Hi,
last week I moved VMs to an fresh installed new cluster-node, but it's don't run well. Most of the VMs has massive trouble to do IO.
After migrating all VM-Disks to ceph (local-zfs before) the VMs work.
The big quesiton is, where are the issue? Host-Kernel?
The system is an Dell R6515 with 48 x AMD EPYC 7402P 24-Core Processor, 384GB Ram, actual Bios 2.7.3 and following pve-version:
The zfs mem is limited
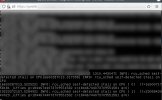
Error inside client (there are different io related errors on different clients):
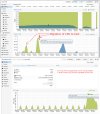
The IO on the host is not realy high during this time (wait ~6%)
Due the migrated VMs I can hopefully change the next node during this week and can test there settings, kernel and so on…
Any hints?
Udo
last week I moved VMs to an fresh installed new cluster-node, but it's don't run well. Most of the VMs has massive trouble to do IO.
After migrating all VM-Disks to ceph (local-zfs before) the VMs work.
The big quesiton is, where are the issue? Host-Kernel?
The system is an Dell R6515 with 48 x AMD EPYC 7402P 24-Core Processor, 384GB Ram, actual Bios 2.7.3 and following pve-version:
Code:
proxmox-ve: 7.2-1 (running kernel: 5.15.39-1-pve)
pve-manager: 7.2-7 (running version: 7.2-7/d0dd0e85)
pve-kernel-5.15: 7.2-6
pve-kernel-helper: 7.2-6
pve-kernel-5.13: 7.1-9
pve-kernel-5.15.39-1-pve: 5.15.39-1
pve-kernel-5.13.19-6-pve: 5.13.19-15
pve-kernel-5.13.19-2-pve: 5.13.19-4
ceph-fuse: 15.2.16-pve1
corosync: 3.1.5-pve2
criu: 3.15-1+pve-1
glusterfs-client: 9.2-1
ifupdown2: 3.1.0-1+pmx3
ksm-control-daemon: 1.4-1
libjs-extjs: 7.0.0-1
libknet1: 1.24-pve1
libproxmox-acme-perl: 1.4.2
libproxmox-backup-qemu0: 1.3.1-1
libpve-access-control: 7.2-4
libpve-apiclient-perl: 3.2-1
libpve-common-perl: 7.2-2
libpve-guest-common-perl: 4.1-2
libpve-http-server-perl: 4.1-3
libpve-storage-perl: 7.2-7
libspice-server1: 0.14.3-2.1
lvm2: 2.03.11-2.1
lxc-pve: 5.0.0-3
lxcfs: 4.0.12-pve1
novnc-pve: 1.3.0-3
openvswitch-switch: 2.15.0+ds1-2+deb11u1
proxmox-backup-client: 2.2.5-1
proxmox-backup-file-restore: 2.2.5-1
proxmox-mini-journalreader: 1.3-1
proxmox-widget-toolkit: 3.5.1
pve-cluster: 7.2-2
pve-container: 4.2-2
pve-docs: 7.2-2
pve-edk2-firmware: 3.20210831-2
pve-firewall: 4.2-5
pve-firmware: 3.5-1
pve-ha-manager: 3.4.0
pve-i18n: 2.7-2
pve-qemu-kvm: 6.2.0-11
pve-xtermjs: 4.16.0-1
qemu-server: 7.2-3
smartmontools: 7.2-pve3
spiceterm: 3.2-2
swtpm: 0.7.1~bpo11+1
vncterm: 1.7-1
zfsutils-linux: 2.1.4-pve1
Code:
cat /etc/modprobe.d/zfs.conf
options zfs zfs_arc_min=16106127360
options zfs zfs_arc_max=17179869184
Code:
Aug 2 20:55:53 vdb01 kernel: [19672.059835] watchdog: BUG: soft lockup - CPU#0 stuck for 34s! [swapper/0:0]
Aug 2 20:55:53 vdb01 kernel: [19672.061236] Modules linked in: edac_mce_amd input_leds joydev serio_raw shpchp qemu_fw_cfg mac_hid sch_fq_codel sunrpc ib_iser rdma_cm iw_cm ib_cm i
b_core iscsi_tcp libiscsi_tcp libiscsi scsi_transport_iscsi ip_tables x_tables autofs4 btrfs zstd_compress raid10 raid456 async_raid6_recov async_memcpy async_pq async_xor async_tx xor rai
d6_pq libcrc32c raid1 raid0 multipath linear pcbc bochs_drm ttm aesni_intel drm_kms_helper aes_x86_64 crypto_simd glue_helper cryptd syscopyarea sysfillrect sysimgblt psmouse virtio_net vi
rtio_scsi fb_sys_fops drm i2c_piix4 pata_acpi floppy
Aug 2 20:55:53 vdb01 kernel: [19672.061266] CPU: 0 PID: 0 Comm: swapper/0 Tainted: G L 4.15.0-176-generic #185-Ubuntu
Aug 2 20:55:53 vdb01 kernel: [19672.061267] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.15.0-0-g2dd4b9b3f840-prebuilt.qemu.org 04/01/2014
Aug 2 20:55:53 vdb01 kernel: [19672.061274] RIP: 0010:native_safe_halt+0x12/0x20
Aug 2 20:55:53 vdb01 kernel: [19672.061275] RSP: 0018:ffffffffa0e03e28 EFLAGS: 00000246 ORIG_RAX: ffffffffffffff11
Aug 2 20:55:53 vdb01 kernel: [19672.061276] RAX: ffffffffa03d0a50 RBX: 0000000000000000 RCX: 0000000000000000
Aug 2 20:55:53 vdb01 kernel: [19672.061277] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
Aug 2 20:55:53 vdb01 kernel: [19672.061278] RBP: ffffffffa0e03e28 R08: 0000000000000002 R09: ffffb2344124fe30
Aug 2 20:55:53 vdb01 kernel: [19672.061278] R10: 0000000000000005 R11: 0000000000000000 R12: 0000000000000000
Aug 2 20:55:53 vdb01 kernel: [19672.061279] R13: 0000000000000000 R14: 0000000000000000 R15: 0000000000000000
Aug 2 20:55:53 vdb01 kernel: [19672.061282] FS: 0000000000000000(0000) GS:ffff9f7f7fc00000(0000) knlGS:0000000000000000
Aug 2 20:55:53 vdb01 kernel: [19672.061282] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
Aug 2 20:55:53 vdb01 kernel: [19672.061283] CR2: 00007f85fee92180 CR3: 0000000231a1e000 CR4: 00000000000006f0
Aug 2 20:55:53 vdb01 kernel: [19672.061287] Call Trace:
Aug 2 20:55:53 vdb01 kernel: [19672.061291] default_idle+0x20/0x100
Aug 2 20:55:53 vdb01 kernel: [19672.061295] arch_cpu_idle+0x15/0x20
Aug 2 20:55:53 vdb01 kernel: [19672.061296] default_idle_call+0x23/0x30
Aug 2 20:55:53 vdb01 kernel: [19672.061299] do_idle+0x172/0x1f0
Aug 2 20:55:53 vdb01 kernel: [19672.061300] cpu_startup_entry+0x73/0x80
Aug 2 20:55:53 vdb01 kernel: [19672.061303] rest_init+0xae/0xb0
Aug 2 20:55:53 vdb01 kernel: [19672.061306] start_kernel+0x4dc/0x500
Aug 2 20:55:53 vdb01 kernel: [19672.061308] x86_64_start_reservations+0x24/0x26
Aug 2 20:55:53 vdb01 kernel: [19672.061309] x86_64_start_kernel+0x74/0x77
Aug 2 20:55:53 vdb01 kernel: [19672.061312] secondary_startup_64+0xa5/0xb0
Aug 2 20:55:53 vdb01 kernel: [19672.061313] Code: 00 3e 80 48 02 20 48 8b 00 a8 08 0f 84 7b ff ff ff eb bd 90 90 90 90 90 90 55 48 89 e5 e9 07 00 00 00 0f 00 2d 00 90 43 00 fb f4 <
5d> c3 66 90 66 2e 0f 1f 84 00 00 00 00 00 55 48 89 e5 e9 07 00
Aug 2 20:58:58 vdb01 kernel: [19857.455318] INFO: rcu_sched self-detected stall on CPU
Aug 2 20:58:58 vdb01 kernel: [19857.456302] 0-...!: (1 ticks this GP) idle=91e/1/0 softirq=1110456/1110456 fqs=0
Aug 2 20:58:58 vdb01 kernel: [19857.457715] (t=44897 jiffies g=417485 c=417484 q=8814)
Aug 2 20:58:58 vdb01 kernel: [19857.458721] rcu_sched kthread starved for 44897 jiffies! g417485 c417484 f0x0 RCU_GP_WAIT_FQS(3) ->state=0x402 ->cpu=0
Aug 2 20:58:58 vdb01 kernel: [19857.460707] rcu_sched I 0 8 2 0x80000000
Aug 2 20:58:58 vdb01 kernel: [19857.460709] Call Trace:
Aug 2 20:58:58 vdb01 kernel: [19857.460717] __schedule+0x24e/0x890
Aug 2 20:58:58 vdb01 kernel: [19857.460719] schedule+0x2c/0x80
Aug 2 20:58:58 vdb01 kernel: [19857.460720] schedule_timeout+0x15d/0x370
Aug 2 20:58:58 vdb01 kernel: [19857.460723] ? __next_timer_interrupt+0xe0/0xe0
Aug 2 20:58:58 vdb01 kernel: [19857.460726] rcu_gp_kthread+0x53a/0x980
Aug 2 20:58:58 vdb01 kernel: [19857.460729] kthread+0x121/0x140
Aug 2 20:58:58 vdb01 kernel: [19857.460730] ? rcu_note_context_switch+0x150/0x150
Aug 2 20:58:58 vdb01 kernel: [19857.460731] ? kthread_create_worker_on_cpu+0x70/0x70
Aug 2 20:58:58 vdb01 kernel: [19857.460732] ret_from_fork+0x22/0x40
Aug 2 20:58:58 vdb01 kernel: [19857.460736] NMI backtrace for cpu 0
Aug 2 20:58:58 vdb01 kernel: [19857.460739] CPU: 0 PID: 0 Comm: swapper/0 Tainted: G L 4.15.0-176-generic #185-Ubuntu
Aug 2 20:58:58 vdb01 kernel: [19857.460739] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS rel-1.15.0-0-g2dd4b9b3f840-prebuilt.qemu.org 04/01/2014
Aug 2 20:58:58 vdb01 kernel: [19857.460739] Call Trace:
Aug 2 20:58:58 vdb01 kernel: [19857.460740] <IRQ>
Aug 2 20:58:58 vdb01 kernel: [19857.460742] dump_stack+0x6d/0x8b
Aug 2 20:58:58 vdb01 kernel: [19857.460744] nmi_cpu_backtrace+0x94/0xa0
Aug 2 20:58:58 vdb01 kernel: [19857.460747] ? lapic_can_unplug_cpu+0xb0/0xb0
Aug 2 20:58:58 vdb01 kernel: [19857.460748] nmi_trigger_cpumask_backtrace+0xe7/0x130
Aug 2 20:58:58 vdb01 kernel: [19857.460749] arch_trigger_cpumask_backtrace+0x19/0x20
Aug 2 20:58:58 vdb01 kernel: [19857.460751] rcu_dump_cpu_stacks+0xa3/0xd5
Aug 2 20:58:58 vdb01 kernel: [19857.460752] rcu_check_callbacks+0x6cd/0x8e0
Aug 2 20:58:58 vdb01 kernel: [19857.460756] ? tick_sched_do_timer+0x50/0x50
Aug 2 20:58:58 vdb01 kernel: [19857.460757] update_process_times+0x2f/0x60
Aug 2 20:58:58 vdb01 kernel: [19857.460758] tick_sched_handle+0x26/0x70
Aug 2 20:58:58 vdb01 kernel: [19857.460759] ? tick_sched_do_timer+0x42/0x50
Aug 2 20:58:58 vdb01 kernel: [19857.460760] tick_sched_timer+0x39/0x80
Aug 2 20:58:58 vdb01 kernel: [19857.460762] __hrtimer_run_queues+0xdf/0x230
Aug 2 20:58:58 vdb01 kernel: [19857.460765] hrtimer_interrupt+0xa0/0x1d0
Aug 2 20:58:58 vdb01 kernel: [19857.460768] smp_apic_timer_interrupt+0x6f/0x140
Aug 2 20:58:58 vdb01 kernel: [19857.460770] apic_timer_interrupt+0x90/0xa0
Aug 2 20:58:58 vdb01 kernel: [19857.460770] </IRQ>
Aug 2 20:58:58 vdb01 kernel: [19857.460772] RIP: 0010:native_safe_halt+0x12/0x20
Aug 2 20:58:58 vdb01 kernel: [19857.460773] RSP: 0018:ffffffffa0e03e28 EFLAGS: 00000246 ORIG_RAX: ffffffffffffff11
Aug 2 20:58:58 vdb01 kernel: [19857.460775] RAX: ffffffffa03d0a50 RBX: 0000000000000000 RCX: 0000000000000000
Aug 2 20:58:58 vdb01 kernel: [19857.460776] RDX: 0000000000000000 RSI: 0000000000000000 RDI: 0000000000000000
Aug 2 20:58:58 vdb01 kernel: [19857.460776] RBP: ffffffffa0e03e28 R08: 0000000000000002 R09: 0000000000000002
Aug 2 20:58:58 vdb01 kernel: [19857.460777] R10: 0000000000100000 R11: 0000000000000000 R12: 0000000000000000
Aug 2 20:58:58 vdb01 kernel: [19857.460777] R13: 0000000000000000 R14: 0000000000000000 R15: 0000000000000000
Aug 2 20:58:58 vdb01 kernel: [19857.460779] ? __sched_text_end+0x1/0x1
Aug 2 20:58:58 vdb01 kernel: [19857.460780] default_idle+0x20/0x100
Aug 2 20:58:58 vdb01 kernel: [19857.460783] arch_cpu_idle+0x15/0x20
Aug 2 20:58:58 vdb01 kernel: [19857.460784] default_idle_call+0x23/0x30
Aug 2 20:58:58 vdb01 kernel: [19857.460786] do_idle+0x172/0x1f0
Aug 2 20:58:58 vdb01 kernel: [19857.460787] cpu_startup_entry+0x73/0x80
Aug 2 20:58:58 vdb01 kernel: [19857.460788] rest_init+0xae/0xb0
Aug 2 20:58:58 vdb01 kernel: [19857.460791] start_kernel+0x4dc/0x500
Aug 2 20:58:58 vdb01 kernel: [19857.460793] x86_64_start_reservations+0x24/0x26
Aug 2 20:58:58 vdb01 kernel: [19857.460794] x86_64_start_kernel+0x74/0x77
Aug 2 20:58:58 vdb01 kernel: [19857.460796] secondary_startup_64+0xa5/0xb0
Code:
ATOP - pve08 2022/08/02 21:07:14 ---------------- 10m0s elapsed
PRC | sys 6m54s | user 88m19s | | #proc 827 | #trun 10 | #tslpi 969 | | #tslpu 0 | #zombie 0 | clones 126e4 | | #exit >62415 |
CPU | sys 173% | user 884% | irq 6% | idle 3731% | wait 6% | steal 0% | guest 858% | | ipc 1.14 | cycl 756MHz | curf 2.94GHz | curscal ?% |
CPL | avg1 10.70 | avg5 10.83 | | avg15 10.76 | | | csw 61541446 | intr 48058e3 | | | numcpu 48 | |
MEM | tot 377.3G | free 214.1G | cache 1.1G | dirty 0.1M | buff 1.1M | slab 14.0G | slrec 93.1M | shmem 163.0M | shrss 0.0M | vmbal 0.0M | zfarc 78.6G | hptot 0.0M |
SWP | tot 0.0M | free 0.0M | | | | swcac 0.0M | | | | vmcom 181.3G | | vmlim 188.7G |
PSI | cpusome 0% | memsome 0% | memfull 0% | iosome 0% | iofull 0% | cs 0/0/0 | | ms 0/0/0 | mf 0/0/0 | is 0/0/0 | if 0/0/0 | |
DSK | nvme0n1 | busy 23% | read 2341879 | | write 215248 | KiB/r 13 | KiB/w 62 | MBr/s 50.0 | MBw/s 21.7 | | avq 2.36 | avio 53.1 µs |
DSK | nvme1n1 | busy 23% | read 2341757 | | write 218268 | KiB/r 13 | KiB/w 61 | MBr/s 49.9 | MBw/s 21.7 | | avq 2.37 | avio 53.0 µs |
NFC | rpc 120 | read 0 | write 0 | | retxmit 0 | autref 120 | | | | | | |
NET | transport | tcpi 5691913 | tcpo 26574e3 | udpi 194747 | udpo 195878 | tcpao 962 | tcppo 281 | tcprs 6979 | tcpie 0 | tcpor 669 | udpnp 0 | udpie 0 |
NET | network | ipi 5886747 | ipo 4361404 | | ipfrw 0 | deliv 5887e3 | | | | | icmpi 24 | icmpo 0 |
NET | enp196s ---- | pcki 5670759 | pcko 26556e3 | sp 0 Mbps | si 6072 Kbps | so 3164 Mbps | coll 0 | mlti 330 | erri 0 | erro 0 | drpi 0 | drpo 0 |
NET | vlan130 ---- | pcki 5670347 | pcko 4141809 | sp 0 Mbps | si 5013 Kbps | so 3144 Mbps | coll 0 | mlti 0 | erri 0 | erro 0 | drpi 0 | drpo 0 |
Only 62415 exited processes handled -- 1190531 skipped!
PID SYSCPU USRCPU RDELAY VGROW RGROW RDDSK WRDSK RUID EUID ST EXC THR S CPUNR CPU CMD 1/1747
445040 9.72s 11m07s 1.18s 208.0M 51244K 37944K 275.4M root root -- - 9 S 41 114% kvm
2125592 2.12s 10m33s 0.43s 0K 0K 12K 21588K root root -- - 8 S 41 106% kvm
2296177 1.76s 10m00s 0.53s 0K 47104K 22560K 778.3M root root -- - 8 S 40 101% kvm
492051 0.31s 10m00s 0.15s 0K 0K 0K 0K root root -- - 5 S 41 101% kvm
4157 0.32s 10m00s 0.27s 0K 0K 0K 0K root root -- - 5 S 40 101% kvm
2335094 16.96s 8m35s 1.44s 1.5G 1.5G 37.1G 3.1G root root -- - 42 S 3 89% kvm
3560137 1.19s 7m39s 0.34s 0K -20K 5164K 45872K root root -- - 6 S 18 77% kvm
212929 3.24s 6m23s 0.30s 0K 0K 1.0G 1.9G root root -- - 7 S 6 65% kvmAny hints?
Udo