Dears, I'm preparing to setup 3 node Proxmox Cluster using Dell R740 for our production systems. I am trying to decide between using CEPH storage for the Cluster / Shared storage using iSCSI. Which is the best option for Shared Storage in case of 3 node Proxmox cluster? I need a reliable solution to support live VM migration from one host to another in case of host failure.
Shared Storage Recommendation for Proxmox Cluster
- Thread starter abdulwahab
- Start date
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Hi @abdulwahab , welcome to the forum.
Both Ceph and, practically any, iSCSI storage will provide reliable live VM migration.
However, neither will provide live migration in case of host failure. That functionality is not available in PVE/QEMU yet.
The choice between Ceph, iSCSI, or NVMe/TCP comes down to finer details of your use case, budget, skill, location, high availability needs, capacity, etc.
There is no one right answer. As with many things in IT - it depends.
Good luck.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
Both Ceph and, practically any, iSCSI storage will provide reliable live VM migration.
However, neither will provide live migration in case of host failure. That functionality is not available in PVE/QEMU yet.
The choice between Ceph, iSCSI, or NVMe/TCP comes down to finer details of your use case, budget, skill, location, high availability needs, capacity, etc.
There is no one right answer. As with many things in IT - it depends.
Good luck.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox

We need the VMs to be highly available. That's the reason looking for a reliable storage solution that can be shared between hosts. For the VMs, storage capacity planned is 12 TB.
I did initial research and I found that iSCSI doesn't support snapshots. Requires the advice from experts who is running small proxmox clusters with budget friendly hardware but without losing reliability.
I did initial research and I found that iSCSI doesn't support snapshots. Requires the advice from experts who is running small proxmox clusters with budget friendly hardware but without losing reliability.
That's not problem as in "if it crashes, it'll be started on another node". The next better option is fault tolerance, which would be to have a standby VM running and syncing all the time on another node and immediately taking over if a host fails. This is currently not possible in PVE and a very restrictive and expensive additional cost on VMware.We need the VMs to be highly available.
As always: "it depends". If you have a storage that is capable of doing this, you can surely have snapshots, e.g. ZFS-over-iSCSI offers snapshots.did initial research and I found that iSCSI doesn't support snapshots.
If you go with iSCSI, buy a dual-controller box with PVE storage support, e.g. the blockbridge hardware.Requires the advice from experts who is running small proxmox clusters with budget friendly hardware but without losing reliability.
The integration of CEPH into Proxmox makes it really easy to setup shared storage. We use a 3-node-Ceph-Cluster only for storage, no virtualization but I would recommend at least 5 nodes for Ceph in terms of availability and resilience.
Another option, like blockbride, would be linstor/drbd. It's also a commercial product and the support experience has been really good. But like it has been said before:
If you have no experience at all, I would recommend to build a cheap lab environment to test out the different possibilities. Three Intel NUCs are a cheap way to setup a small testing cluster.
Another option, like blockbride, would be linstor/drbd. It's also a commercial product and the support experience has been really good. But like it has been said before:
The choice between Ceph, iSCSI, or NVMe/TCP comes down to finer details of your use case, budget, skill, location, high availability needs, capacity, etc.
If you have no experience at all, I would recommend to build a cheap lab environment to test out the different possibilities. Three Intel NUCs are a cheap way to setup a small testing cluster.
Hi @jtremblay, thank you for your inquiry. I appreciate your thoughts on repurposing hardware. However, it's important to keep in mind that end-of-life equipment can present challenges. It's more susceptible to failure, no longer supported by the manufacturer, and replacement parts can be hard to find.
For long-term reliability and availability, it's often more effective to address potential issues early, before they lead to bigger problems. While repurposing parts might offer some initial savings, using less reliable solutions can end up being more costly in the long run, especially for critical workloads. Sometimes, investing upfront can provide more value and peace of mind in the long term.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
For long-term reliability and availability, it's often more effective to address potential issues early, before they lead to bigger problems. While repurposing parts might offer some initial savings, using less reliable solutions can end up being more costly in the long run, especially for critical workloads. Sometimes, investing upfront can provide more value and peace of mind in the long term.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
@Testani Its extremely unlikely that there is something wrong with Linux iSCSI implementation used by PVE. We have a ton of it in production and continuously test every release going back to PVE6. We're not seeing any issues anywhere.
My recommendation would be to double-check your network configuration. Start with looking for dropped packets and MTU issues. If its not obvious call your vendor! They should be able to assist.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
My recommendation would be to double-check your network configuration. Start with looking for dropped packets and MTU issues. If its not obvious call your vendor! They should be able to assist.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
@Testani Its extremely unlikely that there is something wrong with Linux iSCSI implementation used by PVE. We have a ton of it in production and continuously test every release going back to PVE6. We're not seeing any issues anywhere.
My recommendation would be to double-check your network configuration. Start with looking for dropped packets and MTU issues. If its not obvious call your vendor! They should be able to assist.
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmo
Take a look @ the screen attached
Attachments
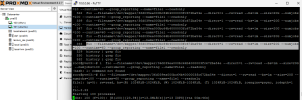
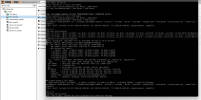
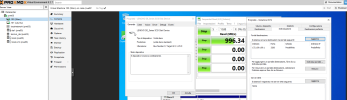
Hi Testani, I can help you debug this. However, I recommend opening your own thread.
You can start there with :
Please provide the output from the following commands in text format as CODE or SPOILER:
`lscpu`
`ip a`
`netstat -s | egrep -i "retrans|loss|time"`
`iscsiadm -m session -P 3`
`multipath -ll`
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
You can start there with :
Please provide the output from the following commands in text format as CODE or SPOILER:
`lscpu`
`ip a`
`netstat -s | egrep -i "retrans|loss|time"`
`iscsiadm -m session -P 3`
`multipath -ll`
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
Last edited:
Code:
root@pve03:~# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel(R) Corporation
Model name: Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz
BIOS Model name: Intel(R) Xeon(R) Silver 4110 CPU @ 2.10GHz CPU @ 2.1G
Hz
BIOS CPU family: 179
CPU family: 6
Model: 85
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 4
CPU(s) scaling MHz: 91%
CPU max MHz: 3000.0000
CPU min MHz: 800.0000
BogoMIPS: 4200.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge m
ca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 s
s ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc
art arch_perfmon pebs bts rep_good nopl xtopology nons
top_tsc cpuid aperfmperf pni pclmulqdq dtes64 ds_cpl v
mx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca
sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer a
es xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpu
id_fault epb cat_l3 cdp_l3 pti intel_ppin ssbd mba ibr
s ibpb stibp tpr_shadow flexpriority ept vpid ept_ad f
sgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpci
d rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap c
lflushopt clwb intel_pt avx512cd avx512bw avx512vl xsa
veopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_
mbm_total cqm_mbm_local dtherm ida arat pln pts vnmi p
ku ospke md_clear flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 256 KiB (8 instances)
L1i: 256 KiB (8 instances)
L2: 8 MiB (8 instances)
L3: 11 MiB (1 instance)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerabilities:
Gather data sampling: Mitigation; Microcode
Itlb multihit: KVM: Mitigation: Split huge pages
L1tf: Mitigation; PTE Inversion; VMX conditional cache flush
es, SMT vulnerable
Mds: Mitigation; Clear CPU buffers; SMT vulnerable
Meltdown: Mitigation; PTI
Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Reg file data sampling: Not affected
Retbleed: Mitigation; IBRS
Spec rstack overflow: Not affected
Spec store bypass: Mitigation; Speculative Store Bypass disabled via prct
l
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointe
r sanitization
Spectre v2: Mitigation; IBRS; IBPB conditional; STIBP conditional;
RSB filling; PBRSB-eIBRS Not affected; BHI Not affect
ed
Srbds: Not affected
Tsx async abort: Mitigation; Clear CPU buffers; SMT vulnerable
