Sure thing, here's the host still with mitigations=off:Out of curiosity, can you post the output oflscpu?
Code:
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 32
On-line CPU(s) list: 0-31
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz
BIOS Model name: Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz CPU @ 3.3GHz
BIOS CPU family: 179
CPU family: 6
Model: 62
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 2
Stepping: 4
CPU(s) scaling MHz: 88%
CPU max MHz: 4000.0000
CPU min MHz: 1200.0000
BogoMIPS: 6600.37
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm c
onstant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 cx16
xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm cpuid_fault epb ssbd ibrs ibpb stibp tpr_shadow fl
expriority ept vpid fsgsbase smep erms xsaveopt dtherm ida arat pln pts vnmi md_clear flush_l1d
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 512 KiB (16 instances)
L1i: 512 KiB (16 instances)
L2: 4 MiB (16 instances)
L3: 50 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30
NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: KVM: Vulnerable
L1tf: Mitigation; PTE Inversion; VMX vulnerable
Mds: Vulnerable; SMT vulnerable
Meltdown: Vulnerable
Mmio stale data: Unknown: No mitigations
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Vulnerable
Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Srbds: Not affected
Tsx async abort: Not affected
Code:
# lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 30
On-line CPU(s) list: 0-29
Vendor ID: GenuineIntel
BIOS Vendor ID: QEMU
Model name: Intel(R) Xeon(R) CPU E5-2667 v2 @ 3.30GHz
BIOS Model name: pc-q35-8.1 CPU @ 2.0GHz
BIOS CPU family: 1
CPU family: 6
Model: 62
Thread(s) per core: 1
Core(s) per socket: 15
Socket(s): 2
Stepping: 4
BogoMIPS: 6599.99
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc arch
_perfmon rep_good nopl xtopology cpuid tsc_known_freq pni pclmulqdq vmx ssse3 cx16 pdcm pcid sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave
avx f16c rdrand hypervisor lahf_lm cpuid_fault ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust smep erms xsaveopt arat
umip md_clear flush_l1d arch_capabilities
Virtualization features:
Virtualization: VT-x
Hypervisor vendor: KVM
Virtualization type: full
Caches (sum of all):
L1d: 960 KiB (30 instances)
L1i: 960 KiB (30 instances)
L2: 120 MiB (30 instances)
L3: 32 MiB (2 instances)
NUMA:
NUMA node(s): 1
NUMA node0 CPU(s): 0-29
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: Not affected
L1tf: Mitigation; PTE Inversion; VMX vulnerable, SMT disabled
Mds: Vulnerable; SMT Host state unknown
Meltdown: Vulnerable
Mmio stale data: Unknown: No mitigations
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Vulnerable
Spectre v1: Vulnerable: __user pointer sanitization and usercopy barriers only; no swapgs barriers
Spectre v2: Vulnerable, IBPB: disabled, STIBP: disabled, PBRSB-eIBRS: Not affected
Srbds: Not affected
Tsx async abort: Not affectedYou are very probably right, when I disabled numa balancing / emulation, I did it for both host and guest at the same time, I had other settings enabled like CPU pinning, hugepages etc and turned stuff off until the issue disappeared.Note that one needs to differentiate between NUMA emulation for VMs [1], which is enabled on a per-VM basis (the "Enable NUMA" checkbox in the GUI), and the NUMA balancer, which is a kernel task running on the host [2] and thus affects all VMs running on that host. In my tests with the reproducer [3], it looks like a VM can freeze regardless of whether NUMA emulation is enabled or disabled for that VM, as long as the NUMA balancer is enabled on the (NUMA) host. So in other words, I don't think the value of the "Enable NUMA" checkbox for a VM makes any difference for the freezes.
[0] https://lore.kernel.org/all/20240110012045.505046-1-seanjc@google.com/
[1] https://pve.proxmox.com/pve-docs/pve-admin-guide.html#_numa
[2] https://doc.opensuse.org/documentation/leap/tuning/html/book-tuning/cha-tuning-numactl.html
[3] https://lore.kernel.org/kvm/832697b9-3652-422d-a019-8c0574a188ac@proxmox.com/T/#u
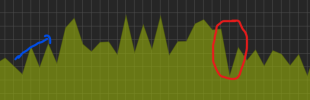
This is the CPU graph on the guest right after the upgrade of the host from 7 to 8 and until it settled again.

Last edited: