Hi all,
I hope anyone can shed some light into this nightmare.
I was happily using my VM when the entire node crashed for no apparent reason.
As of that, every time I start this (Only) VM on the node, it starts up, starts loading winserver2016 and all of a sudden, the ENTIRE node crashes and forces a reboot of the server.
I will run some tests as soon as it's back, but has anyone get this problem before?
Log here:
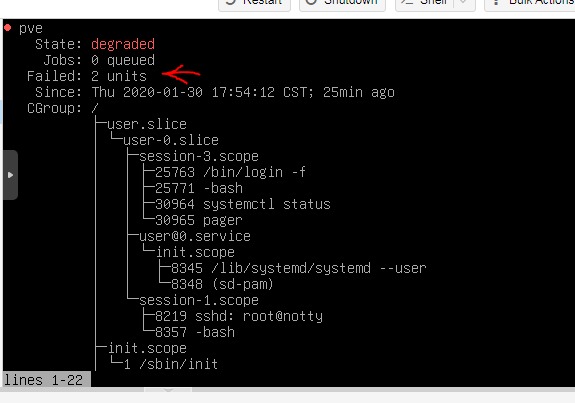
Looks like the pve is degraded, any tips?
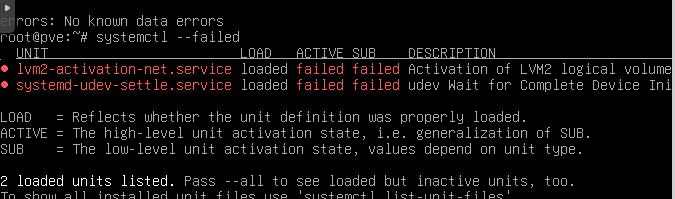
I think I found the problem can anyone point me in the right direction? Also I'm not actually using LVM I'm using ZFS is it normal for this service to show up like this?
This may be important:
This is just a node, and the only node there is.
PVE VERSION:
QM CONFIG:
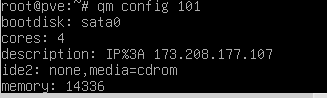
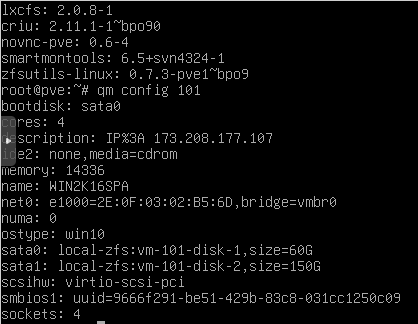
SOLUTION ( KIND OF):
1) I cloned the VM 101 into VM100 and worked on the clone just in case.
2) Dettached both SATA drives.
3) Re-attached both drives as SCSI.
4) Dettached both SCSI drives.
5) Re-attached both drives as SATA
The cloned vm started up, windows 2016 server takes a LONG time booting and the "loading" circle gets stuck multiple times, it takes around 30 minutes to start, but once it starts everything works ok.
Iwasn't able to run any more tests on the original VM as I really needed to get this working real fast and I didn't want to risk more reboots.
THanks!
I hope anyone can shed some light into this nightmare.
I was happily using my VM when the entire node crashed for no apparent reason.
As of that, every time I start this (Only) VM on the node, it starts up, starts loading winserver2016 and all of a sudden, the ENTIRE node crashes and forces a reboot of the server.
I will run some tests as soon as it's back, but has anyone get this problem before?
Log here:
Code:
Jan 30 17:11:51 pve systemd-timesyncd[4585]: Synchronized to time server 216.229.0.49:123 (0.debian.pool.ntp.org).
Jan 30 17:12:00 pve systemd[1]: Starting Proxmox VE replication runner...
Jan 30 17:12:00 pve pvesr[6767]: ipcc_send_rec[1] failed: Connection refused
Jan 30 17:12:00 pve pvesr[6767]: ipcc_send_rec[2] failed: Connection refused
Jan 30 17:12:00 pve pvesr[6767]: ipcc_send_rec[3] failed: Connection refused
Jan 30 17:12:00 pve pvesr[6767]: Unable to load access control list: Connection refused
Jan 30 17:12:00 pve systemd[1]: pvesr.service: Main process exited, code=exited, status=111/n/a
Jan 30 17:12:00 pve systemd[1]: Failed to start Proxmox VE replication runner.
Jan 30 17:12:00 pve systemd[1]: pvesr.service: Unit entered failed state.
Jan 30 17:12:00 pve systemd[1]: pvesr.service: Failed with result 'exit-code'.
Jan 30 17:13:00 pve systemd[1]: Starting Proxmox VE replication runner...
