Hope everyone is doing well!
Thanks to everyone in ProxMox for their amazing work and effort, huge fan, and thanks to anyone willing to help, I really appreciate it, means a lot to me!
I am trying to use rclone to first sync and then check several source and destination directories.
The destinations is an SSD.
I am using rclone to sync around 2TB of data to an SSD.
When I tried to run the rclone check command to the SSD destination the Ubuntu machine froze up and became absolutely non responsive.
The only way was to do a HARD shut down and start it again.
However lowering the checkers even to 1 did not help (`--checkers=1`).
I played with all parameter/flags I could find which seemed relevant in the rclone documentation, but could not solve the problem.
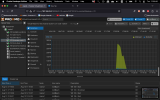
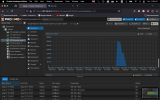
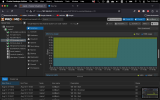
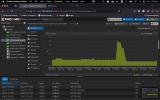
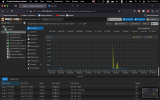
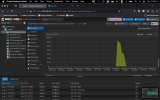
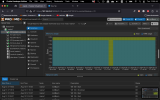
It looks like when it's running against a faster media such as an SSD it is going over some kind of a limit and it's crashing the Ubuntu machine.
I thought it could be an out of memory issue, however all indicators of the Ubuntu Server machine seem fine.
This is the rclone command which is causing the issue:
The rclone command which is failing:
The full script I use to run the rclone sync and rclone check commands is in pastebin below.
https://pastebin.com/PxLjAPv5
---
Ubuntu Server version:
---
Rclone version:
---
Rclone config:
https://pastebin.com/FVWG21Ab
---
Here are some logs in pastebin:
The log files was more than 90MB, I had to cut out the mundane output from the sync and check to fit the log in pastebin's limits.
But yeah kind of just cuts of while the check is going, the last part of the log is genuine and has not been cut down to fit in pastebin.
https://pastebin.com/HRpim1yX
This log is a bit more different as it has some weird symbols in the end:
This is the latest log, for some reason it's not showing in full in pastebin unless you click on raw to view it in it's entirety:
https://pastebin.com/aA0ERkmu
The log files from the rclone sync or rclone check commands don't have anything which seems to point to any issue.
When the crash happens, the log file just stops at the point of the file which it was currently processing.
---
Its a brand new SSD and I did a SMART test on the SSD and all seems good:
---
The setup:
All sources are locally mounted `TrueNas Scale` SMB shares.
TrueNas Scale is also another VM running on the same `ProxMox PVE`, as is the `Ubuntu Server` running `Rclone`.
The TrueNas Scale VM exhibits no sign of any load before, after and ruing when the crash happens, just seems to be chugging along not feeling stressed.
The HDDs and SSD are all directly connected to the computer via a `SAS controller`. The SAS controller is exclusively given to the VM running Ubuntu Server and I see no errors on this side.
Some of the shares have normal or larger files, others have loads of small files.
Ubuntu Server VM:
TrueNas Scale VM:
---
I researched how to debug Ubuntu Server the best I can, and here is what I came up with so far:
Ubuntu Server DEBUG information:
https://pastebin.com/S5VS61Tx
https://pastebin.com/kM3jxVwb
---
It seems like it's not rclone that is freezing the OS, but something related to I/O reading/writing large amounts of data, but I don't know how to debug it.
I even tried using `ionice -c2 -n7 nice -n 10 rclone check` to reduce the priority of the rclone command to try and throttle the read/write ops, but no joy.
When the crash of the Ubuntu Server VM happens it becomes absolutely non responsive, the guest agent stops running, I cannot SSH into the machine. I also cannot shutdown the machine. Only issuing `STOP` to the VM works in shutting it down, or shutting down the whole ProxMox PVE node, to try and do a more graceful of the VM itself.
I just want it to complete successfully.
I am going crazy trying to figure out what am I doing wrong.
Any help in debugging and fixing this is appreciated!
Thanks to everyone in ProxMox for their amazing work and effort, huge fan, and thanks to anyone willing to help, I really appreciate it, means a lot to me!
I am trying to use rclone to first sync and then check several source and destination directories.
The destinations is an SSD.
I am using rclone to sync around 2TB of data to an SSD.
When I tried to run the rclone check command to the SSD destination the Ubuntu machine froze up and became absolutely non responsive.
The only way was to do a HARD shut down and start it again.
However lowering the checkers even to 1 did not help (`--checkers=1`).
I played with all parameter/flags I could find which seemed relevant in the rclone documentation, but could not solve the problem.
It looks like when it's running against a faster media such as an SSD it is going over some kind of a limit and it's crashing the Ubuntu machine.
I thought it could be an out of memory issue, however all indicators of the Ubuntu Server machine seem fine.