Code:
root@pve03:~# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eno1np0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq master vmbr0 state UP group default qlen 1000
link/ether 7c:d3:0a:5d:81:08 brd ff:ff:ff:ff:ff:ff
altname enp10s0f0np0
3: eno2np1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 7c:d3:0a:5d:81:09 brd ff:ff:ff:ff:ff:ff
altname enp10s0f1np1
4: eno3np2: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 7c:d3:0a:5d:81:0a brd ff:ff:ff:ff:ff:ff
altname enp10s0f2np2
5: eno4np3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 7c:d3:0a:5d:81:0b brd ff:ff:ff:ff:ff:ff
altname enp10s0f3np3
6: ens2f0np0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq master iscsi state UP group default qlen 1000
link/ether 68:05:ca:e2:b0:7c brd ff:ff:ff:ff:ff:ff
altname enp91s0f0np0
7: ens2f1np1: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 68:05:ca:e2:b0:7d brd ff:ff:ff:ff:ff:ff
altname enp91s0f1np1
8: enx7ed30a5d810f: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 7e:d3:0a:5d:81:0f brd ff:ff:ff:ff:ff:ff
9: vmbr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 7c:d3:0a:5d:81:08 brd ff:ff:ff:ff:ff:ff
inet 10.0.0.66/24 scope global vmbr0
valid_lft forever preferred_lft forever
inet6 fe80::7ed3:aff:fe5d:8108/64 scope link
valid_lft forever preferred_lft forever
10: tap100i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr100i0 state UNKNOWN group default qlen 1000
link/ether e2:07:04:9e:10:2c brd ff:ff:ff:ff:ff:ff
11: fwbr100i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 42:6c:28:68:ba:e6 brd ff:ff:ff:ff:ff:ff
12: fwpr100p0@fwln100i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr0 state UP group default qlen 1000
link/ether b6:91:84:0b:7e:9d brd ff:ff:ff:ff:ff:ff
13: fwln100i0@fwpr100p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr100i0 state UP group default qlen 1000
link/ether 42:6c:28:68:ba:e6 brd ff:ff:ff:ff:ff:ff
14: iscsi: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 68:05:ca:e2:b0:7c brd ff:ff:ff:ff:ff:ff
inet 172.199.199.67/24 scope global iscsi
valid_lft forever preferred_lft forever
inet6 fe80::6a05:caff:fee2:b07c/64 scope link
valid_lft forever preferred_lft forever
15: tap101i0: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr101i0 state UNKNOWN group default qlen 1000
link/ether e6:3c:2a:67:16:93 brd ff:ff:ff:ff:ff:ff
19: fwbr101i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 46:26:74:2a:82:10 brd ff:ff:ff:ff:ff:ff
20: fwpr101p0@fwln101i0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master iscsi state UP group default qlen 1000
link/ether 92:a4:76:ff:30:42 brd ff:ff:ff:ff:ff:ff
21: fwln101i0@fwpr101p0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr101i0 state UP group default qlen 1000
link/ether 46:26:74:2a:82:10 brd ff:ff:ff:ff:ff:ff
26: tap101i1: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr101i1 state UNKNOWN group default qlen 1000
link/ether e6:d9:9a:48:e0:9d brd ff:ff:ff:ff:ff:ff
27: fwbr101i1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 12:2d:29:59:b8:c6 brd ff:ff:ff:ff:ff:ff
28: fwpr101p1@fwln101i1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master vmbr0 state UP group default qlen 1000
link/ether 26:fe:1b:39:9c:99 brd ff:ff:ff:ff:ff:ff
29: fwln101i1@fwpr101p1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr101i1 state UP group default qlen 1000
link/ether 12:2d:29:59:b8:c6 brd ff:ff:ff:ff:ff:ff
30: tap100i1: <BROADCAST,MULTICAST,PROMISC,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast master fwbr100i1 state UNKNOWN group default qlen 1000
link/ether 02:de:09:67:28:82 brd ff:ff:ff:ff:ff:ff
31: fwbr100i1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 22:65:79:14:37:b0 brd ff:ff:ff:ff:ff:ff
32: fwpr100p1@fwln100i1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master iscsi state UP group default qlen 1000
link/ether ae:77:56:e2:f6:1f brd ff:ff:ff:ff:ff:ff
33: fwln100i1@fwpr100p1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master fwbr100i1 state UP group default qlen 1000
link/ether 22:65:79:14:37:b0 brd ff:ff:ff:ff:ff:ff
Code:
netstat -s | egrep -i "retrans|loss|time"
36985 segments retransmitted
55361 TCP sockets finished time wait in fast timer
1262348 packets rejected in established connections because of timestamp
Quick ack mode was activated 1278828 times
53 times recovered from packet loss due to fast retransmit
Detected reordering 2766 times using SACK
Detected reordering 69 times using reno fast retransmit
Detected reordering 10 times using time stamp
TCPLostRetransmit: 23467
535 fast retransmits
TCPTimeouts: 29045
TCPLossProbes: 7781
TCPLossProbeRecovery: 14
10 connections aborted due to timeout
1 times unable to send RST due to no memory
TCPSynRetrans: 28379
TcpTimeoutRehash: 29041
Code:
root@pve03:~# iscsiadm -m session -P 3
iSCSI Transport Class version 2.0-870
version 2.1.8
Target: iqn.2002-09.com.lenovo:thinksystem.6d039ea000bc64b40000000066e2e41a (non-flash)
Current Portal: 172.199.199.2:3260,2
Persistent Portal: 172.199.199.2:3260,2
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.1993-08.org.debian:01:3ef4b5c46ae
Iface IPaddress: 172.199.199.67
Iface HWaddress: default
Iface Netdev: default
SID: 10
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 262144
FirstBurstLength: 0
MaxBurstLength: 1048576
ImmediateData: No
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 16 State: running
scsi16 Channel 00 Id 0 Lun: 0
scsi16 Channel 00 Id 0 Lun: 1
Attached scsi disk sdc State: running
scsi16 Channel 00 Id 0 Lun: 7
Current Portal: 172.199.199.1:3260,1
Persistent Portal: 172.199.199.1:3260,1
**********
Interface:
**********
Iface Name: default
Iface Transport: tcp
Iface Initiatorname: iqn.1993-08.org.debian:01:3ef4b5c46ae
Iface IPaddress: 172.199.199.67
Iface HWaddress: default
Iface Netdev: default
SID: 9
iSCSI Connection State: LOGGED IN
iSCSI Session State: LOGGED_IN
Internal iscsid Session State: NO CHANGE
*********
Timeouts:
*********
Recovery Timeout: 5
Target Reset Timeout: 30
LUN Reset Timeout: 30
Abort Timeout: 15
*****
CHAP:
*****
username: <empty>
password: ********
username_in: <empty>
password_in: ********
************************
Negotiated iSCSI params:
************************
HeaderDigest: None
DataDigest: None
MaxRecvDataSegmentLength: 262144
MaxXmitDataSegmentLength: 262144
FirstBurstLength: 0
MaxBurstLength: 1048576
ImmediateData: No
InitialR2T: Yes
MaxOutstandingR2T: 1
************************
Attached SCSI devices:
************************
Host Number: 15 State: running
scsi15 Channel 00 Id 0 Lun: 0
scsi15 Channel 00 Id 0 Lun: 1
Attached scsi disk sdb State: running
scsi15 Channel 00 Id 0 Lun: 7
Code:
p=rw
|-+- policy='service-time 0' prio=50 status=active
| `- 15:0:0:1 sdb 8:16 active ready running
`-+- policy='service-time 0' prio=10 status=enabled
`- 16:0:0:1 sdc 8:32 active ready runningCan you post your: /etc/network/interfaces
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
Code:
root@pve03:~# cat /etc/network/interfaces
# network interface settings; autogenerated
# Please do NOT modify this file directly, unless you know what
# you're doing.
#
# If you want to manage parts of the network configuration manually,
# please utilize the 'source' or 'source-directory' directives to do
# so.
# PVE will preserve these directives, but will NOT read its network
# configuration from sourced files, so do not attempt to move any of
# the PVE managed interfaces into external files!
auto lo
iface lo inet loopback
iface eno1np0 inet manual
iface eno2np1 inet manual
iface eno3np2 inet manual
iface eno4np3 inet manual
iface enx7ed30a5d810f inet manual
auto ens2f0np0
iface ens2f0np0 inet manual
#iscsi199
iface ens2f1np1 inet manual
auto vmbr0
iface vmbr0 inet static
address 10.0.0.66/24
gateway 10.0.0.60
bridge-ports eno1np0
bridge-stp off
bridge-fd 0
auto iscsi
iface iscsi inet static
address 172.199.199.67/24
bridge-ports ens2f0np0
bridge-stp off
bridge-fd 0
bridge-vlan-aware yes
bridge-vids 2-4094
source /etc/network/interfaces.d/*Hi @Testani,
We've noticed unusually high numbers of network errors in your output, indicating something isn't right.
