It seems I run into the same situation as you.
Unfortunately I experienced this issue with 6 different servers (HP, Dell, Fujitsu and Intel servers).
All of them use almost the same configuration as storage:
- rpool (and production storage) on SSD
- rpools are: raidz10 (4 SSDs); raidz2 (4 and other ones 6 SSDs)
- SSDs are (usually one server contains only one kind of SSDs as devices): Kingston, Western Digital, Samsung
- local backups: raid1 spinning rusts
- usually they use motherboard SATA, PCIe sata card (cheap one), one use raid card, which support pass-trough
- all kvm drives set to support trim, I hoped the best
- turned out, trim is not supported on kernel level in some cases (due to HBA etc. prerequsities I guess), but the situation really differs from server to server, so, this should be not the core problem
- I use zfs-auto-snapshot, hourly, daily etc. on all production volumes/filesystems
- simplesnap usually in ever hour to remote server (it usually took some minutes and the start spread in an hour, so, only one remote copy happens at a time)
- daily simplesnap remote copy over internet to a remote location
- in one server only auto-snapshot, no remote copy
- zfs pools were upgraded in different times, they hanged before and after, too
- when the server hangs, it starts with increasing load, one increased it up to 1300 which a little bit high
") )))))))))
)))))))))
- The same servers were fine and worked for years without this kind of situation since PVE version 3.x, 4.x, 5.x
- Only started to happen with PVE 6.0
- It seems all zfs pool access hangs and systems die, only kernel can answer for ping, but remote connection impossible, login to local machine on physical terminal could work in the beginning, but after a time, it will became impossible, too
- two times happened the following: two of my oldest intel servers hanged with the same symptoms, nearly the same time (they usually simplesnap to each others in 40 minutes, so, it could trigger the dual die: first one of them dies, the second tries to zfs send/receive and dies, too, but it could be a false lead and not a real reason)
- today (8th of Sept, 2019) I upgraded to the latest version (pve-manager/6.0-7/28984024 (running kernel: 5.0.21-1-pve)), which contains new zfsutils-linux package, but I experienced the same situation with different subversions of PVE 6.0 (different kernels) before this version.
So, the only common point I can see is the zfs filesystem itself and it hangs in some reasons.
First time it happened after about 1 week uptime, but it seems this is unpredictable, so, I cannot guess, when will happen next time.
I will try to reboot these servers once a week and hope the best, it can avoid this situation.
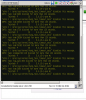
As I checked the zpool status -t output, I usually got that: SSDs are untrimmed, spinning rusts trim unsupported, as you can see in the following example:
root@lm4:~# zpool status -t
pool: rpool
state: ONLINE
scan: scrub repaired 0B in 0 days 00:13:31 with 0 errors on Sun Sep 8 00:37:32 2019
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sda2 ONLINE 0 0 0 (untrimmed)
sdb2 ONLINE 0 0 0 (untrimmed)
errors: No known data errors
pool: zbackup
state: ONLINE
scan: scrub repaired 0B in 0 days 02:08:04 with 0 errors on Sun Sep 8 02:32:07 2019
config:
NAME STATE READ WRITE CKSUM
zbackup ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ata-ST2000DM001-1CH164_Z1E8CR5S-part2 ONLINE 0 0 0 (trim unsupported)
ata-TOSHIBA_DT01ACA200_84649YHGS-part2 ONLINE 0 0 0 (trim unsupported)
mirror-1 ONLINE 0 0 0
ata-ST2000DM001-1ER164_W4Z07B1X ONLINE 0 0 0 (trim unsupported)
ata-TOSHIBA_DT01ACA200_84643E8GS ONLINE 0 0 0 (trim unsupported)
So, I suspect the following:
- general zfs 0.8.x race condition situation (I did not find specific issue on zfs email list yet)
- something weird with trim support switched on and underlying zfs/ssd
I hope my post contains enough details to get your attention
Anyway, it is a serious problem I never experienced with PVE/ZFS combination even from the beginning, when I had to compile zfs by myself on PVE 1.x




") Every 2nd Sunday (I just realized this now while reading this thread) I need to do a hard reset of my remote hosted node.
Every 2nd Sunday (I just realized this now while reading this thread) I need to do a hard reset of my remote hosted node.