This is the rclone command which is causing the issue:
The rclone command which is failing:
Code:
rclone check "$src" "$dest" \
--checkers=1 \
--fast-list \
--multi-thread-streams=0 \
--buffer-size=0 \
--one-way \
--checksum \
--log-file="$LOG_FILE" \
--log-level=DEBUG \
--retries 3 \
--retries-sleep 3s \
--progressThe full script I use to run the rclone sync and rclone check commands is in pastebin below.
https://pastebin.com/PxLjAPv5
---
Ubuntu Server version:
Code:
ubuntu 24.04 (64 bit)---
Rclone version:
Code:
rclone --version
rclone v1.67.0
- os/version: ubuntu 24.04 (64 bit)
- os/kernel: 6.8.0-40-generic (x86_64)
- os/type: linux
- os/arch: amd64
- go/version: go1.22.4
- go/linking: static
- go/tags: none---
Rclone config:
https://pastebin.com/FVWG21Ab
---
Here are some logs in pastebin:
The log files was more than 90MB, I had to cut out the mundane output from the sync and check to fit the log in pastebin's limits.
But yeah kind of just cuts of while the check is going, the last part of the log is genuine and has not been cut down to fit in pastebin.
https://pastebin.com/HRpim1yX
This log is a bit more different as it has some weird symbols in the end:
This is the latest log, for some reason it's not showing in full in pastebin unless you click on raw to view it in it's entirety:
https://pastebin.com/aA0ERkmu
The log files from the rclone sync or rclone check commands don't have anything which seems to point to any issue.
When the crash happens, the log file just stops at the point of the file which it was currently processing.
---
Its a brand new SSD and I did a SMART test on the SSD and all seems good:
Code:
sudo smartctl -H /dev/sdc
[sudo] password for usertemp:
smartctl 7.4 2023-08-01 r5530 [x86_64-linux-6.8.0-40-generic] (local build)
Copyright (C) 2002-23, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment test result: PASSED---
The setup:
Code:
ProxMox PVE 8.2.4All sources are locally mounted `TrueNas Scale` SMB shares.
TrueNas Scale is also another VM running on the same `ProxMox PVE`, as is the `Ubuntu Server` running `Rclone`.
The TrueNas Scale VM exhibits no sign of any load before, after and ruing when the crash happens, just seems to be chugging along not feeling stressed.
The HDDs and SSD are all directly connected to the computer via a `SAS controller`. The SAS controller is exclusively given to the VM running Ubuntu Server and I see no errors on this side.
Some of the shares have normal or larger files, others have loads of small files.
Ubuntu Server VM:
Code:
- 8 Cores
- 8GB RAMTrueNas Scale VM:
Code:
- 4 Cores
- 22GB RAM
- 2 x 6TB NAS HDDs 5400RPM in RAID1
- 1 x 1TB SSD for read cache---
I researched how to debug Ubuntu Server the best I can, and here is what I came up with so far:
Ubuntu Server DEBUG information:
Code:
sudo cat /var/log/kern.log | grep errorhttps://pastebin.com/S5VS61Tx
Code:
sudo cat /var/log/syslog | grep errorhttps://pastebin.com/kM3jxVwb
---
It seems like it's not rclone that is freezing the OS, but something related to I/O reading/writing large amounts of data, but I don't know how to debug it.
I even tried using `ionice -c2 -n7 nice -n 10 rclone check` to reduce the priority of the rclone command to try and throttle the read/write ops, but no joy.
When the crash of the Ubuntu Server VM happens it becomes absolutely non responsive, the guest agent stops running, I cannot SSH into the machine. I also cannot shutdown the machine. Only issuing `STOP` to the VM works in shutting it down, or shutting down the whole ProxMox PVE node, to try and do a more graceful of the VM itself.
I just want it to complete successfully.
I am going crazy trying to figure out what am I doing wrong.
Any help in debugging and fixing this is appreciated!
Attachments
-
 Screenshot 2024-08-13 at 17.50.11.png540.2 KB · Views: 2
Screenshot 2024-08-13 at 17.50.11.png540.2 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.50.png615.4 KB · Views: 2
Screenshot 2024-08-13 at 17.50.50.png615.4 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.47.png613.3 KB · Views: 2
Screenshot 2024-08-13 at 17.50.47.png613.3 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.43.png601.4 KB · Views: 2
Screenshot 2024-08-13 at 17.50.43.png601.4 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.40.png619 KB · Views: 2
Screenshot 2024-08-13 at 17.50.40.png619 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.33.png545.8 KB · Views: 2
Screenshot 2024-08-13 at 17.50.33.png545.8 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.25.png613.5 KB · Views: 2
Screenshot 2024-08-13 at 17.50.25.png613.5 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.22.png614.8 KB · Views: 2
Screenshot 2024-08-13 at 17.50.22.png614.8 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.18.png601.4 KB · Views: 2
Screenshot 2024-08-13 at 17.50.18.png601.4 KB · Views: 2 -
 Screenshot 2024-08-13 at 17.50.15.png606.5 KB · Views: 2
Screenshot 2024-08-13 at 17.50.15.png606.5 KB · Views: 2
Last edited: