I have compiled the latest version of the 6.17 kernel. I have also created a Container with Podman running in a LXC container on a ZFS storage filesystem. However, Overlay Fuse still causes a kernel panic in the new kernel that is available at the following link:
https://git.proxmox.com/?p=pve-kernel.git;a=summary — The next test kernel, if the internal testers approve of it. The version is 6.17.2-1-pve. There is no such Kernel Panic in 6.11.
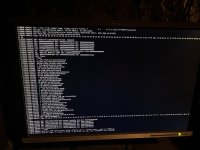
Code:
[ 292.391889] kauditd_printk_skb: 117 callbacks suppressed
[ 292.391891] audit: type=1400 audit(1761089695.167:129): apparmor="STATUS" operation="profile_load" profile="/usr/bin/lxc-start" name="lxc-109_</var/lib/lxc>" pid=4319 comm="apparmor_parser"
[ 292.616465] vmbr0: port 4(veth109i0) entered blocking state
[ 292.616477] vmbr0: port 4(veth109i0) entered disabled state
[ 292.616492] veth109i0: entered allmulticast mode
[ 292.616521] veth109i0: entered promiscuous mode
[ 292.647382] eth0: renamed from vethtCltG9
[ 292.859985] vmbr0: port 4(veth109i0) entered blocking state
[ 292.860001] vmbr0: port 4(veth109i0) entered forwarding state
[ 292.949013] overlayfs: fs on '/var/lib/containers/storage/overlay/compat2608751957/lower1' does not support file handles, falling back to xino=off.
[ 292.953942] overlayfs: fs on '/var/lib/containers/storage/overlay/metacopy-check1691818012/l1' does not support file handles, falling back to xino=off.
[ 292.953988] evm: overlay not supported
[ 292.960864] overlayfs: fs on '/var/lib/containers/storage/overlay/opaque-bug-check3427120332/l2' does not support file handles, falling back to xino=off.
[ 297.139424] podman0: port 1(veth0) entered blocking state
[ 297.139437] podman0: port 1(veth0) entered disabled state
[ 297.139985] veth0: entered allmulticast mode
[ 297.139987] overlayfs: fs on '/var/lib/containers/storage/overlay/l/DE7CQT5UZRNHHMTHIHAJPPW5J7' does not support file handles, falling back to xino=off.
[ 297.140011] veth0: entered promiscuous mode
[ 297.142067] podman0: port 1(veth0) entered blocking state
[ 297.142074] podman0: port 1(veth0) entered forwarding state
[ 297.286557] BUG: kernel NULL pointer dereference, address: 0000000000000018
[ 297.286570] #PF: supervisor read access in kernel mode
[ 297.286574] #PF: error_code(0x0000) - not-present page
[ 297.286577] PGD 0 P4D 0
[ 297.286581] Oops: Oops: 0000 [#1] SMP NOPTI
[ 297.286585] CPU: 4 UID: 100000 PID: 4840 Comm: crun Tainted: P OE 6.17.2-1-pve #1 PREEMPT(voluntary)
[ 297.286592] Tainted: [P]=PROPRIETARY_MODULE, [O]=OOT_MODULE, [E]=UNSIGNED_MODULE
[ 297.286596] Hardware name: Gigabyte Technology Co., Ltd. B650 AORUS ELITE AX ICE/B650 AORUS ELITE AX ICE, BIOS F36 07/31/2025
[ 297.286601] RIP: 0010:aa_file_perm+0xb7/0x3b0
[ 297.286606] Code: 45 31 c9 c3 cc cc cc cc 49 8b 47 20 41 8b 55 10 0f b7 00 66 25 00 f0 66 3d 00 c0 75 1c 41 f7 c4 46 00 10 00 75 13 49 8b 47 18 <48> 8b 40 18 66 83 78 10 01 0f 84 4a 01 00 00 89 d0 f7 d0 44 21 e0
[ 297.286614] RSP: 0018:ffffd4ebc9073680 EFLAGS: 00010246
[ 297.286618] RAX: 0000000000000000 RBX: ffff8dbe1edf1b80 RCX: ffff8dbe1b071d40
[ 297.286622] RDX: 0000000000000000 RSI: ffff8dbe19a93680 RDI: ffffffffbb2e756f
[ 297.286626] RBP: ffffd4ebc90736d8 R08: 0000000000000000 R09: 0000000000000000
[ 297.286629] R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000000
[ 297.286633] R13: ffff8dbe42b73258 R14: ffff8dbe1edf1b80 R15: ffff8dbe1b071d40
[ 297.286638] FS: 0000754b81212840(0000) GS:ffff8dc561d86000(0000) knlGS:0000000000000000
[ 297.286642] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 297.286645] CR2: 0000000000000018 CR3: 000000019e339000 CR4: 0000000000f50ef0
[ 297.286650] PKRU: 55555554
[ 297.286652] Call Trace:
[ 297.286655] <TASK>
[ 297.286658] common_file_perm+0x6c/0x1a0
[ 297.286662] apparmor_file_receive+0x42/0x80
[ 297.286666] security_file_receive+0x2e/0x50
[ 297.286669] receive_fd+0x1d/0xf0
[ 297.286673] scm_detach_fds+0xad/0x1c0
[ 297.286677] __scm_recv_common.isra.0+0x66/0x180
[ 297.286681] scm_recv_unix+0x30/0x130
[ 297.286684] ? unix_destroy_fpl+0x49/0xb0
[ 297.286687] __unix_dgram_recvmsg+0x2ac/0x450
[ 297.286691] unix_seqpacket_recvmsg+0x43/0x70
[ 297.286693] sock_recvmsg+0xde/0xf0
[ 297.286697] ____sys_recvmsg+0xa0/0x230
[ 297.286700] ? kfree_skbmem+0x7d/0xa0
[ 297.286869] ___sys_recvmsg+0xc7/0xf0
[ 297.287027] __sys_recvmsg+0x89/0x100
[ 297.287167] __x64_sys_recvmsg+0x1d/0x30
[ 297.287293] x64_sys_call+0x630/0x2330
[ 297.287415] do_syscall_64+0x80/0xa30
[ 297.287532] ? __rseq_handle_notify_resume+0xa9/0x490
[ 297.287648] ? restore_fpregs_from_fpstate+0x3d/0xc0
[ 297.287763] ? switch_fpu_return+0x5c/0xf0
[ 297.287878] ? do_syscall_64+0x25b/0xa30
[ 297.287991] ? do_syscall_64+0x25b/0xa30
[ 297.288102] ? __handle_mm_fault+0x95b/0xfd0
[ 297.288215] ? count_memcg_events+0xd7/0x1a0
[ 297.288327] ? handle_mm_fault+0x254/0x370
[ 297.288434] ? do_user_addr_fault+0x2f8/0x830
[ 297.288538] ? irqentry_exit_to_user_mode+0x2e/0x290
[ 297.288643] ? irqentry_exit+0x43/0x50
[ 297.288746] ? exc_page_fault+0x90/0x1b0
[ 297.288850] entry_SYSCALL_64_after_hwframe+0x76/0x7e
[ 297.288954] RIP: 0033:0x754b81396687
[ 297.289067] Code: 48 89 fa 4c 89 df e8 58 b3 00 00 8b 93 08 03 00 00 59 5e 48 83 f8 fc 74 1a 5b c3 0f 1f 84 00 00 00 00 00 48 8b 44 24 10 0f 05 <5b> c3 0f 1f 80 00 00 00 00 83 e2 39 83 fa 08 75 de e8 23 ff ff ff
[ 297.289179] RSP: 002b:00007fff7ed2d150 EFLAGS: 00000202 ORIG_RAX: 000000000000002f
[ 297.289292] RAX: ffffffffffffffda RBX: 0000754b81212840 RCX: 0000754b81396687
[ 297.289403] RDX: 0000000000000000 RSI: 00007fff7ed2d1a0 RDI: 000000000000000a
[ 297.289514] RBP: 00007fff7ed2d1a0 R08: 0000000000000000 R09: 0000000000000000
[ 297.289621] R10: 0000000000000000 R11: 0000000000000202 R12: 00007fff7ed2d820
[ 297.289726] R13: 0000000000000006 R14: 00007fff7ed2d820 R15: 000000000000000a
[ 297.289834] </TASK>
[ 297.289939] Modules linked in: nft_nat nft_ct nft_fib_inet nft_fib_ipv4 nft_fib_ipv6 nft_fib nft_masq nft_chain_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 tcp_diag inet_diag overlay veth ebtable_filter ebtables ip_set ip6table_raw iptable_raw ip6table_filter ip6_tables iptable_filter nf_tables sunrpc binfmt_misc 8021q garp mrp bonding tls nfnetlink_log input_leds hid_apple hid_generic usbmouse usbkbd btusb btrtl btintel btbcm btmtk usbhid bluetooth hid apple_mfi_fastcharge amd_atl intel_rapl_msr intel_rapl_common amdgpu iwlmvm mac80211 vfio_pci edac_mce_amd vfio_pci_core vfio_iommu_type1 libarc4 vfio kvm_amd iommufd amdxcp drm_panel_backlight_quirks gpu_sched drm_buddy kvm drm_ttm_helper ttm iwlwifi irqbypass drm_exec drm_suballoc_helper polyval_clmulni ghash_clmulni_intel aesni_intel drm_display_helper rapl cec pcspkr gigabyte_wmi wmi_bmof cfg80211 k10temp rc_core i2c_algo_bit ccp acpi_pad mac_hid sch_fq_codel vhost_net vhost vhost_iotlb tap vendor_reset(OE) efi_pstore nfnetlink dmi_sysfs ip_tables
[ 297.289968] x_tables autofs4 zfs(PO) spl(O) btrfs blake2b_generic xor raid6_pq nvme xhci_pci xhci_hcd ahci nvme_core r8169 i2c_piix4 libahci i2c_smbus realtek nvme_keyring nvme_auth video wmi
[ 297.290679] CR2: 0000000000000018
[ 297.290806] ---[ end trace 0000000000000000 ]---
[ 297.389198] RIP: 0010:aa_file_perm+0xb7/0x3b0
[ 297.389395] Code: 45 31 c9 c3 cc cc cc cc 49 8b 47 20 41 8b 55 10 0f b7 00 66 25 00 f0 66 3d 00 c0 75 1c 41 f7 c4 46 00 10 00 75 13 49 8b 47 18 <48> 8b 40 18 66 83 78 10 01 0f 84 4a 01 00 00 89 d0 f7 d0 44 21 e0
[ 297.389544] RSP: 0018:ffffd4ebc9073680 EFLAGS: 00010246
[ 297.389688] RAX: 0000000000000000 RBX: ffff8dbe1edf1b80 RCX: ffff8dbe1b071d40
[ 297.389826] RDX: 0000000000000000 RSI: ffff8dbe19a93680 RDI: ffffffffbb2e756f
[ 297.389963] RBP: ffffd4ebc90736d8 R08: 0000000000000000 R09: 0000000000000000
[ 297.390095] R10: 0000000000000000 R11: 0000000000000000 R12: 0000000000000000
[ 297.390220] R13: ffff8dbe42b73258 R14: ffff8dbe1edf1b80 R15: ffff8dbe1b071d40
[ 297.390346] FS: 0000754b81212840(0000) GS:ffff8dc561d86000(0000) knlGS:0000000000000000
[ 297.390472] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 297.390598] CR2: 0000000000000018 CR3: 000000019e339000 CR4: 0000000000f50ef0
[ 297.390725] PKRU: 55555554
[ 297.390851] note: crun[4840] exited with irqs disabled
[ 297.392338] ------------[ cut here ]------------
[ 297.392470] Voluntary context switch within RCU read-side critical section!
[ 297.392472] WARNING: CPU: 14 PID: 4840 at kernel/rcu/tree_plugin.h:332 rcu_note_context_switch+0x532/0x5a0
[ 297.392727] Modules linked in: nft_nat nft_ct nft_fib_inet nft_fib_ipv4 nft_fib_ipv6 nft_fib nft_masq nft_chain_nat nf_nat nf_conntrack nf_defrag_ipv6 nf_defrag_ipv4 tcp_diag inet_diag overlay veth ebtable_filter ebtables ip_set ip6table_raw iptable_raw ip6table_filter ip6_tables iptable_filter nf_tables sunrpc binfmt_misc 8021q garp mrp bonding tls nfnetlink_log input_leds hid_apple hid_generic usbmouse usbkbd btusb btrtl btintel btbcm btmtk usbhid bluetooth hid apple_mfi_fastcharge amd_atl intel_rapl_msr intel_rapl_common amdgpu iwlmvm mac80211 vfio_pci edac_mce_amd vfio_pci_core vfio_iommu_type1 libarc4 vfio kvm_amd iommufd amdxcp drm_panel_backlight_quirks gpu_sched drm_buddy kvm drm_ttm_helper ttm iwlwifi irqbypass drm_exec drm_suballoc_helper polyval_clmulni ghash_clmulni_intel aesni_intel drm_display_helper rapl cec pcspkr gigabyte_wmi wmi_bmof cfg80211 k10temp rc_core i2c_algo_bit ccp acpi_pad mac_hid sch_fq_codel vhost_net vhost vhost_iotlb tap vendor_reset(OE) efi_pstore nfnetlink dmi_sysfs ip_tables
[ 297.392761] x_tables autofs4 zfs(PO) spl(O) btrfs blake2b_generic xor raid6_pq nvme xhci_pci xhci_hcd ahci nvme_core r8169 i2c_piix4 libahci i2c_smbus realtek nvme_keyring nvme_auth video wmi
[ 297.393617] CPU: 14 UID: 100000 PID: 4840 Comm: crun Tainted: P D OE 6.17.2-1-pve #1 PREEMPT(voluntary)
[ 297.393780] Tainted: [P]=PROPRIETARY_MODULE, [D]=DIE, [O]=OOT_MODULE, [E]=UNSIGNED_MODULE
[ 297.393935] Hardware name: Gigabyte Technology Co., Ltd. B650 AORUS ELITE AX ICE/B650 AORUS ELITE AX ICE, BIOS F36 07/31/2025
[ 297.394095] RIP: 0010:rcu_note_context_switch+0x532/0x5a0
[ 297.394252] Code: ff 49 89 96 a8 00 00 00 e9 35 fd ff ff 45 85 ff 75 ef e9 2b fd ff ff 48 c7 c7 80 87 1f bb c6 05 d7 a8 49 02 01 e8 1e 1c f2 ff <0f> 0b e9 23 fb ff ff 4d 8b 74 24 20 4c 89 f7 e8 da ff 01 01 41 c6
[ 297.394419] RSP: 0018:ffffd4ebc9073c50 EFLAGS: 00010046
[ 297.394587] RAX: 0000000000000000 RBX: ffff8dbe9e26b040 RCX: 0000000000000000
[ 297.394752] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
[ 297.394920] RBP: ffffd4ebc9073c78 R08: 0000000000000000 R09: 0000000000000000
[ 297.395086] R10: 0000000000000000 R11: 0000000000000000 R12: ffff8dc51e733800
[ 297.395252] R13: 0000000000000000 R14: 0000000000000000 R15: ffff8dbe9e26be00
[ 297.395420] FS: 0000000000000000(0000) GS:ffff8dc562286000(0000) knlGS:0000000000000000
[ 297.395588] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 297.395756] CR2: 000077b8b7eb6510 CR3: 0000000819c3a000 CR4: 0000000000f50ef0
[ 297.395927] PKRU: 55555554
[ 297.396097] Call Trace:
[ 297.396268] <TASK>
[ 297.396439] __schedule+0xc6/0x1310
[ 297.396612] ? try_to_wake_up+0x392/0x8a0
[ 297.396785] ? kthread_insert_work+0xb8/0xe0
[ 297.396958] schedule+0x27/0xf0
[ 297.397128] synchronize_rcu_expedited+0x1c2/0x220
[ 297.397299] ? __pfx_autoremove_wake_function+0x10/0x10
[ 297.397472] ? __pfx_wait_rcu_exp_gp+0x10/0x10
[ 297.397644] namespace_unlock+0x258/0x330
[ 297.397817] put_mnt_ns+0x79/0xb0
[ 297.397988] free_nsproxy+0x16/0x190
[ 297.398160] switch_task_namespaces+0x74/0xa0
[ 297.398331] exit_task_namespaces+0x10/0x20
[ 297.398498] do_exit+0x2a8/0xa20
[ 297.398661] make_task_dead+0x93/0xa0
[ 297.398823] rewind_stack_and_make_dead+0x16/0x20
[ 297.398984] RIP: 0033:0x754b81396687
[ 297.399155] Code: Unable to access opcode bytes at 0x754b8139665d.
[ 297.399317] RSP: 002b:00007fff7ed2d150 EFLAGS: 00000202 ORIG_RAX: 000000000000002f
[ 297.399480] RAX: ffffffffffffffda RBX: 0000754b81212840 RCX: 0000754b81396687
[ 297.399643] RDX: 0000000000000000 RSI: 00007fff7ed2d1a0 RDI: 000000000000000a
[ 297.399802] RBP: 00007fff7ed2d1a0 R08: 0000000000000000 R09: 0000000000000000
[ 297.399957] R10: 0000000000000000 R11: 0000000000000202 R12: 00007fff7ed2d820
[ 297.400108] R13: 0000000000000006 R14: 00007fff7ed2d820 R15: 000000000000000a
[ 297.400256] </TASK>
[ 297.400399] ---[ end trace 0000000000000000 ]---
This patch addresses the issue:
https://github.com/jaminmc/pve-kern...NULL-pointer-dereference-in-aa_file_per.patch. This patch introduces a NULL check, preventing the Panic.
I am not seeking credit for this fix. I am surprised that not many others have experienced the kernel panic. I encountered it during my initial attempt to use any 6.16 or 6.17 kernels from the Ubuntu kernel, applying the Proxmox patches myself before 6.17 was available on the Proxmox git repository.




")