Thanks
@Dunuin for your reply!
Ok. I'm using my best Google-Fu to digest the concepts.
So... My original idea of joining the entire 1 TB SSD with the 2 TB HDD in the same pool makes no sense. I had hopes that I wouldn't have to split data manually between them, but it seems like I'll have to, for best performance, moving frequently used data in the SSD and least used data in the HDD.
I also see that with the thin provisioning of LVM-Thin I'll have to closely monitor the space. Otherwise if it gets full, the result is catastrophic, usually beyond repair of the affected VMs, according to
this source.
Now digesting ZFS options:
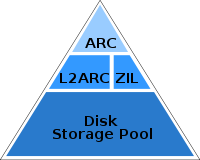
1) So the ARC is mandatory for ZFS. It takes a varying amount of the primary memory (which I will call as RAM). But it's only beneficial to repeatedly reading the same file.
By default, the ARC would use 1 to 16 GB of a 32 GB system. But it can be limited. The rule is 1 GB of RAM per each TB of disk space, which is taking
0.1% of the HDD space from the RAM. But the rule also asks additional X GB of RAM regardless of the disk space. The recommendation for X varies between 2 GB and 8 GB, depending on the source. However,
this video explains that smaller amounts of ARC will also work, and more L2ARC can make up for the RAM limitation.
2) The L2ARC would be optional. Another cache layer, to be stored in the SSD. And it also increases the need for RAM memory and the RAM memory pressure since the L2ARC is indexed in RAM. So L2ARC is only recommended if ARC hit is below 90% and the ARC size can't be increased further because there isn't enough RAM memory. The L2ARC size should be tuned around 3x to 10x the size of the ARC, being 5x the most common ratio. So it usually takes around
0.5-1% of the HDD space from the SSD.
3) The special disk would bring metadata of the HDD to the SSD, greatly increasing performance, and that takes very little space. Adding small blocks to the SSD takes more space, but yet the required size is small. It's recommended to store files only up to 64k at max. Otherwise the default ZFS block size of 128k would have to be increased, which would negatively affect performance and space usage. By the end, the special disk usually takes around
3% of the HDD space from the SSD.
4) The compression is optional, but will certainly accelerate HDDs, especially on read access. Except in very specific case were the bottleneck is the CPU instead of the HDD speed.
5) When compressing NVMe, it may or not be useful, as explained
in this 2020 Proxmox article:
- They selected a unit which is known to do 3500 MB/s for read and write without compression, but the testing is about small files of 4k. For those, it was benchmarked it at 205 MB/s bandwidth and 51k IO/s.
- Then, after compression benchmarks, that bandwidth goes up to 500 MB/s for single job. In the case of concurrency it goes much higher, up to almost 3000 MB/s read speed in the case of 32x jobs.
- For the IO/s value, it can be better or worse, depending on the case.
- For a single job, it decreases to 7k - 2k IO/s.
- For 32x jobs, it triplicates read to 150k IO/s and drops write a bit, to 40k IO/s.
To better evaluate if it would be worth using compression in NVMe, I found this
quote:
"While IOPS was important when measuring hard drive performance, most real-world situations do not require more than a thousand inputs/outputs per second. Therefore, IOPS is rarely viewed as an important metric in SSD performance."
Those tests didn't benchmark latency increase due to compression, but it seems fine since IO/s is still acceptable. Since
Average IO size x IOPS = Throughput in MB/s, we can assume the average IO size has increased dramatically.
Their CPU has 2.6x more cores than a i5-12400, and they had 4x more memory than 32 GB RAM, but memory speed was the same (DDR4-3200) and the i5-12400 CPU single core speed is actually 75% faster, so my compression should be OK for my hardware.
==
Conclusions:
I still need to evaluate if ZFS in NVMe SSDs is worth since it will spare 20% of the SSD space plus some RAM, just for performance gains, but the SSD does not allow for so much performance gain as in the case of HDD. Because the SSDs do 2400 MB/s and 7000 MB/s, which is closer to the DDR4-3200 memory bandwidth of 25600 MB/s, while the HDDs does around 190 MB/s only. Also, DDR4 latency is in the range of
a few nanoseconds while HDD latency is in the range of
a few milliseconds, which is a million times more, but PCIe NVMe SSDs are in the middle range, with a few microseconds of latency. The table below summarizes this:
| DDR4-3200 memory | PCIe 4 NVMe SSD | PCIe 3 NVMe SSD | HDDs |
| Latency | a few nanoseconds | a few microseconds | a few microseconds | a few milliseconds |
| 1 | x1,000 | x1,000 | x1,000,000 |
| Bandwidth | 25,600 MB/s | 7000 MB/s | 2400 MB/s | 190 MB/s |
| 1 | x 1 / 3.6 | x 1 / 10 | x 1 / 135 |
| x135 | x37 | x13 | 1 |
In logarithmic scale:

==
With that, I created a new draft schema (probably still with mistakes):

Another thing I need to decide is in which device Proxmox will be installed. I would want to install it in a way that won't change the structure above.
It's
documentation says it can be installed in a ext4, XFS, BTRFS, or ZFS partition. And when using ex4 or XFS, then LVM is used, and it will take at least 4 GB or RAM. But it's unclear for me if that means it can go in the SSD side-by-side with the LVM-Thin pool, or if it would adding another layer of abstraction before the LVM and degrade performance. For best results, should I then use a spare HDD just for Proxmox?




")