Hi,Hi,
please share the full task log and output ofpveversion -v. Is there anything in the system journal around the time the issue happens?
full log task:
create full clone of drive (esx4:ha-datacenter/esx4-local/RMS.Ubnt.Srv/RMS.Ubnt.Srv.vmdk)
transferred 0.0 B of 128.0 GiB (0.00%)
transferred 1.3 GiB of 128.0 GiB (1.00%)
transferred 2.6 GiB of 128.0 GiB (2.00%)
transferred 3.8 GiB of 128.0 GiB (3.00%)
transferred 5.1 GiB of 128.0 GiB (4.00%)
transferred 6.4 GiB of 128.0 GiB (5.00%)
transferred 7.7 GiB of 128.0 GiB (6.01%)
transferred 9.0 GiB of 128.0 GiB (7.01%)
qemu-img: error while reading at byte 10301208576: Input/output error
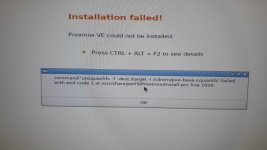
TASK ERROR: unable to create VM 101 - cannot import from 'esx4:ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk' - copy failed: command '/usr/bin/qemu-img convert -p -n -f vmdk -O raw /run/pve/import/esxi/esx4/mnt/ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk zeroinit:/var/lib/pve/local-btrfs/images/101/vm-101-disk-0/disk.raw' failed: exit code 1
pveversion -v:
root@proxmox-gl-01:~# pveversion -v
proxmox-ve: 9.0.0 (running kernel: 6.14.11-1-pve)
pve-manager: 9.0.6 (running version: 9.0.6/49c767b70aeb6648)
proxmox-kernel-helper: 9.0.4
proxmox-kernel-6.14.11-1-pve-signed: 6.14.11-1
proxmox-kernel-6.14: 6.14.11-1
proxmox-kernel-6.8.12-14-pve-signed: 6.8.12-14
proxmox-kernel-6.8: 6.8.12-14
proxmox-kernel-6.8.12-9-pve-signed: 6.8.12-9
ceph-fuse: 19.2.3-pve1
corosync: 3.1.9-pve2
criu: 4.1.1-1
frr-pythontools: 10.3.1-1+pve4
ifupdown2: 3.3.0-1+pmx10
intel-microcode: 3.20250512.1
ksm-control-daemon: 1.5-1
libjs-extjs: 7.0.0-5
libproxmox-acme-perl: 1.7.0
libproxmox-backup-qemu0: 2.0.1
libproxmox-rs-perl: 0.4.1
libpve-access-control: 9.0.3
libpve-apiclient-perl: 3.4.0
libpve-cluster-api-perl: 9.0.6
libpve-cluster-perl: 9.0.6
libpve-common-perl: 9.0.9
libpve-guest-common-perl: 6.0.2
libpve-http-server-perl: 6.0.4
libpve-network-perl: 1.1.6
libpve-rs-perl: 0.10.10
libpve-storage-perl: 9.0.13
libspice-server1: 0.15.2-1+b1
lvm2: 2.03.31-2+pmx1
lxc-pve: 6.0.5-1
lxcfs: 6.0.4-pve1
novnc-pve: 1.6.0-3
proxmox-backup-client: 4.0.14-1
proxmox-backup-file-restore: 4.0.14-1
proxmox-backup-restore-image: 1.0.0
proxmox-firewall: 1.1.2
proxmox-kernel-helper: 9.0.4
proxmox-mail-forward: 1.0.2
proxmox-mini-journalreader: 1.6
proxmox-offline-mirror-helper: 0.7.1
proxmox-widget-toolkit: 5.0.5
pve-cluster: 9.0.6
pve-container: 6.0.10
pve-docs: 9.0.8
pve-edk2-firmware: 4.2025.02-4
pve-esxi-import-tools: 1.0.1
pve-firewall: 6.0.3
pve-firmware: 3.16-4
pve-ha-manager: 5.0.4
pve-i18n: 3.5.2
pve-qemu-kvm: 10.0.2-4
pve-xtermjs: 5.5.0-2
qemu-server: 9.0.19
smartmontools: 7.4-pve1
spiceterm: 3.4.0
swtpm: 0.8.0+pve2
vncterm: 1.9.0
zfsutils-linux: 2.3.4-pve1
and log from journalctl
Sep 10 09:42:40 proxmox-gl-01 esxi-folder-fus[1836]: proxmox-gl-01 esxi-folder-fuse[1836]: error handling request: cached read failed: error reading a body from connection
Caused by:
Connection reset by peer (os error 104)
Sep 10 09:42:40 proxmox-gl-01 pvedaemon[240542]: VM 101 creating disks failed
Sep 10 09:42:40 proxmox-gl-01 pvedaemon[240542]: unable to create VM 101 - cannot import from 'esx4:ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk' - copy failed: command '/usr/bin/qemu-img convert -p -n -f vmdk -O raw /run/pve/import/esxi/esx4/mnt/ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk zeroinit:/var/lib/pve/local-btrfs/images/101/vm-101-disk-0/disk.raw' failed: exit code 1
Sep 10 09:42:40 proxmox-gl-01 pvedaemon[87462]: <root@pam> end task UPID
 roxmox-gl-01:0003AB9E:007973B9:68C12B0A:qmcreate:101:root@pam: unable to create VM 101 - cannot import from 'esx4:ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk' - copy failed: command '/usr/bin/qemu-img convert -p -n -f vmdk -O raw /run/pve/import/esxi/esx4/mnt/ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk zeroinit:/var/lib/pve/local-btrfs/images/101/vm-101-disk-0/disk.raw' failed: exit code 1
roxmox-gl-01:0003AB9E:007973B9:68C12B0A:qmcreate:101:root@pam: unable to create VM 101 - cannot import from 'esx4:ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk' - copy failed: command '/usr/bin/qemu-img convert -p -n -f vmdk -O raw /run/pve/import/esxi/esx4/mnt/ha-datacenter/esx4-local/Ubnt.Srv/Ubnt.Srv.vmdk zeroinit:/var/lib/pve/local-btrfs/images/101/vm-101-disk-0/disk.raw' failed: exit code 1
")