Jan 30 17:13:00 pve pvesr[7167]: ipcc_send_rec[1] failed: Connection refused
Jan 30 17:13:00 pve pvesr[7167]: ipcc_send_rec[2] failed: Connection refused
Jan 30 17:13:00 pve pvesr[7167]: ipcc_send_rec[3] failed: Connection refused
Jan 30 17:13:00 pve pvesr[7167]: Unable to load access control list: Connection refused
Jan 30 17:13:00 pve systemd[1]: pvesr.service: Main process exited, code=exited, status=111/n/a
Jan 30 17:13:00 pve systemd[1]: Failed to start Proxmox VE replication runner.
Jan 30 17:13:01 pve systemd[1]: pvesr.service: Unit entered failed state.
Jan 30 17:13:01 pve systemd[1]: pvesr.service: Failed with result 'exit-code'.
Jan 30 17:13:34 pve kernel: [ 363.106633] INFO: task systemd-udevd:4065 blocked for more than 120 seconds.
Jan 30 17:13:34 pve kernel: [ 363.108165] Tainted: P IO 4.13.13-2-pve #1
Jan 30 17:13:34 pve kernel: [ 363.108870] "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jan 30 17:13:34 pve kernel: [ 363.109591] systemd-udevd D 0 4065 3952 0x00000104
Jan 30 17:13:34 pve kernel: [ 363.109594] Call Trace:
Jan 30 17:13:34 pve kernel: [ 363.109605] __schedule+0x3cc/0x860
Jan 30 17:13:34 pve kernel: [ 363.109609] schedule+0x36/0x80
Jan 30 17:13:34 pve kernel: [ 363.109613] get_guid+0xf7/0x130 [ipmi_msghandler]
Jan 30 17:13:34 pve kernel: [ 363.109617] ? wait_woken+0x80/0x80
Jan 30 17:13:34 pve kernel: [ 363.109619] ipmi_register_smi+0x410/0x954 [ipmi_msghandler]
Jan 30 17:13:34 pve kernel: [ 363.109626] ? try_smi_init+0x57e/0x9a0 [ipmi_si]
Jan 30 17:13:34 pve kernel: [ 363.109629] try_smi_init+0x5f2/0x9a0 [ipmi_si]
Jan 30 17:13:34 pve kernel: [ 363.109632] ? std_irq_setup+0xd0/0xd0 [ipmi_si]
Jan 30 17:13:34 pve kernel: [ 363.109635] init_ipmi_si+0x36f/0x790 [ipmi_si]
Jan 30 17:13:34 pve kernel: [ 363.109638] ? ipmi_probe+0x420/0x420 [ipmi_si]
Jan 30 17:13:34 pve kernel: [ 363.109642] do_one_initcall+0x52/0x1b0
Jan 30 17:13:34 pve kernel: [ 363.109644] ? kmem_cache_alloc_trace+0xf8/0x1a0
Jan 30 17:13:34 pve kernel: [ 363.109646] do_init_module+0x5f/0x209
Jan 30 17:13:34 pve kernel: [ 363.109648] load_module+0x2934/0x2ec0
Jan 30 17:13:34 pve kernel: [ 363.109652] ? ima_post_read_file+0x7e/0xa0
Jan 30 17:13:34 pve kernel: [ 363.109654] ? security_kernel_post_read_file+0x6b/0x80
Jan 30 17:13:34 pve kernel: [ 363.109656] SYSC_finit_module+0xe5/0x120
Jan 30 17:13:34 pve kernel: [ 363.109657] ? SYSC_finit_module+0xe5/0x120
Jan 30 17:13:34 pve kernel: [ 363.109659] SyS_finit_module+0xe/0x10
Jan 30 17:13:34 pve kernel: [ 363.109661] do_syscall_64+0x5b/0xc0
Jan 30 17:13:34 pve kernel: [ 363.109663] entry_SYSCALL64_slow_path+0x25/0x25
Jan 30 17:13:34 pve kernel: [ 363.109664] RIP: 0033:0x7f6114055259
Jan 30 17:13:34 pve kernel: [ 363.109665] RSP: 002b:00007fff90ca1828 EFLAGS: 00000246 ORIG_RAX: 0000000000000139
Jan 30 17:13:34 pve kernel: [ 363.109666] RAX: ffffffffffffffda RBX: 00005636eeb006a0 RCX: 00007f6114055259
Jan 30 17:13:34 pve kernel: [ 363.109667] RDX: 0000000000000000 RSI: 00007f611496e265 RDI: 0000000000000010
Jan 30 17:13:34 pve kernel: [ 363.109668] RBP: 00007f611496e265 R08: 0000000000000000 R09: 00007fff90ca1da0
Jan 30 17:13:34 pve kernel: [ 363.109669] R10: 0000000000000010 R11: 0000000000000246 R12: 0000000000000000
Jan 30 17:13:34 pve kernel: [ 363.109670] R13: 00005636eeaffd40 R14: 0000000000020000 R15: 00005636ed29ac7c
Jan 30 17:13:46 pve systemd[1]: lvm2-activation-net.service: Control process exited, code=exited status=1
Jan 30 17:13:46 pve systemd[1]: Failed to start Activation of LVM2 logical volumes.
