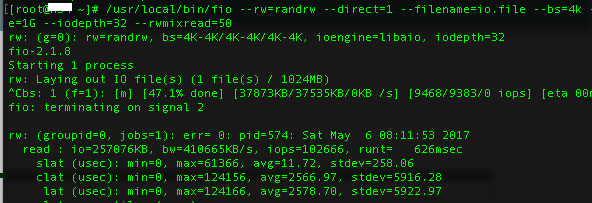
Hi,
I write here as I have a related questions. Let first clear few of the existing above. There is a way to have persistence of the config (documented enough in
https://pve.proxmox.com/wiki/Manual:_pct.conf):
> It is also possible to add low-level LXC-style configuration directly, for example:
> lxc.init_cmd: /sbin/my_own_init
The correct way to add resource limits to LXC containers in the Proxmox PVE is (was) to add to /etc/pve/lxc/CID.conf (for example /etc/pve/lxc/101.conf: ):
lxc.cgroup.blkio.throttle.read_iops_device: 251:7 60
lxc.cgroup.blkio.throttle.write_iops_device: 251:7 60
This will add (lxc will add it on start of the container) the above values to /sys/fs/cgroups/blkio/lxc/101/blkio.throttle.read_iops_device and to /sys/fs/cgroups/blkio/lxc/101/blkio.throttle.write_iops_device
Just browse the /sys/fs/cgroups or search for related docs. For all these to work there is one MANDATORY requirement:
The pid of the process(es) involved should be present in /sys/fs/cgroups/blkio/lxc/101/tasks and/or /sys/fs/cgroups/blkio/lxc/101/cgroup.procs. The difference is that cgroup.procs contains PIDs, where tasks contains as well the thread IDs. LXC fill these two files with all PIDs/ThreadIDs of all processes running in the container (101 in the example). For cgroups to work settings and tasks should be present in one dir (one cgroup). In other words: cgroups applies limit's settings for all tasks listed in the same dir.
Unfortunately the Proxmox team decide to break this (I have no explanation why) with lxc-pve_2.0.5-2_amd64.deb and later versions. Up to version lxc-pve_2.0.5-1_amd64.deb the above functionality works fine. Starting with lxc-pve_2.0.5-2_amd64.deb they put one additional name space and now all goes to /sys/fs/cgroups/blkio/lxc/101/ns dir. Unfortunately they broke the compatibility with their own documentation and now
https://pve.proxmox.com/wiki/Manual:_pct.conf is misleading. Now if you add the above two lines to /etc/pve/lxc/101.conf the LXC will add the settings in /sys/fs/cgroups/blkio/lxc/101 on startup, but later LXC will add PIDs and thread IDs to /sys/fs/cgroups/blkio/lxc/101/ns. As effect the settings (limits) are in one cgroup level in the hierarchy, when at the same time pids are in another level (in ns subdir). You still should be able to add the settings manually (echo 251:7 60 > /sys/fs/cgroups/blkio/lxc/101/ns/blkio.throttle.read_iops_device), but this lack persistence.
I will be really grateful to hear some comments from the Proxmox team.