I am new to Proxmox and trying to configured a test setup on some servers we have spare to get familiar before we order 2 machines specific for it.
We have 2 Dell r740xd servers with
We have a 10gbe connection between the 2 servers and using iperf i can confirm this is working and transmitting at 10gbps
When we are backup up a 450gb VM it is taking around 45 minutes and the data transfer is not reaching anywhere near the speeds we would expect network wise and the write and read speeds on average around 150-200mbps.
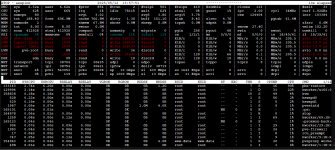
Then when trying to restore it is taking around 1.5hrs. When the restore is processing i loaded atop and saw the pbs-restore is nearly maxing the CPU core (im assuming just a single core) and the LVM is at 100%
So i guess my questions are
What could be causing the bottleneck in this setup
Any help or suggestions would be appreciated
We have 2 Dell r740xd servers with
- Xeon Gold 6240 CPU
- 192gb RAM
- 2 x 1GB SAS SSD in Raid 1 for the OS
- 10 x Dell SAS 4TB drives in RAID 5
- PERC H740P RAID Controller (RAID MODE)
I have one machine configured as the VE and this is formatted as EXT4
The other is configured as the Backup Server and it also formatted to EXT4
We have a 10gbe connection between the 2 servers and using iperf i can confirm this is working and transmitting at 10gbps
When we are backup up a 450gb VM it is taking around 45 minutes and the data transfer is not reaching anywhere near the speeds we would expect network wise and the write and read speeds on average around 150-200mbps.
Then when trying to restore it is taking around 1.5hrs. When the restore is processing i loaded atop and saw the pbs-restore is nearly maxing the CPU core (im assuming just a single core) and the LVM is at 100%
So i guess my questions are
What could be causing the bottleneck in this setup
- The SAS spinning disks?
- The way the partitions are formatted i.e EXT4 or ZFS?
- Is the Virtual drives been configured in RAID by the raid controller an issue?
Any help or suggestions would be appreciated