Your iSCSI traffic is passing through a bridge, potentially involving VLANs and other network layers? Any of these factors could contribute to high network errors and, as a result, poor receive throughput.
To start, I recommend simplifying the network setup and retesting. Try running iSCSI directly on the physical NIC without the software bridge.
Also, your CPUs are a bit outdated—forking 100 concurrent FIO jobs on an 8-core processor is likely too much for them to handle. At a minimum, it's also bad for the performance of the bridge. Instead, use ioengine=libaio and a qd of 8.
Let me know how it goes!
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
We've noticed unusually high numbers of network errors in your output, indicating something isn't right.
Your iSCSI traffic is passing through a bridge, potentially involving VLANs and other network layers? Any of these factors could contribute to high network errors and, as a result, poor receive throughput.
To start, I recommend simplifying the network setup and retesting. Try running iSCSI directly on the physical NIC without the software bridge.
Also, your CPUs are a bit outdated—forking 100 concurrent FIO jobs on an 8-core processor is likely too much for them to handle. At a minimum, it's also bad for the performance of the bridge. Instead, use ioengine=libaio and a qd of 8.
Let me know how it goes!
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
Thanks for your time.Hi @Testani,
We've noticed unusually high numbers of network errors in your output, indicating something isn't right.
Your iSCSI traffic is passing through a bridge, potentially involving VLANs and other network layers? Any of these factors could contribute to high network errors and, as a result, poor receive throughput.
To start, I recommend simplifying the network setup and retesting. Try running iSCSI directly on the physical NIC without the software bridge.
Also, your CPUs are a bit outdated—forking 100 concurrent FIO jobs on an 8-core processor is likely too much for them to handle. At a minimum, it's also bad for the performance of the bridge. Instead, use ioengine=libaio and a qd of 8.
Let me know how it goes!
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
There are no VLAN in the environment, switch are dedicated to iscsi and same performance using directory iscsi without switch (direct attach). This bridge configuration was temporaly for the creation of a Windows vm test where iscsi works flwlessy.
Keep in mind that two host esx are still alive on the same iscsi network with good performance.
Regarding test fio we can see same output using 1 single thread
Hi @Testani,
You have classic symptoms of a receive network issues. Based on the previous post, your performance is asymmetric. Write performance is acceptable, but read performance is poor.
This correlates directly to the implementation complexities of TCP. Sending a packet has much lower overhead than receiving a packet. The send function is typically zero-copy, meaning it does not need to allocate memory and copy data. Receiving is significantly more complicated because you never know when a packet will arrive or how many will follow it. As such, memory must be allocated inline, and the packets must be copied into place.
It is essential to note that if packets arrive faster than your OS can process them, there is only one option... drop the packet. If you have flow control enabled on your ethernet devices, this will also cause your NIC to generate pause frames (i.e., L2 flow control).
Again, your network statistics show alarming issues. 1.2 million packets were rejected due to timestamp issues, and tens of thousands of segments were retransmitted. You can believe what you want, but don't ignore what your system is telling you.
If you want to get to the bottom of this, you should:
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox
You have classic symptoms of a receive network issues. Based on the previous post, your performance is asymmetric. Write performance is acceptable, but read performance is poor.
This correlates directly to the implementation complexities of TCP. Sending a packet has much lower overhead than receiving a packet. The send function is typically zero-copy, meaning it does not need to allocate memory and copy data. Receiving is significantly more complicated because you never know when a packet will arrive or how many will follow it. As such, memory must be allocated inline, and the packets must be copied into place.
It is essential to note that if packets arrive faster than your OS can process them, there is only one option... drop the packet. If you have flow control enabled on your ethernet devices, this will also cause your NIC to generate pause frames (i.e., L2 flow control).
Again, your network statistics show alarming issues. 1.2 million packets were rejected due to timestamp issues, and tens of thousands of segments were retransmitted. You can believe what you want, but don't ignore what your system is telling you.
If you want to get to the bottom of this, you should:
- adjust the configuration to run iSCSI on the physical interface
- disable multipathing; focus on the performance of a single path
- disable all virtual machines running on the host (i.e., eliminate competing resources)
- use fio against the bare scsi device; use asynchronous I/O
Blockbridge : Ultra low latency all-NVME shared storage for Proxmox - https://www.blockbridge.com/proxmox