Hi,
I am interested to leverage
Questions:
1/ I noticed that
2/ I assume it is a good idea to have
Thanks you!
I am interested to leverage
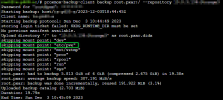
proxmox-backup-client to make backups on my hosts. I read several forum posts and tutorials and have successfully created the backup.Questions:
1/ I noticed that
/etc/pve is not included in the backup, nor did I specified it in the .pxarexclude file. Why is that the case? Did I do something incorrectly in the setup?2/ I assume it is a good idea to have
/etc/pve backup, especially the fact that it contains all the information for the clusters and nodes setup. If not, what is the best practice to backup /etc/pve?Thanks you!
Attachments
Last edited:

 Harder to automate. I actually wondered why there isn't e.g. userland mount tool for the
Harder to automate. I actually wondered why there isn't e.g. userland mount tool for the ") I could add this to Bugzilla as enhancement request, but that would be my first (enhacement one).
I could add this to Bugzilla as enhancement request, but that would be my first (enhacement one). ") ) dump tool.
) dump tool. , I am the kind of person who reads the code before the docs. Thanks I didn't know it was already thought of!
, I am the kind of person who reads the code before the docs. Thanks I didn't know it was already thought of!