Jan 30 17:13:46 pve systemd[1]: lvm2-activation-net.service: Unit entered failed state.
Jan 30 17:13:46 pve systemd[1]: lvm2-activation-net.service: Failed with result 'exit-code'.
Jan 30 17:13:46 pve systemd[1]: Reached target Remote File Systems (Pre).
Jan 30 17:13:47 pve systemd[1]: Reached target Remote File Systems.
Jan 30 17:13:47 pve systemd[1]: Reached target PVE Storage Target.
Jan 30 17:13:47 pve systemd[1]: Starting LSB: Ceph RBD Mapping...
Jan 30 17:13:47 pve systemd[1]: Starting Permit User Sessions...
Jan 30 17:13:47 pve systemd[1]: Starting LSB: start or stop rrdcached...
Jan 30 17:13:47 pve systemd[1]: Started Permit User Sessions.
Jan 30 17:13:47 pve systemd[1]: Started Getty on tty1.
Jan 30 17:13:47 pve systemd[1]: Reached target Login Prompts.
Jan 30 17:13:47 pve systemd[1]: Started LSB: Ceph RBD Mapping.
Jan 30 17:13:47 pve rrdcached[7468]: starting upLooks like the pve is degraded, any tips?
I think I found the problem can anyone point me in the right direction? Also I'm not actually using LVM I'm using ZFS is it normal for this service to show up like this?
This may be important:
Code:
Jan 30 06:25:00 pve systemd[1]: Started Proxmox VE replication runner.
Jan 30 06:25:02 pve CRON[29411]: (root) CMD (test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ))
Jan 30 06:25:02 pve systemd[1]: Reloading PVE API Proxy Server.
Jan 30 06:25:04 pve pveproxy[29501]: send HUP to 3376
Jan 30 06:25:04 pve pveproxy[3376]: received signal HUP
Jan 30 06:25:04 pve pveproxy[3376]: server closing
Jan 30 06:25:04 pve pveproxy[3376]: server shutdown (restart)
Jan 30 06:25:04 pve systemd[1]: Reloaded PVE API Proxy Server.
Jan 30 06:25:04 pve systemd[1]: Reloading PVE SPICE Proxy Server.
Jan 30 06:25:04 pve spiceproxy[29759]: send HUP to 3412
Jan 30 06:25:04 pve spiceproxy[3412]: received signal HUP
Jan 30 06:25:04 pve spiceproxy[3412]: server closing
Jan 30 06:25:04 pve spiceproxy[3412]: server shutdown (restart)
Jan 30 06:25:04 pve systemd[1]: Reloaded PVE SPICE Proxy Server.
Jan 30 06:25:05 pve systemd[1]: Stopping Proxmox VE firewall logger...
Jan 30 06:25:05 pve pvefw-logger[25334]: received terminate request (signal)
Jan 30 06:25:05 pve pvefw-logger[25334]: stopping pvefw logger
Jan 30 06:25:05 pve systemd[1]: Stopped Proxmox VE firewall logger.
Jan 30 06:25:05 pve systemd[1]: Starting Proxmox VE firewall logger...
Jan 30 06:25:05 pve systemd[1]: Started Proxmox VE firewall logger.
Jan 30 06:25:05 pve pvefw-logger[29798]: starting pvefw logger
Jan 30 06:25:05 pve pveproxy[3376]: restarting server
Jan 30 06:25:05 pve pveproxy[3376]: starting 3 worker(s)
Jan 30 06:25:05 pve pveproxy[3376]: worker 29808 started
Jan 30 06:25:05 pve pveproxy[3376]: worker 29809 started
Jan 30 06:25:05 pve pveproxy[3376]: worker 29810 startedThis is just a node, and the only node there is.
PVE VERSION:
QM CONFIG:
SOLUTION ( KIND OF):
1) I cloned the VM 101 into VM100 and worked on the clone just in case.
2) Dettached both SATA drives.
3) Re-attached both drives as SCSI.
4) Dettached both SCSI drives.
5) Re-attached both drives as SATA
The cloned vm started up, windows 2016 server takes a LONG time booting and the "loading" circle gets stuck multiple times, it takes around 30 minutes to start, but once it starts everything works ok.
Iwasn't able to run any more tests on the original VM as I really needed to get this working real fast and I didn't want to risk more reboots.
THanks!
Last edited: