Moin, ich habe hier ähnliche Probleme, seit dem letzten Update gibt es die gleichen Auswirkungen wie hier beschrieben und etwas extra. Der Cluster besteht aus insgesamt 8 Hosts, HA Group AMD 2x EPYC 7351p und 2x 7543, HA Group Intel 3x Xeon E52640 v4 1x E5-2637 v3, Storage kommt ausschließlich von einem externen CEPH Cluster. Die Crash Problematik scheint bis jetzt nur auf den AMD's aufzutreten, die VM CPU's sind auf EPYC beschränkt die Intel's auf SandyBridge und Migration hat damit vorher auch sauber funktioniert.
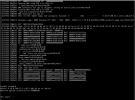
VM Migrieren, Linux VM's crashen entweder sofort, oder sind Stuck mit 100% CPU. Was mir mehr Sorgen bereitet, es sind auch VM's betroffen die überhaupt nicht migriert worden sind, die dann auf einmal auch Crashen. Bei einer Windows VM konnte ich zufällig sehen das sich die Uhrzeit auf +27h geändert hat, angehängter Screenshot ist von einer VM die überhaupt nicht angerührt wurde aber trotzdem gecrashed ist.
Hat jemand auch Probleme das VM's crashen die nicht migriert worden sind?
Viele Grüße
Matthias