CPU is actually rather old", while at the same time my CPU is wasting cycles, well... That's maybe fine answer for an end customer looking for a quick solution - now. Go buy new hardware and try. Fine. But for an engineer, a developer, someone who's trying to make software perform better with hardware that is at it's disposal ? Not a valid answer. The CPU is not hitting the roof, so... let's try to find the cause and let's see how we can make better usage of the CPU.
For that: we need to identify where most time is spent during processing and what is waiting for what. Here, profiling the process, measuring different parts, etc is needed. This is where developers would need to jump in.
Or we can "blindly" (trusting my nose) try something to see if it helps.
I completely agree. And I hope you are not finding me unconstructive. I do have a rather low tolerance for vague answers, technically incorrect approach to fixing problems - and bs in general (not saying your posts are bs, they are not, in general).That being said - feedback is always welcome as long as it's brought forward in a constructive manner.
Ok, I understand.I can give you some more details why the "TLS benchmark" results are faster than your real world restore "line speed":
The TLS benchmark only uploads the same blob of semi-random data over and over and measure throughput - there is no processing done on either end. An actual restore chunk request has to find and load the chunk from disk, send its contents over the wire, parse, decode and verify the chunk on the client side, write the chunk to the target disk.
I could test with another TLS benchmark just to make sure the numbers agree. The way you describe it it seems a web server with TLS configured and me trying to download a file from it - should get me roughly the same result in terms of GBps. I'll try to test when I have time and report back. This is just to discard the TLS implementation itself as a potential issue (I don't expect to find an issue, this is just to be thorough).
Ok this could pose some issues in case you try to use parallel transfers. But we could still send the same chunk in parallel and rearrange it at the receiving end (a bit more complicated but not too much)...While our code tries to do things concurrently, there is always some overhead involved. In particular with restoring VMs, there was some limitation within Qemu that forces us to process one chunk after the other because writing from multiple threads to the same disk wasn't possible - I am not sure whether that has been lifted in the meantime. you could try figuring out whether a plain proxmox-backup-client restore of the big disk in your example is faster
There are still potential gains with faster hashing and without TLS, if you would be willing to try with such code.
Kind regards
(edited some typpos and grammar mistakes to make text easier to read)
Last edited:
Replying to my own message here...
Perhaps it could be used in conjunction with some faster crypto hash (like md5, that is not safe enough on its own) to make it collision-safe overall, but I'm guessing here. One needs to test if it's overall more performant in such combination and then, someone smarter than me, would have to decide on it's s collision resistance.
Didn't think of this at first. you could have noted it though, so I'd skip the chapter
Is that the big reason for using SHA-256 ?
Kind regards
Actually there is another point - collision resistance. If you are using SHA-256 as a chunk identifier - then I'm not sure how safe xxHash-128 is here, I don't know about it's collision resistance.please explain what is the reason behind SHA-256 as I must be missing something.
Perhaps it could be used in conjunction with some faster crypto hash (like md5, that is not safe enough on its own) to make it collision-safe overall, but I'm guessing here. One needs to test if it's overall more performant in such combination and then, someone smarter than me, would have to decide on it's s collision resistance.
Didn't think of this at first. you could have noted it though, so I'd skip the chapter
Is that the big reason for using SHA-256 ?
Kind regards
yesIs that the big reason for using SHA-256 ?
I'll answer to the longer one later!
Aahhh... of course it is. Yeah, I completely forgot about the whole dedupe stuff (which is brilliant btw).
Well, now I have to apologize for being too pushing with xxHash, and I do take that back. I'll not delete those part of my post, as that wouldn't be fair.
Ok. Perhaps we can do something with the other points -> not excluding the "faster hash" argument completely right away -> it's only now it's going to be much more difficult for me to push it, since collision resistance obviously plays an extremely important part of deduplication logic - and another hash could easily break statistical collision guarantees... so yeah, I understand the why now.
But - TLS and multiple TCP connection argument are still valid, hopefully we can talk about that.
Kind regards
Well, now I have to apologize for being too pushing with xxHash, and I do take that back. I'll not delete those part of my post, as that wouldn't be fair.
Ok. Perhaps we can do something with the other points -> not excluding the "faster hash" argument completely right away -> it's only now it's going to be much more difficult for me to push it, since collision resistance obviously plays an extremely important part of deduplication logic - and another hash could easily break statistical collision guarantees... so yeah, I understand the why now.
But - TLS and multiple TCP connection argument are still valid, hopefully we can talk about that.
Kind regards
You are only viewing this from a single perspective problem, that of higher latency links, even though I already gave you some other examples previously. Let me repeat them here:
- LACP will never utilize more than a single link capacity, because there's only one connection / one stream of data going on
- congested links (think offsite backups) backup traffic will end up worse when competing for bandwidth with other traffic, then it would end up in case there were more connections in parallel instead of just 1
- also, server network hardware and drivers may as well benefit from multiple TCP streams, as then it could handle them by multiple CPU-s
nobody is saying we won't ever implement some sort of multi-connection transport - but there is considerable overhead in doing so (both code complexity and actual resources consumed), so it's not a panacea either.
All of these points matter (and there are possibly other points I did not identify) and none of them can't benefit because of this choice that was made - to always use only 1 TCP connection for backup traffic. You can't ignore all of these other points and pretend there's a problem only a high latency links.
I am not saying it's only an issue with high latency links, just that that is the most prominent one that repeatedly comes up. I fully agree that there are setups out there that would have better performance with data flowing over multiple actual TCP connections. there are also setups where that isn't the case (i.e., a busy PBS server handling multiple clients will run into contention issues).
On "Why your TLS benchmark speed is so low I cannot say - it might be that your CPU just can't handle the throughput for the chosen cipher/crypto?" I also don't know why it's slow. I can only tell you that what I have observed and that is: my CPU has free cycles. And that clearly means there is room for improvement. Because if my CPUs are not all 100% utilized, what that means is that PBS is not using all the available hardware. But it should. Or, we'd love that it does. Because then things would run faster - and that's the goal, right ? So, it doesn't matter what CPU type I have and how old it is. If it's idling, then it's not the "CPU-s age" that is at fault, it's the solution can't utilize the CPU fully. Yes it will run better on a better CPU, what doesn't, but that's no solution - it can also run faster on a newer CPU if software was using the CPU potential better.
CPU age is not a valid answer for poor performance. With some exceptions around instructions, if the CPU doesn't support them, but that doesn't apply here - and it shouldn't apply if CPU is not fully utilized in any case.
that's unfortunately not true for crypto in general which tends to be highly optimized code - depending on the implementation, a CPU can be maxed out and not be 100% busy (because of things like vector instructions). it would require a detailed perf analysis of your specific system to show where the actual bottle neck is coming from.
Could you elaborate more on this please ? What else are you protecting ?
If you are aiming for "this way we can guarantee that no bad actor changed the contents of the file" I am willing to argue against that. When someone has access to files in your backup datastore you are more or less doomed at that point already, how does crypto hash help ? Trying to protect against intentional modification of protected data at rest, with crypto hashes, is... very debatable, at a minimum. Especially when/if it causes high costs (in newer servers and CPU power) for a user. Yes, SHA means that someone with access to chunks will have a harder time making files corrupt while retaining the hash, then with a non cryptographic checksum. But don't tell me that's the reason...
I know the benefits though: speed of calculation is orders of magnitude higher than SHA. Therefore I actually think it's very valid for this application, if not perfect. You say it is not - so, please explain what is the reason behind SHA-256 as I must be missing something.
Even if we don't agree on this, I think users should still have a choice to decide on their own. "I'll use the less secure hash because it's 50x faster" is something I might choose to do, given my level of trust in other protections I put in place of my backup machines - and based on my own risk evaluation. We should all do test restores anyway (that includes starting the VM/CT) as best practice, right ? so... what exactly are we loosing with a fast non-crypto hasher ? what is so important that you won't even consider a non-crypto hash in this case - I wish to know. Sorry I'm an engineer, so dogma is not an answer I can work with.
that is covered below
")
No, it doesn't need to break existing clients or servers. I even noted in my previous post an example of how this could be achieved. Without looking at the code, really, but there are many ways how backward compatibility can be retained when introducing a new feature (in this case a new hash or compression algorithm for chunks).
