Hi all!
I've discovered an issue with VXLAN and routing, and I'm not sure if it's because my setup is wrong/weird or if it's a bug (possibly in the kernel).
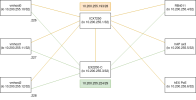
My setup is:
I've discovered on a tcpdump on vmhost0, that vmhost0 sends a packet to the correct new node IP, but to the wrong MAC:
Looking at the ARP cache, the :bb MAC belongs to the IP that's on vmhost1 ethernet interface (and routes to .11), but the destination IP of the packet has correctly changed to .12 (vmhost2)
Like said before, the ping's between the vmhosts work at all times, and the pings between the VMs start working if the traffic stops for some time (haven't measured exactly how long). I've also discovered that the test-VM ping starts working after flushing the route cache with
I've attached my FRR config, please let me know if you need the other files to reproduce or any other logs/tests.
Thanks!
EDIT: here is the same issue from 4 years ago: https://www.reddit.com/r/networking/comments/ck8zin/issues_with_vxlan_live_migration_in_linux/
I've discovered an issue with VXLAN and routing, and I'm not sure if it's because my setup is wrong/weird or if it's a bug (possibly in the kernel).
My setup is:
- Three nodes in a cluster, each node has an /32 address on loopback lo: vmhost0 10.200.255.10/32, vmhost1 10.200.255.11/32 and vmhost2 10.200.255.12/32.
- Their ethernet ports are connected to a L3 switch with a shared /29: sw-rack03 10.200.255.225/29, vmhost0 10.200.255.226/29 (and so on).
- The nodes run FRR ospfd, together with the switch. The route table on e.g. vmhost0 thus looks like:
Code:[...] 10.200.255.3 nhid 197 via 10.200.255.225 dev enp5s0.2224 proto ospf metric 20 # sw-rack03 lo loopback 10.200.255.4 nhid 203 via 10.200.255.229 dev enp5s0.2224 proto ospf metric 20 # MikroTik Test loopback 10.200.255.11 nhid 199 via 10.200.255.227 dev enp5s0.2224 proto ospf metric 20 # vmhost1 loopback 10.200.255.12 nhid 201 via 10.200.255.228 dev enp5s0.2224 proto ospf metric 20 # vmhost2 loopback 10.200.255.224/29 dev enp5s0.2224 proto kernel scope link src 10.200.255.226 [...] - I've added
vxlan-local-tunnelip 10.200.255.10to the vxlan tunnel interface, the remote VTEPs are the other loopback IPs. - The plan is to later add a second L3 switch and network to the nodes, so that the loopback IP becomes available via multiple links, devices and routes.
- I have a VM on vmhost0 (named test1) and a VM that I migrate between vmhost1 and vmhost2 (named test3).
- In general, this works, I can ping the loopback IPs at all times, the VXLAN-based bridge works and the VMs can ping each other.
- I'm forced to run simple VXLAN zones because MikroTik doesn't support EVPN-VXLAN.
I've discovered on a tcpdump on vmhost0, that vmhost0 sends a packet to the correct new node IP, but to the wrong MAC:
Code:
# outer VXLAN packet
08:53:47.444715 a8:a1:59:2a:39:77 > a8:a1:59:1a:85:bb, ethertype 802.1Q (0x8100), length 156: vlan 2224, p 0, ethertype IPv4 (0x0800), (tos 0x0, ttl 64, id 61195, offset 0, flags [none], proto UDP (17), length138)
10.200.255.10.42858 > 10.200.255.12.4789: VXLAN, flags [I] (0x08), vni 200
# inner packet
c2:6d:71:ba:bd:09 > bc:24:11:21:c4:d4, ethertype 802.1Q (0x8100), length 102: vlan 40, p 0, ethertype IPv4 (0x0800), (tos 0x0, ttl 64, id 59902, offset 0, flags [DF], proto ICMP (1), length 84)
10.200.201.1 > 10.200.201.2: ICMP echo request, id 53466, seq 1660, length 64
Code:
10.200.255.228 ether a8:a1:59:41:6a:61 C enp5s0.2224
10.200.255.227 ether a8:a1:59:1a:85:bb C enp5s0.2224Like said before, the ping's between the vmhosts work at all times, and the pings between the VMs start working if the traffic stops for some time (haven't measured exactly how long). I've also discovered that the test-VM ping starts working after flushing the route cache with
ip route flush cache. It also works if I enable ip_forwarding on vmhost1.I've attached my FRR config, please let me know if you need the other files to reproduce or any other logs/tests.
Thanks!
EDIT: here is the same issue from 4 years ago: https://www.reddit.com/r/networking/comments/ck8zin/issues_with_vxlan_live_migration_in_linux/
Last edited:
")