Hey all,
First let me explain my setup. My Proxmox box boots off of a ZFS mirror of two 500GB SSD's. I also have a secondary ZFS pool consisting of 12 spinning disks, 2 SSD SLOG ZIL devices and 2 SSD L2ARC devices, which I use for data storage. I am in the middle of a slow project to one by one replace my old 4TB drives with new 10TB drives and resilver to grow the pool.
On average I replace one disk per week. ~6 weeks in, I am halfway through this project.
Original configuration prior to start of project:
Current configuration of storage pool now that I am halfway through:
As you can see, six of the old WD Red 4TB drives have been replaced with 10TB Seagate Enterprise drives.
I've gotten a few spurious email notifications of SMART errors in the past, but this morning is when it took off for real. My phone was buzzing a lot notifying me of SMART errors:
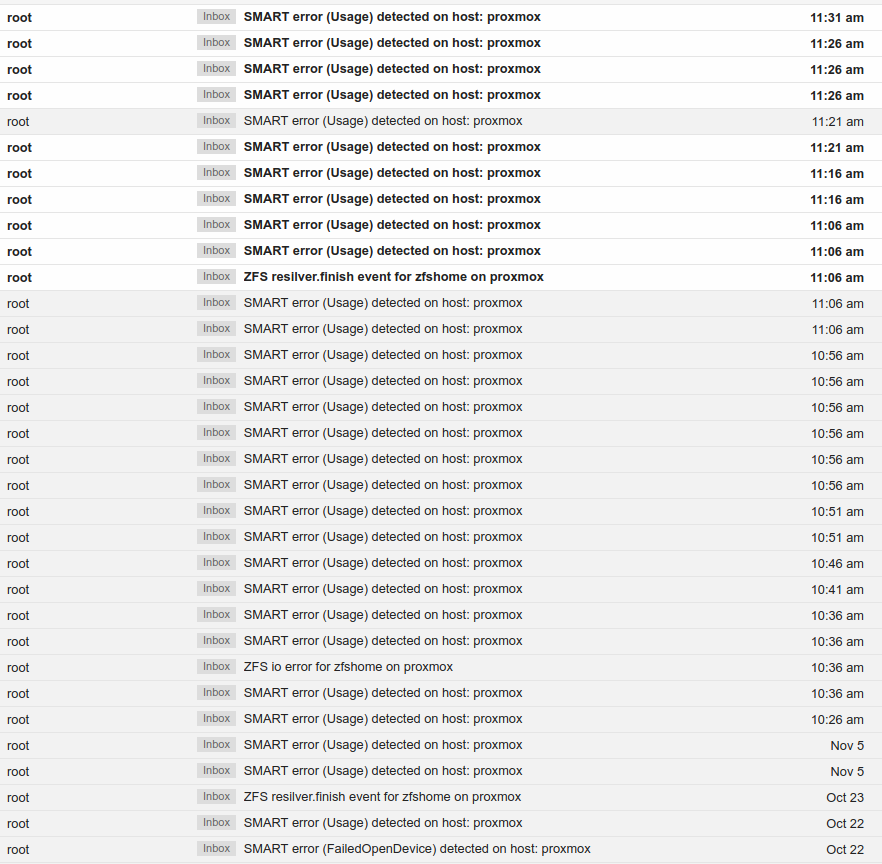
Every single one of the SMART notifications are for WD drives with serial numbers that are no longer in the system, some haven't been in the system for 6 weeks! When I log on to the Proxmox server, and look at drive status and pool status, everything is fine.
The ZFS Resilver notification seems legit, but for some reason is about 3 days late.
Any clue what is going on here? Is this smartd getting confused because I hot swapped the drives, and linux is still using the same /dev/sdx device names? Can I restart smartd to force it to do a fresh read of what drives are actually in the system?
Also, why are the email notifications that ARE legitimate, usually 3 days late?
Appreciate any help!
Thanks,
Matt
First let me explain my setup. My Proxmox box boots off of a ZFS mirror of two 500GB SSD's. I also have a secondary ZFS pool consisting of 12 spinning disks, 2 SSD SLOG ZIL devices and 2 SSD L2ARC devices, which I use for data storage. I am in the middle of a slow project to one by one replace my old 4TB drives with new 10TB drives and resilver to grow the pool.
On average I replace one disk per week. ~6 weeks in, I am halfway through this project.
Original configuration prior to start of project:
Code:
pool: rpool
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
ata-Samsung_SSD_850_EVO_500GB ONLINE 0 0 0
ata-Samsung_SSD_850_EVO_500GB ONLINE 0 0 0
pool: zfshome
config:
NAME STATE READ WRITE CKSUM
zfshome ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
logs
mirror-2 ONLINE 0 0 0
ata-INTEL_SSDSC2BA100G3 ONLINE 0 0 0
ata-INTEL_SSDSC2BA100G3 ONLINE 0 0 0
cache
ata-Samsung_SSD_850_PRO_512GB ONLINE 0 0 0
ata-Samsung_SSD_850_PRO_512GB ONLINE 0 0 0Current configuration of storage pool now that I am halfway through:
Code:
pool: zfshome
config:
NAME STATE READ WRITE CKSUM
zfshome ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
ata-ST10000NM0016-1TT101 ONLINE 0 0 0
ata-ST10000NM0016-1TT101 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-ST10000NM0016-1TT101 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
raidz2-1 ONLINE 0 0 0
ata-ST10000NM0016-1TT101 ONLINE 0 0 0
ata-ST10000NM0016-1TT101 ONLINE 0 0 0
ata-ST10000NM0016-1TT101 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
ata-WDC_WD40EFRX-68WT0N0 ONLINE 0 0 0
logs
mirror-2 ONLINE 0 0 0
ata-INTEL_SSDSC2BA100G3 ONLINE 0 0 0
ata-INTEL_SSDSC2BA100G3 ONLINE 0 0 0
cache
ata-Samsung_SSD_850_PRO_512GB ONLINE 0 0 0
ata-Samsung_SSD_850_PRO_512GB ONLINE 0 0 0As you can see, six of the old WD Red 4TB drives have been replaced with 10TB Seagate Enterprise drives.
I've gotten a few spurious email notifications of SMART errors in the past, but this morning is when it took off for real. My phone was buzzing a lot notifying me of SMART errors:
Every single one of the SMART notifications are for WD drives with serial numbers that are no longer in the system, some haven't been in the system for 6 weeks! When I log on to the Proxmox server, and look at drive status and pool status, everything is fine.
The ZFS Resilver notification seems legit, but for some reason is about 3 days late.
Any clue what is going on here? Is this smartd getting confused because I hot swapped the drives, and linux is still using the same /dev/sdx device names? Can I restart smartd to force it to do a fresh read of what drives are actually in the system?
Also, why are the email notifications that ARE legitimate, usually 3 days late?
Appreciate any help!
Thanks,
Matt