With backward compatibility I mean: newer PBS version will be able to read and work with a datastore that was used with previous versions - not vice versa, obviously. But that's ok, that's pretty standard behavior. In a case where newer client created a chunk and an older client then tries to restore it - that wouldn't work, true. But you could configure the system NOT to use the new format by default, so one has to turn it on consciously - maybe even make a new datastore, if you wish, to unlock the new features. Then, make sure older clients can't use the new datastore and you're set. Nothing breaks then. In my opinion at least, that's not prohibitively complicated.
we actually do try very hard with PBS to have compatibility in both directions where possible, and that includes things like being able to sync from a newer server to an older one and vice-versa.
for example, the recently introduced change detection mechanism for host type backups (split pxar archives) solely broke browsing those backup contents using the API/GUI, while retaining full compat for everything else including sync, verify and co.
that doesn't mean we don't ever do format changes that break this, but
- we don't do so lightly, there needs to be a *massive* benefit
- we usually make such features opt-in for quite a while before making them the default, to allow most involved systems to gain support in the meantime while still giving users the choice to adopt it faster
I might also note that you will hardy find "something that offers substantial improvements" if you don't agree to try anything. I think this would offer substantial improvements. With this being:
- xxHash for checksums
- multiple TCP streams (they can remain HTTP/2 connections if you wish, just use more of them in parallel)
- an option to disable TLS for transfer (it doesn't have to be complex, just use another port for non-TLS API access and put a listener without TLS there; later you could block API routes and selectively leave only those for chunk transfer accessible on non-TLS API, but for testing... it shouldn't at all be complicated to bring up a non-TLS API endpoint)
the last point I am not sure we will ever implement - not because I don't agree that it might give a performance boost, but because offering such potential footguns that can have catastrophic consequences is something we don't like to do. similarly, ssh doesn't have a built-in option to disable encryption, our APIs are not available over non-TLS (except for a redirect to the TLS one), and so forth. it's the year 2024, transports without encryption are dangerous (and yes, this includes local networks, unless we are talking direct PTP between to highly secured, trusted endpoints). if I could travel back in time, I'd also not implement migration_mode insecure for PVE
but that is my personal opinion, there might be other developers with a different view point.Try it. Then tell me if it qualifies as substantial improvement - or not. Test on some older lab hardware as well.
I'll repeat this once more - trying different transport mechanism is something we are planning to do, this includes:
- Quic
- multi-stream
- RusTLS vs the currently used OpenSSL
- anything else that looks promising when we sit down and do this experiment
I said "in my testing". Restore speed from NVMe datastore was not any faster than restoring from HDD datastore. Reason for this is probably that HDD datastore is on ZFS that had all metadata from .chunks already in RAM. That is roughly the same as having ZFS with HDD-s + special vdev on NVMe or SSD (I say roughly the same, as RAM is still faster, but metadata on SSD does help a lot when metadata cache is empty).
Let's not argue about NVMe vs HDD speeds in general, we all agree on that. But when doing PBS restore - in my testing - there was no significant difference between the two. Therefore the bottleneck must be somewhere else:
- Network ? - 10 Gbps (alas, in second try it was 10 Gbps)
- CPU ? - not fully utilized
I am fairly certain its this one, but se above
- Disks ? - might be the reason... let's try with enterprise NVMe hardware -> same result
And that's why I (re)opened this whole topic.
Once you see what I've seen, explained above, you then go to the forums and communicate that. Because it's not normal for software not to utilize hardware fully (or... it is quite normal unfortunately, but that's another topic). PVE being quite performant even on older machines, Linux-based, OSS inspired and all - I thought I won't have to explain to anyone that - software that is not utilizing the full hardware potential might be seen as something you'd actually want to look into, not try to reject.
there are areas where we know there is more that can be done, but most low hanging fruit is already done. and what hurts on one system works well on another and vice-versa, providing the right number of and kind of knobs, without providing too many footguns is not an easy endeavour
I otherwise agree with you, that I can't tell for sure where the problem lies. In past experience it turned out I do have a good nose for this stuff. My nose is currently sniffing about: hashing, TLS and single-connection transfer. In a couple of years perhaps you can tell me how far off I was. At this point - neither of us knows. Right now I'm just sniffing and giving my advice. And you're... trying to find ways to reject it, more or less, it would seem.
Yeah, I lead a development team. I hear this a lot. I'll... politely skip the part where I tell you which of the above turns out to be true most of the time - in my experience
But that's not the point, anyway, something else is. Just because things seem difficult at first doesn't mean they actually are difficult to implement, and above all, it absolutely doesn't mean we shouldn't dig there. Quite the opposite. In my company we dig a lot. My team always hates the idea - initially. Always. Then they are super happy a couple of days later about how they solved the big complex issue. It's not always like that, of course, but I can confidently say that more than 50% of time I get the "are you crazy, this will take us 6 months, no chance", then usually the same night I receive tons of messages from one of developers, who then also finishes the change either the same night or within a few days in total euphoria with "this is great, this will work awesomely now" and everyone else suddenly agreeing. Same people that were 100% against even thinking about touching it, just 2 days before, are in epiphany. Just saying... Most of the time things look much more difficult then they actually are. And thinking in advance it's complex, difficult and spreading such information around - it blocks developers from even considering changes in code. And then there's laziness that helps a lot to quickly agree on the point. That's actually the biggest single thing that stops progress in existing code. Don't think that way, don't say it until you know for sure what it actually takes to make the change. Also I know which things are complex, which are not. Implementing another hash shouldn't be that complex -> after a developer is allowed to dig a bit in to the code and see what actually needs to be done. That should be before he is given assumptions, before thinking "it's more complicated than it looks". Because actually, in most occasions, it's not that complicated after all.
As long as CPU is not 100% utilized then, by definition, the CPU can not be said to be the bottleneck.
And as we know the CPU is not fully utilized I can actually put this here: the CPU is not the bottleneck, so let's move away from that assumption.
it would be interesting to get perf data for both ends during a TLS benchmark, it might show some optimization potential for systems like yours. if you want to try that, I can provide more guidance on how to get that running..
Aahhh... of course it is. Yeah, I completely forgot about the whole dedupe stuff (which is brilliant btw).
Well, now I have to apologize for being too pushing with xxHash, and I do take that back. I'll not delete those part of my post, as that wouldn't be fair.
Ok. Perhaps we can do something with the other points -> not excluding the "faster hash" argument completely right away -> it's only now it's going to be much more difficult for me to push it, since collision resistance obviously plays an extremely important part of deduplication logic - and another hash could easily break statistical collision guarantees... so yeah, I understand the why now.
yeah - we rely on the properties of sha256, but that maybe could be documented more prominently
switching to a new scheme with similar properties but better performance would in principle be doable - but it would require either breaking the deduplicaton between old and new, or some semi-expensive compatibility mechanism.. you already found the corresponding bug tracker entry Hi fabian,
Thank you for your response. I can agree with most of what you replied... except this part:
This holds true... for public web sites. It doesn't really translate to server environments, normally isolated with VLAN-s for different traffic types.
footguns ?? man, we're Linux users... rm -fR ? dd ? hdparm ? zfs destroy ? those wont even ask for confirmation.
ssh ? yes. But that's a secure alternative to telnet (it actually has "secure" in its name and is here to provide a secure layer on top of pre-existing insecure stuff). Using ssh as an example here is like saying that TLS is not offered without encryption c'mon
Anyway, with ssh in the system, that same system is in no way stopping you from using: telnet, if you want to. Or FTP, or whatever. Btw NFS and SMB are also not encrypted by default, as far as I know - and we surely can't say these are not used - in no isolated environments either. And what about iSCSI ? Would you then ban iSCSI and NFS in server environments, by same argument ? But I wonder how many users would support such decision.
Perhaps we should use AES-256 on SATA as well (I mean, there's eSATA), on USB for sure, on SCSI, on everything. How is that different ? Hell, we need it on monitors as well - they use a cable. Really, I read recently that someone has sucessfully sniffed the image using RMI coming from the monitor cable, so... that's being used in the wild ! That should get encrypted immediately - with no option to disable it ! Who cares how much it costs - buy more hardware, you need to stay safe. I can go futher with this nonsense... but I think you get the point.
"it's the year 2024, transports without encryption are dangerous" -> this is waaaaay too general, this can't/shouldn't be applied universally. Honestly I'm pretty shocked by such a broad statement.
Besides, as you mentioned, you already have it for migration traffic. I guess because someone was pushing it hardly enough and you had to let go. Which is a good thing. And it's - not the default, so you can sleep calmly at night. You do also support NFS and iSCSI in proxmox, right ? And that is for access to production storage, right ? and... where's the footgun protection here, that we desperately need to survive in 2024 ? How do you defend that. In what way is safety here less important (as it's allowed witout encryption) than in backup transfers. Why do you think bakcup transfer links would be any less protected then iSCSI or NFS links - in any serious production setup, where it actually matters.
Anyway my take here is: You can protect users by using safe defaults, if you want to - not by taking away options.
Hopefully, more users can chime in on this one.
Kind regards
Thank you for your response. I can agree with most of what you replied... except this part:
the last point I am not sure we will ever implement - not because I don't agree that it might give a performance boost, but because offering such potential footguns that can have catastrophic consequences is something we don't like to do. similarly, ssh doesn't have a built-in option to disable encryption, our APIs are not available over non-TLS (except for a redirect to the TLS one), and so forth. it's the year 2024, transports without encryption are dangerous (and yes, this includes local networks, unless we are talking direct PTP between to highly secured, trusted endpoints). if I could travel back in time, I'd also not implement migration_mode insecure for PVE
This holds true... for public web sites. It doesn't really translate to server environments, normally isolated with VLAN-s for different traffic types.
footguns ?? man, we're Linux users... rm -fR ? dd ? hdparm ? zfs destroy ? those wont even ask for confirmation.
ssh ? yes. But that's a secure alternative to telnet (it actually has "secure" in its name and is here to provide a secure layer on top of pre-existing insecure stuff). Using ssh as an example here is like saying that TLS is not offered without encryption
c'monAnyway, with ssh in the system, that same system is in no way stopping you from using: telnet, if you want to. Or FTP, or whatever. Btw NFS and SMB are also not encrypted by default, as far as I know - and we surely can't say these are not used - in no isolated environments either. And what about iSCSI ? Would you then ban iSCSI and NFS in server environments, by same argument ? But I wonder how many users would support such decision.
Perhaps we should use AES-256 on SATA as well (I mean, there's eSATA), on USB for sure, on SCSI, on everything. How is that different ? Hell, we need it on monitors as well - they use a cable. Really, I read recently that someone has sucessfully sniffed the image using RMI coming from the monitor cable, so... that's being used in the wild ! That should get encrypted immediately - with no option to disable it ! Who cares how much it costs - buy more hardware, you need to stay safe. I can go futher with this nonsense... but I think you get the point.
"it's the year 2024, transports without encryption are dangerous" -> this is waaaaay too general, this can't/shouldn't be applied universally. Honestly I'm pretty shocked by such a broad statement.
Besides, as you mentioned, you already have it for migration traffic. I guess because someone was pushing it hardly enough and you had to let go. Which is a good thing. And it's - not the default, so you can sleep calmly at night. You do also support NFS and iSCSI in proxmox, right ? And that is for access to production storage, right ? and... where's the footgun protection here, that we desperately need to survive in 2024 ? How do you defend that. In what way is safety here less important (as it's allowed witout encryption) than in backup transfers. Why do you think bakcup transfer links would be any less protected then iSCSI or NFS links - in any serious production setup, where it actually matters.
Anyway my take here is: You can protect users by using safe defaults, if you want to - not by taking away options.
Hopefully, more users can chime in on this one.
Kind regards
Last edited:
Updating a topic, because... ignoring doesn't help and surely won't make things better.
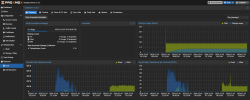
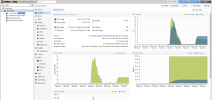
So right now I'm testing PBS on a DELL R740xd. A ZFS pool of 8 x WD RED PRO 6 TB in RAID10 + special vdev on SSD. Testing backup over 10G. Backup speed is 300-400 MB/s, with peaks up to 500 MB/s. Not bad, considering the source hosts also use HDDs.
Verify speed ? Barely over 100 MB/s. This I can't explain. On a server with 2 x XEON Golds, 128 GB RAM and a ZFS with 4 striped mirrors, this is just crazy slow. That's 25 MB/s per drive, read speed (and don't forget metadata is on SSD). Average chunk size is 3 MB. Freshly installed server, so there's practically no fragmentation - this is the first backup on a freshly created datastore.
This is pool throughput I'm watching, of course. I'm not interested in any artificially derived/pumped-up numbers, that perhaps take into account compression, source VM ZFS size (regardless of what's actually used) and what not. We're doing a verify, means we're reading data and calculating checksums. At what rate are we doing that ? At a 100 MB/s. On this setup, that's pretty slow.
Hardware specs:
- 12 x Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz (2 Sockets) - HT off
- 128 GB RAM
- pure HBA card (no RAID stuff)
So, not an oldtimer CPU any more. It's clocked at 3.40 GHz - I specifically choose a high clocked CPU, suspecting that some operations may not be sufficiently multithreaded. This one should have all the bells and whistles regarding AES instructions and so on.
Everything is enterprise grade hardware, except the rather oldish SATA drives (they're not that slow, it's WD RED Pro so not enterprise but also not complete garbage) and they're setup in RAID-10.
PBS is installed alongside PVE on the host. Latest no-subscription version as of yesterday.
Disks:
Source servers are close to this spec (also DELL R740xd, just slower CPU-s and double more RAM, also ZFS but enterprise SAS HDD-s).
Attached images show backup speeds and later verify speeds. Also attached is CPU usage when doing verify.
I didn't have a chance to try a restore to see how fast (or slow) that goes - because verify hasn't finished, it's slow as hell. Hopefully restores won't be that slow.
Just 100 MB/s verify (which is read + calculate SHA256 and compare values, which shouldn't be a problem with these XEONs) while at the same time getting almost 500 MB/s doing writes (the backup job) is a little baffling.
So right now I'm testing PBS on a DELL R740xd. A ZFS pool of 8 x WD RED PRO 6 TB in RAID10 + special vdev on SSD. Testing backup over 10G. Backup speed is 300-400 MB/s, with peaks up to 500 MB/s. Not bad, considering the source hosts also use HDDs.
Verify speed ? Barely over 100 MB/s. This I can't explain. On a server with 2 x XEON Golds, 128 GB RAM and a ZFS with 4 striped mirrors, this is just crazy slow. That's 25 MB/s per drive, read speed (and don't forget metadata is on SSD). Average chunk size is 3 MB. Freshly installed server, so there's practically no fragmentation - this is the first backup on a freshly created datastore.
This is pool throughput I'm watching, of course. I'm not interested in any artificially derived/pumped-up numbers, that perhaps take into account compression, source VM ZFS size (regardless of what's actually used) and what not. We're doing a verify, means we're reading data and calculating checksums. At what rate are we doing that ? At a 100 MB/s. On this setup, that's pretty slow.
Hardware specs:
- 12 x Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz (2 Sockets) - HT off
- 128 GB RAM
- pure HBA card (no RAID stuff)
So, not an oldtimer CPU any more. It's clocked at 3.40 GHz - I specifically choose a high clocked CPU, suspecting that some operations may not be sufficiently multithreaded. This one should have all the bells and whistles regarding AES instructions and so on.
Everything is enterprise grade hardware, except the rather oldish SATA drives (they're not that slow, it's WD RED Pro so not enterprise but also not complete garbage) and they're setup in RAID-10.
PBS is installed alongside PVE on the host. Latest no-subscription version as of yesterday.
proxmox-ve: 8.3.0 (running kernel: 6.8.12-5-pve)
pve-manager: 8.3.2 (running version: 8.3.2/3e76eec21c4a14a7)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-5
proxmox-kernel-6.8.12-5-pve-signed: 6.8.12-5
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
ceph-fuse: 17.2.7-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx11
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.1
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.4
libpve-access-control: 8.2.0
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.10
libpve-cluster-perl: 8.0.10
libpve-common-perl: 8.2.9
libpve-guest-common-perl: 5.1.6
libpve-http-server-perl: 5.1.2
libpve-network-perl: 0.10.0
libpve-rs-perl: 0.9.1
libpve-storage-perl: 8.3.2
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.5.0-1
proxmox-backup-client: 3.3.2-1
proxmox-backup-file-restore: 3.3.2-2
proxmox-firewall: 0.6.0
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.3
pve-cluster: 8.0.10
pve-container: 5.2.2
pve-docs: 8.3.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.2
pve-firewall: 5.1.0
pve-firmware: 3.14-2
pve-ha-manager: 4.0.6
pve-i18n: 3.3.2
pve-qemu-kvm: 9.0.2-4
pve-xtermjs: 5.3.0-3
qemu-server: 8.3.3
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.6-pve1
pve-manager: 8.3.2 (running version: 8.3.2/3e76eec21c4a14a7)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-5
proxmox-kernel-6.8.12-5-pve-signed: 6.8.12-5
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
ceph-fuse: 17.2.7-pve3
corosync: 3.1.7-pve3
criu: 3.17.1-2
glusterfs-client: 10.3-5
ifupdown2: 3.2.0-1+pmx11
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libknet1: 1.28-pve1
libproxmox-acme-perl: 1.5.1
libproxmox-backup-qemu0: 1.4.1
libproxmox-rs-perl: 0.3.4
libpve-access-control: 8.2.0
libpve-apiclient-perl: 3.3.2
libpve-cluster-api-perl: 8.0.10
libpve-cluster-perl: 8.0.10
libpve-common-perl: 8.2.9
libpve-guest-common-perl: 5.1.6
libpve-http-server-perl: 5.1.2
libpve-network-perl: 0.10.0
libpve-rs-perl: 0.9.1
libpve-storage-perl: 8.3.2
libspice-server1: 0.15.1-1
lvm2: 2.03.16-2
lxc-pve: 6.0.0-1
lxcfs: 6.0.0-pve2
novnc-pve: 1.5.0-1
proxmox-backup-client: 3.3.2-1
proxmox-backup-file-restore: 3.3.2-2
proxmox-firewall: 0.6.0
proxmox-kernel-helper: 8.1.0
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.3
pve-cluster: 8.0.10
pve-container: 5.2.2
pve-docs: 8.3.1
pve-edk2-firmware: 4.2023.08-4
pve-esxi-import-tools: 0.7.2
pve-firewall: 5.1.0
pve-firmware: 3.14-2
pve-ha-manager: 4.0.6
pve-i18n: 3.3.2
pve-qemu-kvm: 9.0.2-4
pve-xtermjs: 5.3.0-3
qemu-server: 8.3.3
smartmontools: 7.3-pve1
spiceterm: 3.3.0
swtpm: 0.8.0+pve1
vncterm: 1.8.0
zfsutils-linux: 2.2.6-pve1
proxmox-backup: not correctly installed (running kernel: 6.8.12-5-pve)
proxmox-backup-server: 3.3.2-1 (running version: 3.3.2)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-5
proxmox-kernel-6.8.12-5-pve-signed: 6.8.12-5
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
ifupdown2: 3.2.0-1+pmx11
libjs-extjs: 7.0.0-5
proxmox-backup-docs: 3.3.2-1
proxmox-backup-client: 3.3.2-1
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.3
pve-xtermjs: 5.3.0-3
smartmontools: 7.3-pve1
zfsutils-linux: 2.2.6-pve1
proxmox-backup-server: 3.3.2-1 (running version: 3.3.2)
proxmox-kernel-helper: 8.1.0
proxmox-kernel-6.8: 6.8.12-5
proxmox-kernel-6.8.12-5-pve-signed: 6.8.12-5
proxmox-kernel-6.8.12-4-pve-signed: 6.8.12-4
ifupdown2: 3.2.0-1+pmx11
libjs-extjs: 7.0.0-5
proxmox-backup-docs: 3.3.2-1
proxmox-backup-client: 3.3.2-1
proxmox-mail-forward: 0.3.1
proxmox-mini-journalreader: 1.4.0
proxmox-offline-mirror-helper: 0.6.7
proxmox-widget-toolkit: 4.3.3
pve-xtermjs: 5.3.0-3
smartmontools: 7.3-pve1
zfsutils-linux: 2.2.6-pve1
Disks:
Code:
# zpool list -v
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
rpool 22.0T 3.22T 18.8T - - 0% 14% 1.00x ONLINE -
mirror-0 5.45T 829G 4.64T - - 0% 14.8% - ONLINE
ata-WDC_WD6003FFBX-68MU3N0_V7GSJKKH-part3 5.46T - - - - - - - ONLINE
ata-WDC_WD6003FFBX-68MU3N0_V7GY3VJP-part3 5.46T - - - - - - - ONLINE
mirror-1 5.45T 821G 4.65T - - 0% 14.7% - ONLINE
ata-WDC_WD6003FFBX-68MU3N0_V7GY98ZP-part3 5.46T - - - - - - - ONLINE
ata-WDC_WD6002FFWX-68TZ4N0_K1G0TN8B-part3 5.46T - - - - - - - ONLINE
mirror-2 5.45T 815G 4.66T - - 0% 14.6% - ONLINE
ata-WDC_WD6003FFBX-68MU3N0_V7GUMMGH-part3 5.46T - - - - - - - ONLINE
ata-WDC_WD6002FFWX-68TZ4N0_K1G0UATB-part3 5.46T - - - - - - - ONLINE
mirror-3 5.45T 822G 4.65T - - 0% 14.7% - ONLINE
ata-WDC_WD6003FFBX-68MU3N0_V7GASM0H-part3 5.46T - - - - - - - ONLINE
ata-WDC_WD6002FFWX-68TZ4N0_K1G0UL3B-part3 5.46T - - - - - - - ONLINE
special - - - - - - - - -
mirror-4 199G 9.78G 189G - - 12% 4.91% - ONLINE
ata-MTFDDAK240MBB-1AE1ZA_00AJ401_00AJ404LEN_15F13340-part1 200G - - - - - - - ONLINE
ata-MTFDDAK240MBB-1AE1ZA_00AJ401_00AJ404LEN_162235A7-part1 200G - - - - - - - ONLINESource servers are close to this spec (also DELL R740xd, just slower CPU-s and double more RAM, also ZFS but enterprise SAS HDD-s).
Attached images show backup speeds and later verify speeds. Also attached is CPU usage when doing verify.
I didn't have a chance to try a restore to see how fast (or slow) that goes - because verify hasn't finished, it's slow as hell. Hopefully restores won't be that slow.
Just 100 MB/s verify (which is read + calculate SHA256 and compare values, which shouldn't be a problem with these XEONs) while at the same time getting almost 500 MB/s doing writes (the backup job) is a little baffling.
Attachments
Last edited:
Ok, I stopped the verify process and tried a restore - aiming specifically for a backup snapshot that hasn't yet been verified on the PBS. Speed is... well, it's a disaster, I get like 50-ish MB/s restore speed for a VM disk that goes to SSD and around 25-30 MB/s for a VM disk that goes to SAS HDD pool. That's 10-20 times slower than backup speeds.
In real life restore that would be pretty much useless - to restore several TB VM disk I'd need... what, 10 hours per TB ?? Yeah, that's not gonna work.
I'm getting also a lot of write IOPS while doing a restore... those would be metadata updates, I guess. As that's all going to SSD-s, shouldn't be the cause for any slowness.
Wow. This is really slow. I guess this is where my trip with PBS ends at least for now. That's too bad. But I can't realistically use this in any place where RTO matters... and that's pretty much any production VM these days.
at least for now. That's too bad. But I can't realistically use this in any place where RTO matters... and that's pretty much any production VM these days.
What's also too bad is I left one Veeam socket licence to expire - didn't renew it since I was counting on PBS to take over it's job - and now I can't renew it since they don't let me get a socket licence anymore. Aaaah &%W#*!)#!
The good thing is - I found this out before having to do an actual restore of some production VM. That would hurt.
Conclusion ? Money spent on hardware doesn't help when software is using the machine to make coffee instead of do work as efficiently as possible... well I suspected it might end like this. But well, I got the server second hand for a good price, so it doesn't matter.
When I get Veeam installed on this machine, I'll post results - at least as guidance for others having similar issues. Who knows ! maybe it's still my hardware ?? I seriously doubt it, but we'll see.
--
Test restore finished while I was typing here. It took 53 minutes, it's a VM consisting of 92 GB restored to SAS HDD pool and 114 GB restored to SSD pool (sizes of VM disk used space after decompression) from this PBS over 10Gbps network. That would translate to 66 MB/s restore speed, if we were to ignore compression and what was actually read and transferred over the wire and onto the destination drives. Still way too slow. For those curious, the actual average raw transfer speed from PBS back to PVE host was just below 40 MB/s.
In real life restore that would be pretty much useless - to restore several TB VM disk I'd need... what, 10 hours per TB ?? Yeah, that's not gonna work.
I'm getting also a lot of write IOPS while doing a restore... those would be metadata updates, I guess. As that's all going to SSD-s, shouldn't be the cause for any slowness.
Code:
# zpool iostat -vy rpool 30
capacity operations bandwidth
pool alloc free read write read write
-------------------------------------------------------------- ----- ----- ----- ----- ----- -----
rpool 3.22T 18.8T 53 34 35.4M 450K
mirror-0 829G 4.64T 14 0 9.27M 3.73K
ata-WDC_WD6003FFBX-68MU3N0_V7GSJKKH-part3 - - 7 0 4.52M 1.87K
ata-WDC_WD6003FFBX-68MU3N0_V7GY3VJP-part3 - - 6 0 4.75M 1.87K
mirror-1 821G 4.65T 13 1 8.73M 22.9K
ata-WDC_WD6003FFBX-68MU3N0_V7GY98ZP-part3 - - 6 0 4.38M 11.5K
ata-WDC_WD6002FFWX-68TZ4N0_K1G0TN8B-part3 - - 6 0 4.35M 11.5K
mirror-2 815G 4.66T 12 2 8.53M 13.1K
ata-WDC_WD6003FFBX-68MU3N0_V7GUMMGH-part3 - - 6 1 4.40M 6.53K
ata-WDC_WD6002FFWX-68TZ4N0_K1G0UATB-part3 - - 6 1 4.13M 6.53K
mirror-3 822G 4.65T 13 0 8.88M 4.80K
ata-WDC_WD6003FFBX-68MU3N0_V7GASM0H-part3 - - 6 0 4.16M 2.40K
ata-WDC_WD6002FFWX-68TZ4N0_K1G0UL3B-part3 - - 7 0 4.72M 2.40K
special - - - - - -
mirror-4 9.78G 189G 0 28 0 406K
ata-MTFDDAK240MBB-1AE1ZA_00AJ401_00AJ404LEN_15F13340-part1 - - 0 14 0 203K
ata-MTFDDAK240MBB-1AE1ZA_00AJ401_00AJ404LEN_162235A7-part1 - - 0 14 0 203K
-------------------------------------------------------------- ----- ----- ----- ----- ----- -----Wow. This is really slow. I guess this is where my trip with PBS ends
at least for now. That's too bad. But I can't realistically use this in any place where RTO matters... and that's pretty much any production VM these days.What's also too bad is I left one Veeam socket licence to expire - didn't renew it since I was counting on PBS to take over it's job - and now I can't renew it since they don't let me get a socket licence anymore. Aaaah &%W#*!)#!
The good thing is - I found this out before having to do an actual restore of some production VM. That would hurt.
Conclusion ? Money spent on hardware doesn't help when software is using the machine to make coffee instead of do work as efficiently as possible... well I suspected it might end like this. But well, I got the server second hand for a good price, so it doesn't matter.
When I get Veeam installed on this machine, I'll post results - at least as guidance for others having similar issues. Who knows ! maybe it's still my hardware ?? I seriously doubt it, but we'll see.
--
Test restore finished while I was typing here. It took 53 minutes, it's a VM consisting of 92 GB restored to SAS HDD pool and 114 GB restored to SSD pool (sizes of VM disk used space after decompression) from this PBS over 10Gbps network. That would translate to 66 MB/s restore speed, if we were to ignore compression and what was actually read and transferred over the wire and onto the destination drives. Still way too slow. For those curious, the actual average raw transfer speed from PBS back to PVE host was just below 40 MB/s.
ARC max is 32 GB, but primarycache=metadata on this dataset, because it's a PBS (multi TB) store, where caching actual data blocks doesn't make much sense.
# proxmox-backup-client benchmark
SHA256 speed: 480.48 MB/s
Compression speed: 448.48 MB/s
Decompress speed: 631.12 MB/s
AES256/GCM speed: 3476.88 MB/s
Verify speed: 271.38 MB/s
┌───────────────────────────────────┬────────────────────┐
│ Name │ Value │
╞═══════════════════════════════════╪════════════════════╡
│ TLS (maximal backup upload speed) │ not tested │
├───────────────────────────────────┼────────────────────┤
│ SHA256 checksum computation speed │ 480.48 MB/s (24%) │
├───────────────────────────────────┼────────────────────┤
│ ZStd level 1 compression speed │ 448.48 MB/s (60%) │
├───────────────────────────────────┼────────────────────┤
│ ZStd level 1 decompression speed │ 631.12 MB/s (53%) │
├───────────────────────────────────┼────────────────────┤
│ Chunk verification speed │ 271.38 MB/s (36%) │
├───────────────────────────────────┼────────────────────┤
│ AES256 GCM encryption speed │ 3476.88 MB/s (95%) │
└───────────────────────────────────┴────────────────────┘
SHA256 speed: 480.48 MB/s
Compression speed: 448.48 MB/s
Decompress speed: 631.12 MB/s
AES256/GCM speed: 3476.88 MB/s
Verify speed: 271.38 MB/s
┌───────────────────────────────────┬────────────────────┐
│ Name │ Value │
╞═══════════════════════════════════╪════════════════════╡
│ TLS (maximal backup upload speed) │ not tested │
├───────────────────────────────────┼────────────────────┤
│ SHA256 checksum computation speed │ 480.48 MB/s (24%) │
├───────────────────────────────────┼────────────────────┤
│ ZStd level 1 compression speed │ 448.48 MB/s (60%) │
├───────────────────────────────────┼────────────────────┤
│ ZStd level 1 decompression speed │ 631.12 MB/s (53%) │
├───────────────────────────────────┼────────────────────┤
│ Chunk verification speed │ 271.38 MB/s (36%) │
├───────────────────────────────────┼────────────────────┤
│ AES256 GCM encryption speed │ 3476.88 MB/s (95%) │
└───────────────────────────────────┴────────────────────┘
# zfs get all rpool/pbs-storage
NAME PROPERTY VALUE SOURCE
rpool/pbs-storage type filesystem -
rpool/pbs-storage creation Wed Dec 18 21:36 2024 -
rpool/pbs-storage used 3.30T -
rpool/pbs-storage available 4.70T -
rpool/pbs-storage referenced 3.30T -
rpool/pbs-storage compressratio 1.15x -
rpool/pbs-storage mounted yes -
rpool/pbs-storage quota none default
rpool/pbs-storage reservation none default
rpool/pbs-storage recordsize 1M local
rpool/pbs-storage mountpoint /rpool/pbs-storage default
rpool/pbs-storage sharenfs off default
rpool/pbs-storage checksum on default
rpool/pbs-storage compression lz4 inherited from rpool
rpool/pbs-storage atime on inherited from rpool
rpool/pbs-storage devices on default
rpool/pbs-storage exec on default
rpool/pbs-storage setuid on default
rpool/pbs-storage readonly off default
rpool/pbs-storage zoned off default
rpool/pbs-storage snapdir hidden default
rpool/pbs-storage aclmode discard default
rpool/pbs-storage aclinherit restricted default
rpool/pbs-storage createtxg 1928 -
rpool/pbs-storage canmount on default
rpool/pbs-storage xattr on default
rpool/pbs-storage copies 1 default
rpool/pbs-storage version 5 -
rpool/pbs-storage utf8only off -
rpool/pbs-storage normalization none -
rpool/pbs-storage casesensitivity sensitive -
rpool/pbs-storage vscan off default
rpool/pbs-storage nbmand off default
rpool/pbs-storage sharesmb off default
rpool/pbs-storage refquota 8T local
rpool/pbs-storage refreservation none default
rpool/pbs-storage guid 13116019051458877883 -
rpool/pbs-storage primarycache metadata local
rpool/pbs-storage secondarycache none local
rpool/pbs-storage usedbysnapshots 0B -
rpool/pbs-storage usedbydataset 3.30T -
rpool/pbs-storage usedbychildren 0B -
rpool/pbs-storage usedbyrefreservation 0B -
rpool/pbs-storage logbias latency default
rpool/pbs-storage objsetid 1484 -
rpool/pbs-storage dedup off default
rpool/pbs-storage mlslabel none default
rpool/pbs-storage sync standard inherited from rpool
rpool/pbs-storage dnodesize legacy default
rpool/pbs-storage refcompressratio 1.15x -
rpool/pbs-storage written 3.30T -
rpool/pbs-storage logicalused 3.79T -
rpool/pbs-storage logicalreferenced 3.79T -
rpool/pbs-storage volmode default default
rpool/pbs-storage filesystem_limit none default
rpool/pbs-storage snapshot_limit none default
rpool/pbs-storage filesystem_count none default
rpool/pbs-storage snapshot_count none default
rpool/pbs-storage snapdev hidden default
rpool/pbs-storage acltype off default
rpool/pbs-storage context none default
rpool/pbs-storage fscontext none default
rpool/pbs-storage defcontext none default
rpool/pbs-storage rootcontext none default
rpool/pbs-storage relatime on inherited from rpool
rpool/pbs-storage redundant_metadata all default
rpool/pbs-storage overlay on default
rpool/pbs-storage encryption off default
rpool/pbs-storage keylocation none default
rpool/pbs-storage keyformat none default
rpool/pbs-storage pbkdf2iters 0 default
rpool/pbs-storage special_small_blocks 0 default
rpool/pbs-storage prefetch all default
NAME PROPERTY VALUE SOURCE
rpool/pbs-storage type filesystem -
rpool/pbs-storage creation Wed Dec 18 21:36 2024 -
rpool/pbs-storage used 3.30T -
rpool/pbs-storage available 4.70T -
rpool/pbs-storage referenced 3.30T -
rpool/pbs-storage compressratio 1.15x -
rpool/pbs-storage mounted yes -
rpool/pbs-storage quota none default
rpool/pbs-storage reservation none default
rpool/pbs-storage recordsize 1M local
rpool/pbs-storage mountpoint /rpool/pbs-storage default
rpool/pbs-storage sharenfs off default
rpool/pbs-storage checksum on default
rpool/pbs-storage compression lz4 inherited from rpool
rpool/pbs-storage atime on inherited from rpool
rpool/pbs-storage devices on default
rpool/pbs-storage exec on default
rpool/pbs-storage setuid on default
rpool/pbs-storage readonly off default
rpool/pbs-storage zoned off default
rpool/pbs-storage snapdir hidden default
rpool/pbs-storage aclmode discard default
rpool/pbs-storage aclinherit restricted default
rpool/pbs-storage createtxg 1928 -
rpool/pbs-storage canmount on default
rpool/pbs-storage xattr on default
rpool/pbs-storage copies 1 default
rpool/pbs-storage version 5 -
rpool/pbs-storage utf8only off -
rpool/pbs-storage normalization none -
rpool/pbs-storage casesensitivity sensitive -
rpool/pbs-storage vscan off default
rpool/pbs-storage nbmand off default
rpool/pbs-storage sharesmb off default
rpool/pbs-storage refquota 8T local
rpool/pbs-storage refreservation none default
rpool/pbs-storage guid 13116019051458877883 -
rpool/pbs-storage primarycache metadata local
rpool/pbs-storage secondarycache none local
rpool/pbs-storage usedbysnapshots 0B -
rpool/pbs-storage usedbydataset 3.30T -
rpool/pbs-storage usedbychildren 0B -
rpool/pbs-storage usedbyrefreservation 0B -
rpool/pbs-storage logbias latency default
rpool/pbs-storage objsetid 1484 -
rpool/pbs-storage dedup off default
rpool/pbs-storage mlslabel none default
rpool/pbs-storage sync standard inherited from rpool
rpool/pbs-storage dnodesize legacy default
rpool/pbs-storage refcompressratio 1.15x -
rpool/pbs-storage written 3.30T -
rpool/pbs-storage logicalused 3.79T -
rpool/pbs-storage logicalreferenced 3.79T -
rpool/pbs-storage volmode default default
rpool/pbs-storage filesystem_limit none default
rpool/pbs-storage snapshot_limit none default
rpool/pbs-storage filesystem_count none default
rpool/pbs-storage snapshot_count none default
rpool/pbs-storage snapdev hidden default
rpool/pbs-storage acltype off default
rpool/pbs-storage context none default
rpool/pbs-storage fscontext none default
rpool/pbs-storage defcontext none default
rpool/pbs-storage rootcontext none default
rpool/pbs-storage relatime on inherited from rpool
rpool/pbs-storage redundant_metadata all default
rpool/pbs-storage overlay on default
rpool/pbs-storage encryption off default
rpool/pbs-storage keylocation none default
rpool/pbs-storage keyformat none default
rpool/pbs-storage pbkdf2iters 0 default
rpool/pbs-storage special_small_blocks 0 default
rpool/pbs-storage prefetch all default
Last edited:
I'm providing additional info about pool performance.
I went on and did a quick test with fio, trying to replicate what I think PBS is doing. Knowing that chunk sizes are varying between 1 and 4 MB and using random read with those sizes, over a 20 GB file (to spread it out), I tried to see what I get on this pool with 1 worker and more workers. Remember: primarycache=metadata on this recordset. Results below.
Looking at the first test, I'm getting barely 100 MB/s. I don't know if this is what PBS is doing (scanning chunks sequentially, one at a time) but the speed I'm getting suggests that could be the case.
Let's look at the second test. As I increase the number of workers so does the speed increase and by a lot - showing this pool can do much better. With 32 workers I'm getting over 900 MB/s. A much better result. So this pool seems to be able to do random reads of 1-4 MB sizes pretty darn well - provided enough workers are doing it in parallel.
With 16 workers it's 450-500 MB/s, but fio tests are showing clearly that it grows with more parallelism.
So... is PBS doing that chunk verification in parallel ? I don't really know - but looking at the speed and CPU usage I'd guess it's not. If so... well, could that change ? How difficult would that be, let's see: all a thread needs to do is read a chunk, calculate it's hash and save the result somewhere in memory. Ok nothing complex. In .NET I'd probably use something from thread-safe collections (like a ConcurrentQueue) to keep the list of chunks that need to be checked, then have a number of workers (that PBS admin could configure) empty that queue in parallel. Each thread doing a verify of a single chunk and putting results in a ConcurrentDictionary. That's easy. And that would make verify run on chunks in parallel (.NET has thread-safe classes ready to use so I mention them because I use .NET, but same can be achieved in other ways, with whatever you use for this bit of thread synchronization in language PBS is written in - but even manual locking would work fine here, as there's very little overlapping: dequeue an item & save a boolean result, those are the only points needing thread synchronization, trivial to achieve).
Question: is PBS already doing chunk verification in parallel ?
If yes: how many threads are being used and is there an option to configure that number ?
If not: could you consider adding that ?
I believe there are other places chunk verification could improve. Like if I'm running a verify of a VM and I have 20 snapshots/backup copies of that VM - and in that 20 copies >90% of all chunks are actually shared between copies, then perhaps we don't have to check the same chunk 20 times for each copy ? I don't know if this is already done that way, maybe it is - but looking at the time it takes for verification I'm not sure... I may be mistaken on this one.
Damn, perhaps I should really take a look at the sources before commenting, but I don't know what PBS is written in and I'm not so sure I'd be able to follow it...
I went on and did a quick test with fio, trying to replicate what I think PBS is doing. Knowing that chunk sizes are varying between 1 and 4 MB and using random read with those sizes, over a 20 GB file (to spread it out), I tried to see what I get on this pool with 1 worker and more workers. Remember: primarycache=metadata on this recordset. Results below.
/rpool/pbs-storage/test# fio --rw=randread --name=TEST --size=20g --io_size=1g --bsrange=1M-4M --direct=1 --filename=temp.file --numjobs=1 --ioengine=libaio --iodepth=1 --refill_buffers --group_reporting --runtime=30 --time_based
TEST: (g=0): rw=randread, bs=(R) 1024KiB-4096KiB, (W) 1024KiB-4096KiB, (T) 1024KiB-4096KiB, ioengine=libaio, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=88.1MiB/s][r=47 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=619432: Fri Dec 20 19:31:28 2024
read: IOPS=41, BW=88.9MiB/s (93.2MB/s)(2669MiB/30015msec)
slat (usec): min=276, max=367035, avg=24155.35, stdev=16613.50
clat (nsec): min=2599, max=27571, avg=6167.52, stdev=2121.20
lat (usec): min=279, max=367043, avg=24161.52, stdev=16613.70
clat percentiles (nsec):
| 1.00th=[ 3408], 5.00th=[ 3920], 10.00th=[ 4048], 20.00th=[ 4192],
| 30.00th=[ 4448], 40.00th=[ 4704], 50.00th=[ 7200], 60.00th=[ 7392],
| 70.00th=[ 7520], 80.00th=[ 7648], 90.00th=[ 7904], 95.00th=[ 8256],
| 99.00th=[10816], 99.50th=[17280], 99.90th=[23168], 99.95th=[27520],
| 99.99th=[27520]
bw ( KiB/s): min=49152, max=114688, per=100.00%, avg=91083.93, stdev=9698.54, samples=59
iops : min= 20, max= 60, avg=41.25, stdev= 6.96, samples=59
lat (usec) : 4=7.57%, 10=91.22%, 20=0.89%, 50=0.32%
cpu : usr=0.04%, sys=3.28%, ctx=2620, majf=0, minf=1034
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=1242,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=88.9MiB/s (93.2MB/s), 88.9MiB/s-88.9MiB/s (93.2MB/s-93.2MB/s), io=2669MiB (2799MB), run=30015-30015msec
TEST: (g=0): rw=randread, bs=(R) 1024KiB-4096KiB, (W) 1024KiB-4096KiB, (T) 1024KiB-4096KiB, ioengine=libaio, iodepth=1
fio-3.33
Starting 1 process
Jobs: 1 (f=1): [r(1)][100.0%][r=88.1MiB/s][r=47 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=1): err= 0: pid=619432: Fri Dec 20 19:31:28 2024
read: IOPS=41, BW=88.9MiB/s (93.2MB/s)(2669MiB/30015msec)
slat (usec): min=276, max=367035, avg=24155.35, stdev=16613.50
clat (nsec): min=2599, max=27571, avg=6167.52, stdev=2121.20
lat (usec): min=279, max=367043, avg=24161.52, stdev=16613.70
clat percentiles (nsec):
| 1.00th=[ 3408], 5.00th=[ 3920], 10.00th=[ 4048], 20.00th=[ 4192],
| 30.00th=[ 4448], 40.00th=[ 4704], 50.00th=[ 7200], 60.00th=[ 7392],
| 70.00th=[ 7520], 80.00th=[ 7648], 90.00th=[ 7904], 95.00th=[ 8256],
| 99.00th=[10816], 99.50th=[17280], 99.90th=[23168], 99.95th=[27520],
| 99.99th=[27520]
bw ( KiB/s): min=49152, max=114688, per=100.00%, avg=91083.93, stdev=9698.54, samples=59
iops : min= 20, max= 60, avg=41.25, stdev= 6.96, samples=59
lat (usec) : 4=7.57%, 10=91.22%, 20=0.89%, 50=0.32%
cpu : usr=0.04%, sys=3.28%, ctx=2620, majf=0, minf=1034
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=1242,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=88.9MiB/s (93.2MB/s), 88.9MiB/s-88.9MiB/s (93.2MB/s-93.2MB/s), io=2669MiB (2799MB), run=30015-30015msec
/rpool/pbs-storage/test# fio --rw=randread --name=TEST --size=20g --io_size=1g --bsrange=1M-4M --direct=1 --filename=temp.file --numjobs=32 --ioengine=libaio --iodepth=1 --refill_buffers --group_reporting --runtime=30 --time_based
TEST: (g=0): rw=randread, bs=(R) 1024KiB-4096KiB, (W) 1024KiB-4096KiB, (T) 1024KiB-4096KiB, ioengine=libaio, iodepth=1
...
