Hi,
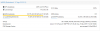
in Proxmox WebUI the monitor reports 88% memory allocation (see screenshot).
This data is confirmed by command free:
root@ld5505:~# free -h
total used free shared buff/cache available
Mem: 251G 221G 1,2G 125M 29G 130G
Swap: 29G 3,9G 25G
However, on this host only 1 VM is running with 130GB RAM:
root@ld5505:~# qm list
VMID NAME STATUS MEM(MB) BOOTDISK(GB) PID
102 vm102-sles12sp4 running 131072 20.00 128351
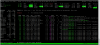
Comparing the RAM allocation with other tools show a different RAM usage: 130GB
Please check the second attachment displaying the output of glances.
This raises the following questions:
If the memory allocation displayed in Proxmox WebUI is correct, what is causing the memory leak?
If there's no memory leak as indicated by glances, why is Proxmox WebUI displaying an incorrect memory usage?
THX
in Proxmox WebUI the monitor reports 88% memory allocation (see screenshot).
This data is confirmed by command free:
root@ld5505:~# free -h
total used free shared buff/cache available
Mem: 251G 221G 1,2G 125M 29G 130G
Swap: 29G 3,9G 25G
However, on this host only 1 VM is running with 130GB RAM:
root@ld5505:~# qm list
VMID NAME STATUS MEM(MB) BOOTDISK(GB) PID
102 vm102-sles12sp4 running 131072 20.00 128351
Comparing the RAM allocation with other tools show a different RAM usage: 130GB
Please check the second attachment displaying the output of glances.
This raises the following questions:
If the memory allocation displayed in Proxmox WebUI is correct, what is causing the memory leak?
If there's no memory leak as indicated by glances, why is Proxmox WebUI displaying an incorrect memory usage?
THX