Hi,
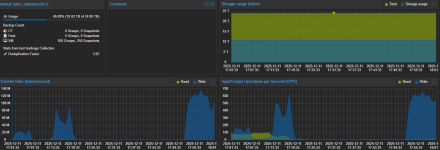
We have 2 PBS servers on same LAN different buildings, connected with 10Gbit fiber. PVE servers backup directly to one PBS and other PBS pull/sync (last 2 snapshots) from this PBS. We have about 10 TiB backup data to sync to remote PBS. The problem is, when I start the sync job it transfers data with about 800 mbit/s to 1.4gbit/s speed rates. Which is OK for us for the initial sync. But after a few hours passes the sync job speed crawls down to 50 - 100 mbit/s. When I stop the sync job and immediately start it again I see speed is normal (800 - 1400 mbit/s) for a couple of hours but eventually it slows down again. This is happening for 3 days now. The job should finished in about full day but after 3 days it's still could not finished with 3-4 TiB data remaining.
So why it stuck in such a slow speed for hours until I intervene (stop/start)? Any idea?
See the attached screenshots:
1: start of sync job
2: when it slowed down and stay at that speed
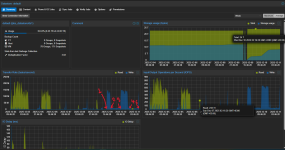
3: I wonder why it id not finished jet and see its too slow for hours. Then I stop and start the job again
4: It slows down again and stays at that speed
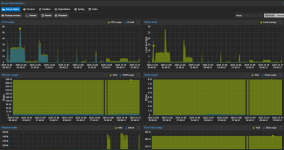
5: I check the job status and stop/start it again.
The job is running at 800-1300 mbit/s for now.
Here is some info About PBS servers.
primary PBS server:
16 x Intel(R) Xeon(R) CPU E5620 @ 2.40GHz (2 Sockets) / 192 GB RAM
single datastore, ZFS RaidZ2 with 10x8TB 7200 rpm Sata HDD + mirrored special device SSD + mirrored slog SSD
second PBS server:
32 x Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz (2 Sockets / 320 GB RAM
Dell Perc H710P/1G/BBU Raid10 with 6x8TB 7200 rpm sata HDD.
We have 2 PBS servers on same LAN different buildings, connected with 10Gbit fiber. PVE servers backup directly to one PBS and other PBS pull/sync (last 2 snapshots) from this PBS. We have about 10 TiB backup data to sync to remote PBS. The problem is, when I start the sync job it transfers data with about 800 mbit/s to 1.4gbit/s speed rates. Which is OK for us for the initial sync. But after a few hours passes the sync job speed crawls down to 50 - 100 mbit/s. When I stop the sync job and immediately start it again I see speed is normal (800 - 1400 mbit/s) for a couple of hours but eventually it slows down again. This is happening for 3 days now. The job should finished in about full day but after 3 days it's still could not finished with 3-4 TiB data remaining.
So why it stuck in such a slow speed for hours until I intervene (stop/start)? Any idea?
See the attached screenshots:
1: start of sync job
2: when it slowed down and stay at that speed
3: I wonder why it id not finished jet and see its too slow for hours. Then I stop and start the job again
4: It slows down again and stays at that speed
5: I check the job status and stop/start it again.
The job is running at 800-1300 mbit/s for now.
Here is some info About PBS servers.
primary PBS server:
16 x Intel(R) Xeon(R) CPU E5620 @ 2.40GHz (2 Sockets) / 192 GB RAM
single datastore, ZFS RaidZ2 with 10x8TB 7200 rpm Sata HDD + mirrored special device SSD + mirrored slog SSD
second PBS server:
32 x Intel(R) Xeon(R) CPU E5-2650 0 @ 2.00GHz (2 Sockets / 320 GB RAM
Dell Perc H710P/1G/BBU Raid10 with 6x8TB 7200 rpm sata HDD.
Attachments
Last edited:

")