fio-3.33
Starting 32 processes
Jobs: 32 (f=32): [r(32)][100.0%][r=913MiB/s][r=403 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=32): err= 0: pid=619182: Fri Dec 20 19:30:29 2024
read: IOPS=383, BW=911MiB/s (956MB/s)(26.8GiB/30117msec)
slat (usec): min=165, max=422678, avg=83196.28, stdev=56514.57
clat (nsec): min=1490, max=39093, avg=5770.85, stdev=2378.88
lat (usec): min=166, max=422683, avg=83202.05, stdev=56514.85
clat percentiles (nsec):
| 1.00th=[ 2544], 5.00th=[ 3216], 10.00th=[ 3600], 20.00th=[ 4080],
| 30.00th=[ 4448], 40.00th=[ 4832], 50.00th=[ 5216], 60.00th=[ 5664],
| 70.00th=[ 6304], 80.00th=[ 7520], 90.00th=[ 8512], 95.00th=[ 9408],
| 99.00th=[14528], 99.50th=[18816], 99.90th=[27008], 99.95th=[29056],
| 99.99th=[31104]
bw ( KiB/s): min=475136, max=1490944, per=100.00%, avg=933464.50, stdev=6640.95, samples=1917
iops : min= 174, max= 684, avg=384.12, stdev= 3.43, samples=1917
lat (usec) : 2=0.15%, 4=18.00%, 10=79.23%, 20=2.29%, 50=0.33%
cpu : usr=0.01%, sys=1.10%, ctx=27280, majf=0, minf=33036
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=11560,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=911MiB/s (956MB/s), 911MiB/s-911MiB/s (956MB/s-956MB/s), io=26.8GiB (28.8GB), run=30117-30117msec
TEST: (g=0): rw=randread, bs=(R) 1024KiB-4096KiB, (W) 1024KiB-4096KiB, (T) 1024KiB-4096KiB, ioengine=libaio, iodepth=1
...
fio-3.33
Starting 32 processes
Jobs: 32 (f=32): [r(32)][100.0%][r=913MiB/s][r=403 IOPS][eta 00m:00s]
TEST: (groupid=0, jobs=32): err= 0: pid=619182: Fri Dec 20 19:30:29 2024
read: IOPS=383, BW=911MiB/s (956MB/s)(26.8GiB/30117msec)
slat (usec): min=165, max=422678, avg=83196.28, stdev=56514.57
clat (nsec): min=1490, max=39093, avg=5770.85, stdev=2378.88
lat (usec): min=166, max=422683, avg=83202.05, stdev=56514.85
clat percentiles (nsec):
| 1.00th=[ 2544], 5.00th=[ 3216], 10.00th=[ 3600], 20.00th=[ 4080],
| 30.00th=[ 4448], 40.00th=[ 4832], 50.00th=[ 5216], 60.00th=[ 5664],
| 70.00th=[ 6304], 80.00th=[ 7520], 90.00th=[ 8512], 95.00th=[ 9408],
| 99.00th=[14528], 99.50th=[18816], 99.90th=[27008], 99.95th=[29056],
| 99.99th=[31104]
bw ( KiB/s): min=475136, max=1490944, per=100.00%, avg=933464.50, stdev=6640.95, samples=1917
iops : min= 174, max= 684, avg=384.12, stdev= 3.43, samples=1917
lat (usec) : 2=0.15%, 4=18.00%, 10=79.23%, 20=2.29%, 50=0.33%
cpu : usr=0.01%, sys=1.10%, ctx=27280, majf=0, minf=33036
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=11560,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=911MiB/s (956MB/s), 911MiB/s-911MiB/s (956MB/s-956MB/s), io=26.8GiB (28.8GB), run=30117-30117msec
Looking at the first test, I'm getting barely 100 MB/s. I don't know if this is what PBS is doing (scanning chunks sequentially, one at a time) but the speed I'm getting suggests that could be the case.
Let's look at the second test. As I increase the number of workers so does the speed increase and by a lot - showing this pool can do much better. With 32 workers I'm getting over 900 MB/s. A much better result. So this pool seems to be able to do random reads of 1-4 MB sizes pretty darn well - provided enough workers are doing it in parallel.
With 16 workers it's 450-500 MB/s, but fio tests are showing clearly that it grows with more parallelism.
So... is PBS doing that chunk verification in parallel ? I don't really know - but looking at the speed and CPU usage I'd guess it's not. If so... well, could that change ? How difficult would that be, let's see: all a thread needs to do is read a chunk, calculate it's hash and save the result somewhere in memory. Ok nothing complex. In .NET I'd probably use something from thread-safe collections (like a ConcurrentQueue) to keep the list of chunks that need to be checked, then have a number of workers (that PBS admin could configure) empty that queue in parallel. Each thread doing a verify of a single chunk and putting results in a ConcurrentDictionary. That's easy. And that would make verify run on chunks in parallel (.NET has thread-safe classes ready to use so I mention them because I use .NET, but same can be achieved in other ways, with whatever you use for this bit of thread synchronization in language PBS is written in - but even manual locking would work fine here, as there's very little overlapping: dequeue an item & save a boolean result, those are the only points needing thread synchronization, trivial to achieve).
Question: is PBS already doing chunk verification in parallel ?
If yes: how many threads are being used and is there an option to configure that number ?
If not: could you consider adding that ?
I believe there are other places chunk verification could improve. Like if I'm running a verify of a VM and I have 20 snapshots/backup copies of that VM - and in that 20 copies >90% of all chunks are actually shared between copies, then perhaps we don't have to check the same chunk 20 times for each copy ? I don't know if this is already done that way, maybe it is - but looking at the time it takes for verification I'm not sure... I may be mistaken on this one.
Damn, perhaps I should really take a look at the sources before commenting, but I don't know what PBS is written in and I'm not so sure I'd be able to follow it...
I actually have a verify job running at this very moment... Peeking with htop shows this:

Ok, no parallelism. Clear candidate for improvement. And low hanging fruit, this one.
Cheers
Ok, no parallelism. Clear candidate for improvement. And low hanging fruit, this one.
Cheers
Ok, I made a test with Veeam and I'm posting my results here, as I previously mentioned.
Same hardware as before - no tweaks or changes to anything. What I did:
- installed a Windows VM on the backup host (where PBS lives) and installed Veeam B&R inside
- installed a CT and gave it 8 TB ZFS dataset (the ZFS dataset is configured in exactly the same way as the ZFS dataset holding the PBS datastore; recordsize=1M, primarycache=metadata and using same zpool as PBS of course)
- installed the helper VM-s on both PVE hosts (this is how Veeam works, it uses on-host helper VM-s for processing source data and transferring it to backup targets directly)
- I then backed up 2 VCM-s from both PVE hosts for test
- then made a restore of 1 of those VM-s for test
Results?
Backup speeds are somewhat on par (albeit a bit slower) with Veeam than with PBS. PBS is faster in backing up, it's not a huge difference, but it is faster than Veeam.
Restore speed of a test VM ? 400 MB/s. Check the attached screenshot from PBS host where Veeam server was running the restore (see the graph, I took the screenshot right when restore finished, so numbers fell down at that point, but graph shows it nicely). And that's network transfer speed (compressed backup data is transferred, which is decompressed on a helper VM that Veeam uses for on-host backup processing, before it's put in the VM disk, which the helper VM mounts while restore is ongoing).
Again, same hardware, same ZFS setup. 400 MB/s restore speed with Veeam compared to 30-50 MB/s with PBS (the other screenshot is a PBS restore of that same VM, that I did after the Veeam restore, just to be sure those numbers are true).
This test was a restore of a single VM to a single PVE host. Restore speed equals backup speed with Veeam (backup speed was actually faster, because 2 hosts were backing up at the same time and with restore I tested only a single VM - to a single host). But this speed is good. 43 minutes per TB is much more acceptable than 10 hours, that's a huge difference.
Now... it would be nice if Proxmox staff could refrain from trying hard to focus on any possible issue in user setup, when people report slow restores (like your CPU is probably too slow, or use all-flash for backup - who uses all flash for backups anyway ?) and instead focus more on actual PBS implementation - which is, obviously, where the slowness comes from. Not our hardware.
Cheers
Same hardware as before - no tweaks or changes to anything. What I did:
- installed a Windows VM on the backup host (where PBS lives) and installed Veeam B&R inside
- installed a CT and gave it 8 TB ZFS dataset (the ZFS dataset is configured in exactly the same way as the ZFS dataset holding the PBS datastore; recordsize=1M, primarycache=metadata and using same zpool as PBS of course)
- installed the helper VM-s on both PVE hosts (this is how Veeam works, it uses on-host helper VM-s for processing source data and transferring it to backup targets directly)
- I then backed up 2 VCM-s from both PVE hosts for test
- then made a restore of 1 of those VM-s for test
Results?
Backup speeds are somewhat on par (albeit a bit slower) with Veeam than with PBS. PBS is faster in backing up, it's not a huge difference, but it is faster than Veeam.
Restore speed of a test VM ? 400 MB/s. Check the attached screenshot from PBS host where Veeam server was running the restore (see the graph, I took the screenshot right when restore finished, so numbers fell down at that point, but graph shows it nicely). And that's network transfer speed (compressed backup data is transferred, which is decompressed on a helper VM that Veeam uses for on-host backup processing, before it's put in the VM disk, which the helper VM mounts while restore is ongoing).
Again, same hardware, same ZFS setup. 400 MB/s restore speed with Veeam compared to 30-50 MB/s with PBS (the other screenshot is a PBS restore of that same VM, that I did after the Veeam restore, just to be sure those numbers are true).
This test was a restore of a single VM to a single PVE host. Restore speed equals backup speed with Veeam (backup speed was actually faster, because 2 hosts were backing up at the same time and with restore I tested only a single VM - to a single host). But this speed is good. 43 minutes per TB is much more acceptable than 10 hours, that's a huge difference.
Now... it would be nice if Proxmox staff could refrain from trying hard to focus on any possible issue in user setup, when people report slow restores (like your CPU is probably too slow, or use all-flash for backup - who uses all flash for backups anyway ?) and instead focus more on actual PBS implementation - which is, obviously, where the slowness comes from. Not our hardware.
Cheers
Attachments
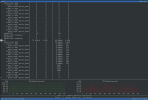
Last edited:
A couple of notes about using Veeam to backup PVE.
I didn't know, but Veeam B&R doesn't currently support backing up CT-s. This is not good as CT-s are my favorite way of running Linux machines.
Another issue is Veeam doesn't support application-aware backups on Proxmox. I don't know if they are planning to, but PBS does it. PBS does trigger a VSS snapshot inside Windows guests and will do something similar with Linux guests (I'm not sure what it does with CTs, to be honest, didn't check).
These two points are kind of serious drawbacks for using Veeam (besides Veeam being quite pricey and offering only subscription-based licensing now).
So I'm left with a problem. Veeam doesn't offer backing up CT-s and doesn't offer consistent backups for VMs. This might change, as support for PVE is kind of new, but currently it is what it is. Far from perfect. It uses hardware much better to provide speedy restores, but is missing on these other points. I also don't know how stable it is in backing up PVE.
I'd like to know what you guys are using to backup PVE ?
Cheers
I didn't know, but Veeam B&R doesn't currently support backing up CT-s. This is not good as CT-s are my favorite way of running Linux machines.
Another issue is Veeam doesn't support application-aware backups on Proxmox. I don't know if they are planning to, but PBS does it. PBS does trigger a VSS snapshot inside Windows guests and will do something similar with Linux guests (I'm not sure what it does with CTs, to be honest, didn't check).
These two points are kind of serious drawbacks for using Veeam (besides Veeam being quite pricey and offering only subscription-based licensing now).
So I'm left with a problem. Veeam doesn't offer backing up CT-s and doesn't offer consistent backups for VMs. This might change, as support for PVE is kind of new, but currently it is what it is. Far from perfect. It uses hardware much better to provide speedy restores, but is missing on these other points. I also don't know how stable it is in backing up PVE.
I'd like to know what you guys are using to backup PVE ?
Cheers
I'd like to know what you guys are using to backup PVE ?
We are using both Veeam and PBS, to get a 1:1 comparison. In our testing, which maybe I'll do a more concrete test soon, PBS has consistently backed up MUCH MUCH faster than Veeam. That's both in speed and reliability. I'm not sure why this is, but over the last 3 years of using Veeam, it's been the most temperamental piece of software I've ever used. I create on average 2 support tickets a month with Veeam because something broke and needs support to fix it, I've had them check over our setup multiple times and they've found nothing that would indicate it's on our side.
While PBS has backed up tens of thousands of snapshots without problem. It also has a much better dedupe/compression than Veeam.
In some testing in our network at work, I've been able to backup and restore VMs at a pretty good rate. An 80GB VM is backed up over the WAN to another site, and then restored in less than 2 minutes. We haven't had to do many restores, so I can't say that for sure in this environment, but I can say in my personal cluster at home I've had issues with restore speeds. Just last night I restore a 400GB Ubuntu VM that took 30 mins to backup, it took almost 2 hours to restore.
Is that important if you can start the VM while the restore is still going?Just last night I restore a 400GB Ubuntu VM that took 30 mins to backup, it took almost 2 hours to restore.
Is that important if you can start the VM while the restore is still going?
Well, in this case I highly doubt it'd boot in any reasonable amount of time at that speed. I guess I can try it and see what happens though.
I agree PVE backups to PBS are very fast. It's the restores that are VERY slow. As are verify operations.
I have noticed that if I make 2 verify jobs run in parallel, that I do get much better read speeds on the disk pool. I am not sure, though, if total time if shorter or not - because I am not sure if, when I'm running two verify jobs in parallel, I'm just doing the verify operation twice (not sure how locking works here), because that would kill the whole point. Also verify jobs don't have any filter options (like, verify job 1 could runs on even-numbered vms and verify job 2 on odd-numbered vms, or something like that) so I could get better verify speeds overall.
But verify jobs (as well as restore jobs) should really be refactored in a way to enable getting most of the underlying hardware, because hardware is capable of providing (much) better speeds. How and what needs to be changed I don't know. Hopefully, Proxmox staff will look into this, at some point.
I have noticed that if I make 2 verify jobs run in parallel, that I do get much better read speeds on the disk pool. I am not sure, though, if total time if shorter or not - because I am not sure if, when I'm running two verify jobs in parallel, I'm just doing the verify operation twice (not sure how locking works here), because that would kill the whole point. Also verify jobs don't have any filter options (like, verify job 1 could runs on even-numbered vms and verify job 2 on odd-numbered vms, or something like that) so I could get better verify speeds overall.
But verify jobs (as well as restore jobs) should really be refactored in a way to enable getting most of the underlying hardware, because hardware is capable of providing (much) better speeds. How and what needs to be changed I don't know. Hopefully, Proxmox staff will look into this, at some point.
I tried Veeam on PVE -> MUCH better restore speeds, but Veeam doesn't backup LXCs. And I use LXCs (besides VMs).