Hallo zusammen,
wir setzen in unserer Umgebung Proxmox als Hypervisor und Veeam als Backup-Software ein.
Aktuell haben wir derzeit ein Problem, bei dem der Veeam Worker nicht korrekt funktioniert. (beim Starten bzw. Initialisieren)
Backupjobs werden gestartet, allerdings wird der Veeamworker nicht erreicht oder ist noch in einem vorherigen Prozess. (Fehlermeldungen in den Anhängen als Bilder)
Folgende Historie...
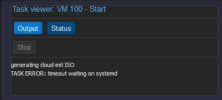
Zu Beginn wurden keine Backups mehr durchgeführt, der Job schlug fehl mit der Meldung, dass der Veeam Worker nicht erreicht werden konnte. In Proxmox war die VM des Veeam Workers noch im Startprozess (generating cloud-init ISO) und konnte nicht hochfahren. Ein manuelles Abbrechen der VM führte dazu, dass der nächste Backup-Vorgang erfolgreich verlief.
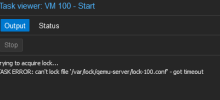
Ein weiterer Fehler trat auf, nachdem wir den Prozess über die Konsole beendet hatten: Proxmox zeigte an, dass die VM noch "in use" war, da ein Lock-File gesetzt war. Wir benannten das Lock-File um, damit die VM wieder startete. Seitdem wurde ein neues Lock-File erzeugt, und die VM scheint nicht mehr gestartet zu werden.
Veeam zeigt den Fehler "Timeout waiting on systemd" an.
Veeam 12.3.0.310
pve-manager/8.3.2/3e76eec21c4a14a7 (running kernel: 6.8.12-5-pve)
Nächster Plan war, den VeeamWorker einmal manuell zu starten, ob sich die VM überhaupt noch starten lässt.
Leider konnten wir das Problem bisher nicht lösen, und die Sicherungen laufen nicht mehr bzw. wenn nicht zuverlässig.
Hat jemand von euch ähnliche Erfahrungen gemacht oder eine Lösung bzw. Vorschlag parat?
Über jede Hilfe oder weiterführende Hinweise wären wir sehr dankbar!
Vielen Dank im Voraus!
VirtuSage
wir setzen in unserer Umgebung Proxmox als Hypervisor und Veeam als Backup-Software ein.
Aktuell haben wir derzeit ein Problem, bei dem der Veeam Worker nicht korrekt funktioniert. (beim Starten bzw. Initialisieren)
Backupjobs werden gestartet, allerdings wird der Veeamworker nicht erreicht oder ist noch in einem vorherigen Prozess. (Fehlermeldungen in den Anhängen als Bilder)
Folgende Historie...
Zu Beginn wurden keine Backups mehr durchgeführt, der Job schlug fehl mit der Meldung, dass der Veeam Worker nicht erreicht werden konnte. In Proxmox war die VM des Veeam Workers noch im Startprozess (generating cloud-init ISO) und konnte nicht hochfahren. Ein manuelles Abbrechen der VM führte dazu, dass der nächste Backup-Vorgang erfolgreich verlief.
Ein weiterer Fehler trat auf, nachdem wir den Prozess über die Konsole beendet hatten: Proxmox zeigte an, dass die VM noch "in use" war, da ein Lock-File gesetzt war. Wir benannten das Lock-File um, damit die VM wieder startete. Seitdem wurde ein neues Lock-File erzeugt, und die VM scheint nicht mehr gestartet zu werden.
Veeam zeigt den Fehler "Timeout waiting on systemd" an.
Veeam 12.3.0.310
pve-manager/8.3.2/3e76eec21c4a14a7 (running kernel: 6.8.12-5-pve)
Nächster Plan war, den VeeamWorker einmal manuell zu starten, ob sich die VM überhaupt noch starten lässt.
Leider konnten wir das Problem bisher nicht lösen, und die Sicherungen laufen nicht mehr bzw. wenn nicht zuverlässig.
Hat jemand von euch ähnliche Erfahrungen gemacht oder eine Lösung bzw. Vorschlag parat?
Über jede Hilfe oder weiterführende Hinweise wären wir sehr dankbar!
Vielen Dank im Voraus!
VirtuSage
Attachments



Last edited:
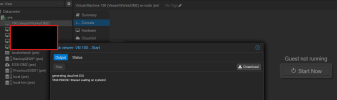

 ve01:00044F50:002BEE0F:67EEFE8F:qmstart:101:root@pam: to complete; TKOVA-AA : An unknown Proxmox VE error has occurred; There are no available workers in the cluster pve01. Performance may be affected; TS2019 : An unknown Proxmox VE error has occurred; Job finished with error at 4/3/2025 11:53:11 PM
ve01:00044F50:002BEE0F:67EEFE8F:qmstart:101:root@pam: to complete; TKOVA-AA : An unknown Proxmox VE error has occurred; There are no available workers in the cluster pve01. Performance may be affected; TS2019 : An unknown Proxmox VE error has occurred; Job finished with error at 4/3/2025 11:53:11 PM