Proxmox with Ceph - Replication ?
- Thread starter fxandrei
- Start date
-
- Tags
- ceph cluster replication
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
")

The answer to your question is yes.
We used the excellent wiki article referenced above by Alwin to mirror disk images from our HQ cluster to our DR cluster located at a remote datacenter. Communication is via sd-wan and a 150m broadband internet circuit. We are currently mirroring 27 disk images totaling about 11T. What this provides us is very up to date, crash consistent disk images at the remote location. In a disaster situation, (Moon fell on HQ) these images can be promoted to primary and brought up in a fraction of the time needed to restore from a backup. This does not mean that this is a replacement for good backups!
In the screenshots below you can see an image in the syncing process, and images replaying from journal after the initial sync. Also below is a 25hr bandwidth graph. The first 8 hours you can seen that the entire allocated amount (currently capped at 80m) of bandwidth is being consumed because an image was doing it's initial sync. The next 5 hours was spent catching up and then back to what I consider normal replaying. Then about 08:30 I began syncing another image.
So to help put this in perspective, I began syncing a 4T(1.5 used) image on Saturday morning about 9:30a and it finished on Wed about 10p. All the while continuing to replay journals from 25 existing images. It joined the ranks of the replaying and I started syncing another image.
Hope this is useful.
We used the excellent wiki article referenced above by Alwin to mirror disk images from our HQ cluster to our DR cluster located at a remote datacenter. Communication is via sd-wan and a 150m broadband internet circuit. We are currently mirroring 27 disk images totaling about 11T. What this provides us is very up to date, crash consistent disk images at the remote location. In a disaster situation, (Moon fell on HQ) these images can be promoted to primary and brought up in a fraction of the time needed to restore from a backup. This does not mean that this is a replacement for good backups!
In the screenshots below you can see an image in the syncing process, and images replaying from journal after the initial sync. Also below is a 25hr bandwidth graph. The first 8 hours you can seen that the entire allocated amount (currently capped at 80m) of bandwidth is being consumed because an image was doing it's initial sync. The next 5 hours was spent catching up and then back to what I consider normal replaying. Then about 08:30 I began syncing another image.
So to help put this in perspective, I began syncing a 4T(1.5 used) image on Saturday morning about 9:30a and it finished on Wed about 10p. All the while continuing to replay journals from 25 existing images. It joined the ranks of the replaying and I started syncing another image.
Hope this is useful.
Attachments
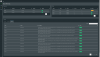
This can be done either per image or pool.So this would be done for each individual disk used in the vms.
Yes, but be careful with rsync, any change done on the remote site would be overwritten. Also the removal of VMs need to be propagated to the remote site.The vm configs would beed to be synced by some other method right ? Im thinking maybe rsync.
Hi, we are going to implement a DR solutions via rbd mirror. can you share this script with us?We simply have a cron job that collects vm configs and copies them to a location at our DR site.
Thanks you very much
So i have followed the article mentioned by Alwin, and i am testing this solution.
So i now have one image the is syncing from the master cluster to the backup cluster.
If i run this on the backup cluster: rbd mirror pool status mirror1 --verbose
I get :
vm-101-disk-0:
global_id: 5d5f468d-da19-4534-a8e7-7b072cb06b3e
state: up+replaying
So everything seems ok here.
But if i run the same command on the master cluster i get:
vm-101-disk-0:
global_id: 5d5f468d-da19-4534-a8e7-7b072cb06b3e
state: down+unknown
description: status not found
So what could be wrong on the master side ?
And i tryed to boot the disk on the backup cluster, and it seems it cannot be read (its a windows test vm).
Im thinking i need to change it state somehow right (IMAGE PROMOTION AND DEMOTION ?) ?
Is there any way of testing if the image is ok (as in running the windows on the backup cluster) withought disrupting the image on the master cluster ?
So i now have one image the is syncing from the master cluster to the backup cluster.
If i run this on the backup cluster: rbd mirror pool status mirror1 --verbose
I get :
vm-101-disk-0:
global_id: 5d5f468d-da19-4534-a8e7-7b072cb06b3e
state: up+replaying
So everything seems ok here.
But if i run the same command on the master cluster i get:
vm-101-disk-0:
global_id: 5d5f468d-da19-4534-a8e7-7b072cb06b3e
state: down+unknown
description: status not found
So what could be wrong on the master side ?
And i tryed to boot the disk on the backup cluster, and it seems it cannot be read (its a windows test vm).
Im thinking i need to change it state somehow right (IMAGE PROMOTION AND DEMOTION ?) ?
Is there any way of testing if the image is ok (as in running the windows on the backup cluster) withought disrupting the image on the master cluster ?
So about the image test.
I went ahead and demoted the image on the main cluster, and promoted it on the backup cluster.
On the main cluster
rbd mirror image demote mirror1/vm-101-disk-0
On the backup cluster
rbd mirror image promote mirror1/vm-101-disk-0
I then was able to boot the vm on the backup cluster.
The problem is that i made modification and the vm while running on the backup cluster. For the i have to force resync .
First i promoted back the image on the main cluster, and forced resync running this cmd on the backup cluster:
rbd mirror image resync mirror1/vm-101-disk-0
So i gues the only thing i dont know what to do about is the unknown status on the main cluster.
I went ahead and demoted the image on the main cluster, and promoted it on the backup cluster.
On the main cluster
rbd mirror image demote mirror1/vm-101-disk-0
On the backup cluster
rbd mirror image promote mirror1/vm-101-disk-0
I then was able to boot the vm on the backup cluster.
The problem is that i made modification and the vm while running on the backup cluster. For the i have to force resync .
First i promoted back the image on the main cluster, and forced resync running this cmd on the backup cluster:
rbd mirror image resync mirror1/vm-101-disk-0
So i gues the only thing i dont know what to do about is the unknown status on the main cluster.
Yes. See the Ceph docs for more information.
https://docs.ceph.com/docs/nautilus/rbd/rbd-mirroring/
https://docs.ceph.com/docs/nautilus/rbd/rbd-mirroring/
So i have this pool that has multiple images in them that are mirroring to another cluster with the same pool name.
So i followed this : https://pve.proxmox.com/wiki/Ceph_RBD_Mirroring .
But im seeing some something strange, and i cannot find any info about whats up.
The pool on the destination cluster (the one that has the rdb mirror service pulling the data from the source cluster\pool) reports the size occupied by the images much bigger that the source.
So if i look at the images size (individually) they are the same in the source and the destination.
But if i look at the pool they are quite different.
The source pool reports 2.81TB used, and the destination reports 5.31 used.
What is happening?!
So i followed this : https://pve.proxmox.com/wiki/Ceph_RBD_Mirroring .
But im seeing some something strange, and i cannot find any info about whats up.
The pool on the destination cluster (the one that has the rdb mirror service pulling the data from the source cluster\pool) reports the size occupied by the images much bigger that the source.
So if i look at the images size (individually) they are the same in the source and the destination.
But if i look at the pool they are quite different.
The source pool reports 2.81TB used, and the destination reports 5.31 used.
What is happening?!
This depends on the pool setup and how crush is configured. Check both pools withThe source pool reports 2.81TB used, and the destination reports 5.31 used.
ceph df detail.So im guessing you want to see the details related to mirror1, right ?
So on the backup cluster :
On the main cluster:
So on the backup cluster :
pool 4 'mirror1' replicated size 3 min_size 2 crush_rule 2 object_hash rjenkins pg_num 256 pgp_num 256 autoscale_mode warn last_change 45807 lfor 0/45807/45805 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
removed_snaps [1~d]
On the main cluster:
pool 7 'mirror1' replicated size 3 min_size 2 crush_rule 2 object_hash rjenkins pg_num 128 pgp_num 128 autoscale_mode warn last_change 25047 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd
removed_snaps [1~d]
This is the crush rule on both clusters :
rule hdd-rule { id 2 type replicated min_size 1 max_size 10 step take default class hdd step chooseleaf firstn 0 type host step emit }