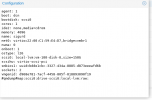
restore vma archive: zstd -q -d -c /mnt/pve/BackupSrv-CIFS/dump/vzdump-qemu-3012-2025_01_23-19_48_47.vma.zst | vma extract -v -r /var/tmp/vzdumptmp7745.fifo - /var/tmp/vzdumptmp7745
CFG: size: 504 name: qemu-server.conf
DEV: dev_id=1 size: 68719476736 devname: drive-virtio0
CTIME: Thu Jan 23 19:48:48 2025
new volume ID is 'local-zfs:vm-9999-disk-2'
map 'drive-virtio0' to '/dev/zvol/rpool/data/vm-9999-disk-2' (write zeros = 0)
progress 1% (read 687210496 bytes, duration 4 sec)
progress 2% (read 1374420992 bytes, duration 7 sec)
progress 3% (read 2061631488 bytes, duration 11 sec)
progress 4% (read 2748841984 bytes, duration 15 sec)
progress 5% (read 3435986944 bytes, duration 18 sec)
progress 6% (read 4123197440 bytes, duration 21 sec)
progress 7% (read 4810407936 bytes, duration 25 sec)
progress 8% (read 5497618432 bytes, duration 28 sec)
progress 9% (read 6184763392 bytes, duration 30 sec)
progress 10% (read 6871973888 bytes, duration 36 sec)
progress 11% (read 7559184384 bytes, duration 39 sec)
progress 12% (read 8246394880 bytes, duration 43 sec)
progress 13% (read 8933539840 bytes, duration 47 sec)
progress 14% (read 9620750336 bytes, duration 51 sec)
progress 15% (read 10307960832 bytes, duration 54 sec)
progress 16% (read 10995171328 bytes, duration 58 sec)
progress 17% (read 11682316288 bytes, duration 61 sec)
progress 18% (read 12369526784 bytes, duration 65 sec)
progress 19% (read 13056737280 bytes, duration 70 sec)
progress 20% (read 13743947776 bytes, duration 73 sec)
progress 21% (read 14431092736 bytes, duration 77 sec)
progress 22% (read 15118303232 bytes, duration 82 sec)
progress 23% (read 15805513728 bytes, duration 85 sec)
progress 24% (read 16492724224 bytes, duration 89 sec)
progress 25% (read 17179869184 bytes, duration 93 sec)
progress 26% (read 17867079680 bytes, duration 98 sec)
progress 27% (read 18554290176 bytes, duration 101 sec)
progress 28% (read 19241500672 bytes, duration 107 sec)
progress 29% (read 19928711168 bytes, duration 111 sec)
progress 30% (read 20615856128 bytes, duration 115 sec)
progress 31% (read 21303066624 bytes, duration 120 sec)
progress 32% (read 21990277120 bytes, duration 125 sec)
progress 33% (read 22677487616 bytes, duration 129 sec)
progress 34% (read 23364632576 bytes, duration 133 sec)
progress 35% (read 24051843072 bytes, duration 136 sec)
progress 36% (read 24739053568 bytes, duration 139 sec)
progress 37% (read 25426264064 bytes, duration 143 sec)
progress 38% (read 26113409024 bytes, duration 148 sec)
progress 39% (read 26800619520 bytes, duration 152 sec)
progress 40% (read 27487830016 bytes, duration 158 sec)
progress 41% (read 28175040512 bytes, duration 162 sec)
progress 42% (read 28862185472 bytes, duration 166 sec)
progress 43% (read 29549395968 bytes, duration 171 sec)
progress 44% (read 30236606464 bytes, duration 176 sec)
progress 45% (read 30923816960 bytes, duration 181 sec)
progress 46% (read 31610961920 bytes, duration 185 sec)
progress 47% (read 32298172416 bytes, duration 190 sec)
progress 48% (read 32985382912 bytes, duration 195 sec)
progress 49% (read 33672593408 bytes, duration 200 sec)
progress 50% (read 34359738368 bytes, duration 205 sec)
progress 51% (read 35046948864 bytes, duration 210 sec)
progress 52% (read 35734159360 bytes, duration 212 sec)
progress 53% (read 36421369856 bytes, duration 213 sec)
progress 54% (read 37108580352 bytes, duration 215 sec)
progress 55% (read 37795725312 bytes, duration 217 sec)
progress 56% (read 38482935808 bytes, duration 218 sec)
progress 57% (read 39170146304 bytes, duration 220 sec)
progress 58% (read 39857356800 bytes, duration 222 sec)
progress 59% (read 40544501760 bytes, duration 226 sec)
progress 60% (read 41231712256 bytes, duration 230 sec)
progress 61% (read 41918922752 bytes, duration 232 sec)
progress 62% (read 42606133248 bytes, duration 236 sec)
progress 63% (read 43293278208 bytes, duration 241 sec)
progress 64% (read 43980488704 bytes, duration 245 sec)
progress 65% (read 44667699200 bytes, duration 295 sec)
progress 66% (read 45354909696 bytes, duration 343 sec)
progress 67% (read 46042054656 bytes, duration 384 sec)
progress 68% (read 46729265152 bytes, duration 420 sec)
progress 69% (read 47416475648 bytes, duration 470 sec)
progress 70% (read 48103686144 bytes, duration 503 sec)
progress 71% (read 48790831104 bytes, duration 553 sec)
progress 72% (read 49478041600 bytes, duration 604 sec)
progress 73% (read 50165252096 bytes, duration 662 sec)
progress 74% (read 50852462592 bytes, duration 700 sec)
progress 75% (read 51539607552 bytes, duration 736 sec)
progress 76% (read 52226818048 bytes, duration 777 sec)
progress 77% (read 52914028544 bytes, duration 820 sec)
progress 78% (read 53601239040 bytes, duration 882 sec)
progress 79% (read 54288449536 bytes, duration 934 sec)
progress 80% (read 54975594496 bytes, duration 969 sec)
progress 81% (read 55662804992 bytes, duration 1008 sec)
progress 82% (read 56350015488 bytes, duration 1057 sec)
progress 83% (read 57037225984 bytes, duration 1096 sec)
progress 84% (read 57724370944 bytes, duration 1134 sec)
progress 85% (read 58411581440 bytes, duration 1172 sec)
progress 86% (read 59098791936 bytes, duration 1220 sec)
progress 87% (read 59786002432 bytes, duration 1276 sec)
progress 88% (read 60473147392 bytes, duration 1325 sec)
progress 89% (read 61160357888 bytes, duration 1369 sec)
progress 90% (read 61847568384 bytes, duration 1419 sec)
progress 91% (read 62534778880 bytes, duration 1471 sec)
progress 92% (read 63221923840 bytes, duration 1509 sec)
progress 93% (read 63909134336 bytes, duration 1556 sec)
progress 94% (read 64596344832 bytes, duration 1602 sec)
progress 95% (read 65283555328 bytes, duration 1645 sec)
progress 96% (read 65970700288 bytes, duration 1692 sec)
progress 97% (read 66657910784 bytes, duration 1730 sec)
progress 98% (read 67345121280 bytes, duration 1747 sec)
progress 99% (read 68032331776 bytes, duration 1792 sec)
progress 100% (read 68719476736 bytes, duration 1838 sec)