Guten Tag,
ich möchte gerne ein Cluster aufbauen. Aktuell hab ich nur ein Single Node Setup. Problem ist natürlich, sobald etwas an dieser einen Hardware ist bin ich offline. Mein Ziel wäre es daher die Verfügbarkeit zu erhöhen Richtung HA. Mit einem kurzzeitigen Ausfall kann ich Leben, aber ich möchte mein System gerne so, dass ich binnen kurzer Zeit wieder voll verfügbar bin.
Aktueller Node:
So natürlich ist das jetzt nicht optimal, vor allem da die beiden RAID5 jeweils als physical volume ein und der selben volume group zugewiesen sind (diejenigen die jetzt Haarausfall bekommen, bitte weitergehen).
Ich möchte jetzt gerne min. mal 2 neue Nodes kaufen und das von vorne herein mit vernünftiger Hardware planen. Sodass ich dann erstmal mit dem einen vorhandenen und den zwei neuen Nodes auf ein 3 Node Setup komme. ggf. muss ich dazu auch den ersten noch umbauen.
Meine Vorstellung geht in Richtung
Ich plane also mit 6TB größe für das Ceph Cluster.
Darauf laufen sollen ~40 VMs (auf dem einen Node sind es derzeit 33). Ich habe insgesamt ca. 100 VMs wovon aber ein großer Teil nur bei Bedarf hochgefahren wird. Meine Anforderung wäre also eher gute I/O-Performance und viel RAM und nicht so CPU lastiges Zeugs. Ich weiß aber nicht wieviel Ceph dann schon an CPU und Memory schluckt.
RAM Auslastung bin ich derzeit schon recht am Limit mit ~85% Auslastung. Das soll auf jeden Fall wieder weniger werden, wenn ich 2 weitere Nodes mit jeweils auch 128GB Habe wird das ja aber auf sicher so sein. Vor allem wenn ich nur Nodes dazu schieben muss wenn es eng wird.
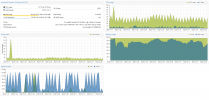
Ich bin echt recht unerfahren was sie die Hardwareauswahl angeht und bin mir nicht sicher ob ich da mit Kanonen auf Spatzen schieße. Wenn ich mir das Performance Dahsboard anschaue, was ich mal angehängt habe, dann ist mein Bottlneck ja echt nur der RAM. CPU und I/O sind eher mäßig ausgelastet. Sollte ich vielleicht eine kleinere CPU wählen und auf SAS HDDs statt SSDs setzen?
Hoffentlich kann Jemand was damit anfangen und mir einen Tipp geben. Wäre auf jeden Fall sehr verbunden.
ich möchte gerne ein Cluster aufbauen. Aktuell hab ich nur ein Single Node Setup. Problem ist natürlich, sobald etwas an dieser einen Hardware ist bin ich offline. Mein Ziel wäre es daher die Verfügbarkeit zu erhöhen Richtung HA. Mit einem kurzzeitigen Ausfall kann ich Leben, aber ich möchte mein System gerne so, dass ich binnen kurzer Zeit wieder voll verfügbar bin.
Aktueller Node:
- Supermicro Strato 2900 (Supermicro X10DRi)
- 2x Intel Xeon E5-2630 v3 (8-Core)
- 128GB regist. ECC DDR4 PC2133 (es sind 8x8 und 4x16GB verbaut)
- Onboard NIC
- Adaptec 81605ZQ
- RAID5 6x600GB SAS 2 10.000rpm als Storage für VMs
- RAID5 3x1TB Samsung 860 Evo als Storage für VMs
- RAID1 2x240 Samsung 845DC als Cache für das RAID5
- RIAD1 2x250GB Samsung 860 Evo fürs System
So natürlich ist das jetzt nicht optimal, vor allem da die beiden RAID5 jeweils als physical volume ein und der selben volume group zugewiesen sind (diejenigen die jetzt Haarausfall bekommen, bitte weitergehen).
Ich möchte jetzt gerne min. mal 2 neue Nodes kaufen und das von vorne herein mit vernünftiger Hardware planen. Sodass ich dann erstmal mit dem einen vorhandenen und den zwei neuen Nodes auf ein 3 Node Setup komme. ggf. muss ich dazu auch den ersten noch umbauen.
Meine Vorstellung geht in Richtung
- Strato 2940-X2HF5
- 2 x Intel Xeon 4216, 2.1 GHz 16-Core
- 128GB RAM
- 1GbE Onboard NIC für Management und Admin
- 10GbE NIC für Cluster Kommunikation
- vernünftigen HBA, weiß noch nicht so recht was
- 2 x System SSD, Software RAID 1, 6G/s
- 6 x 1TB Datacenter SSD, 6G/s
Ich plane also mit 6TB größe für das Ceph Cluster.
Darauf laufen sollen ~40 VMs (auf dem einen Node sind es derzeit 33). Ich habe insgesamt ca. 100 VMs wovon aber ein großer Teil nur bei Bedarf hochgefahren wird. Meine Anforderung wäre also eher gute I/O-Performance und viel RAM und nicht so CPU lastiges Zeugs. Ich weiß aber nicht wieviel Ceph dann schon an CPU und Memory schluckt.
RAM Auslastung bin ich derzeit schon recht am Limit mit ~85% Auslastung. Das soll auf jeden Fall wieder weniger werden, wenn ich 2 weitere Nodes mit jeweils auch 128GB Habe wird das ja aber auf sicher so sein. Vor allem wenn ich nur Nodes dazu schieben muss wenn es eng wird.
Ich bin echt recht unerfahren was sie die Hardwareauswahl angeht und bin mir nicht sicher ob ich da mit Kanonen auf Spatzen schieße. Wenn ich mir das Performance Dahsboard anschaue, was ich mal angehängt habe, dann ist mein Bottlneck ja echt nur der RAM. CPU und I/O sind eher mäßig ausgelastet. Sollte ich vielleicht eine kleinere CPU wählen und auf SAS HDDs statt SSDs setzen?
Hoffentlich kann Jemand was damit anfangen und mir einen Tipp geben. Wäre auf jeden Fall sehr verbunden.
") Dort ist auch das Paper aus 2018 verlinkt.
Dort ist auch das Paper aus 2018 verlinkt.
")