Hello,
I am still quarreling around with some wired io performance issues where I could not find any likly issue match in this forum.
Since Proxmox 4.4 or so (now running Proxmox 5) the disk io of our seems to be incredible bad. iostat show that the disk with the zfs pools for our vms drop to a few MB throughput while the wait time increase. we are using a z2 raid build with four disks (Enterprise SATA disk) in combination with SSDs for ZIL and ARC2.
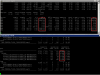
avg-cpu: %user %nice %system %iowait %steal %idle
15.55 0.00 7.84 33.38 0.00 43.24
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 38.00 603.00 2308.00 2708.00 15.65 4.52 3.78 26.74 2.33 1.56 100.00
sdb 0.00 0.00 40.00 608.00 1652.00 2724.00 13.51 5.68 4.47 34.70 2.48 1.54 100.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.00 67.00 66.00 0.00 536.00 8.06 0.05 0.39 0.78 0.00 0.39 5.20
sdf 0.00 0.00 67.00 85.00 0.00 2516.00 33.11 0.08 0.55 1.07 0.14 0.53 8.00
sdg 0.00 0.00 30.00 607.00 1228.00 2720.00 12.40 4.88 4.23 41.73 2.37 1.57 100.00
sdh 0.00 0.00 26.00 608.00 936.00 2728.00 11.56 4.51 3.78 41.08 2.18 1.56 99.20
Know that this setup will not be the fastest, I would still expect it to give some io throughput of 30-40 MB per second.
Sometime the io speed increases to the expected value for some seconds / minutes but falls down again.
Any ideas what is happening or to look at for this issue?
Every help is welcome!
Thank you and greeting Chris
I am still quarreling around with some wired io performance issues where I could not find any likly issue match in this forum.
Since Proxmox 4.4 or so (now running Proxmox 5) the disk io of our seems to be incredible bad. iostat show that the disk with the zfs pools for our vms drop to a few MB throughput while the wait time increase. we are using a z2 raid build with four disks (Enterprise SATA disk) in combination with SSDs for ZIL and ARC2.
avg-cpu: %user %nice %system %iowait %steal %idle
15.55 0.00 7.84 33.38 0.00 43.24
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 38.00 603.00 2308.00 2708.00 15.65 4.52 3.78 26.74 2.33 1.56 100.00
sdb 0.00 0.00 40.00 608.00 1652.00 2724.00 13.51 5.68 4.47 34.70 2.48 1.54 100.00
sdc 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sdd 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sde 0.00 0.00 67.00 66.00 0.00 536.00 8.06 0.05 0.39 0.78 0.00 0.39 5.20
sdf 0.00 0.00 67.00 85.00 0.00 2516.00 33.11 0.08 0.55 1.07 0.14 0.53 8.00
sdg 0.00 0.00 30.00 607.00 1228.00 2720.00 12.40 4.88 4.23 41.73 2.37 1.57 100.00
sdh 0.00 0.00 26.00 608.00 936.00 2728.00 11.56 4.51 3.78 41.08 2.18 1.56 99.20
Know that this setup will not be the fastest, I would still expect it to give some io throughput of 30-40 MB per second.
Sometime the io speed increases to the expected value for some seconds / minutes but falls down again.
Any ideas what is happening or to look at for this issue?
Every help is welcome!
Thank you and greeting Chris