Hello,
I have multiple Proxmox instances all are running on hp del360 gen8
Today I added 2x RAM and 2x SSD to one of my servers. I haven't yet started to use new hard drvies(level 1 RAID at hardware level).
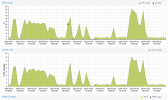
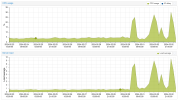
My VMs became too slow. I think my RAM performance is okay but CPU usage jumps to sky when I start using VMs on this node.
I have a Kubernetes VM worker and when I start scheduling workload on it cpu usage goes high - RAM usage stays low (I believe reason is that poor CPU performance does not let workload to start and use memory). I believe this problem is not related to disk I/O since my workload doesn't use any disk (rarely).
Here information related to my proxmox cpu:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz
BIOS Model name: Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz CPU @ 2.0GHz
BIOS CPU family: 179
CPU family: 6
Model: 45
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
Stepping: 7
CPU(s) scaling MHz: 97%
CPU max MHz: 2500.0000
CPU min MHz: 1200.0000
BogoMIPS: 3990.43
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pd
pe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor
ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx lahf_lm epb pti ibr
s ibpb stibp tpr_shadow flexpriority ept vpid xsaveopt dtherm ida arat pln pts vnmi
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 384 KiB (12 instances)
L1i: 384 KiB (12 instances)
L2: 3 MiB (12 instances)
L3: 30 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: KVM: Mitigation: Split huge pages
L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable
Meltdown: Mitigation; PTI
Mmio stale data: Unknown: No mitigations
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Vulnerable
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Srbds: Not affected
Tsx async abort: Not affected
```
Kernel and OS:
```
Linux srv27 6.5.11-7-pve #1 SMP PREEMPT_DYNAMIC PMX 6.5.11-7 (2023-12-05T09:44Z) x86_64 GNU/Linux
PRETTY_NAME="Debian GNU/Linux 12 (bookworm)"
NAME="Debian GNU/Linux"
VERSION_ID="12"
VERSION="12 (bookworm)"
VERSION_CODENAME=bookworm
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
```
Proxmox version 8.1.4
my worker node config:
```
balloon: 0
boot: order=scsi0;ide2;net0
cores: 16
cpu: host
ide2: local:iso/jammy-live-server-amd64.iso,media=cdrom,size=2074756K
memory: 23000
meta: creation-qemu=8.0.2,ctime=1700910378
name: k8s-worker-3
net0: virtio=C6:CA:39:F8:0C:19,bridge=vmbr0
numa: 0
ostype: l26
scsi0: local-lvm:vm-202-disk-0,backup=0,iothread=1,replicate=0,size=100G
scsihw: virtio-scsi-single
smbios1: uuid=333b40d8-bbee-42a7-ae5e-d03fbc0a16e8
sockets: 1
vmgenid: 8aaa1eee-2d78-4730-bc5c-26ae1e4f56ab
```
I tried with NUMA enabled/disabled and there's no difference.
numactl --hardware
```
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 24084 MB
node 0 free: 20417 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 24128 MB
node 1 free: 21646 MB
node distances:
node 0 1
0: 10 20
1: 20 10
```
ATM I'm updating to latest available kernel 6.5.13-1
--- UPDATE
upgraded to latest version and kernel and problem still exist
removed those 2x ram and 2x hard drives from server
I still have the issue (I hadn't it before adding new hardwares)
can anyone help me on this issue please?
I have multiple Proxmox instances all are running on hp del360 gen8
Today I added 2x RAM and 2x SSD to one of my servers. I haven't yet started to use new hard drvies(level 1 RAID at hardware level).
My VMs became too slow. I think my RAM performance is okay but CPU usage jumps to sky when I start using VMs on this node.
I have a Kubernetes VM worker and when I start scheduling workload on it cpu usage goes high - RAM usage stays low (I believe reason is that poor CPU performance does not let workload to start and use memory). I believe this problem is not related to disk I/O since my workload doesn't use any disk (rarely).
Here information related to my proxmox cpu:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 24
On-line CPU(s) list: 0-23
Vendor ID: GenuineIntel
BIOS Vendor ID: Intel
Model name: Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz
BIOS Model name: Intel(R) Xeon(R) CPU E5-2620 0 @ 2.00GHz CPU @ 2.0GHz
BIOS CPU family: 179
CPU family: 6
Model: 45
Thread(s) per core: 2
Core(s) per socket: 6
Socket(s): 2
Stepping: 7
CPU(s) scaling MHz: 97%
CPU max MHz: 2500.0000
CPU min MHz: 1200.0000
BogoMIPS: 3990.43
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pd
pe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor
ds_cpl vmx smx est tm2 ssse3 cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic popcnt tsc_deadline_timer aes xsave avx lahf_lm epb pti ibr
s ibpb stibp tpr_shadow flexpriority ept vpid xsaveopt dtherm ida arat pln pts vnmi
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 384 KiB (12 instances)
L1i: 384 KiB (12 instances)
L2: 3 MiB (12 instances)
L3: 30 MiB (2 instances)
NUMA:
NUMA node(s): 2
NUMA node0 CPU(s): 0-5,12-17
NUMA node1 CPU(s): 6-11,18-23
Vulnerabilities:
Gather data sampling: Not affected
Itlb multihit: KVM: Mitigation: Split huge pages
L1tf: Mitigation; PTE Inversion; VMX conditional cache flushes, SMT vulnerable
Mds: Vulnerable: Clear CPU buffers attempted, no microcode; SMT vulnerable
Meltdown: Mitigation; PTI
Mmio stale data: Unknown: No mitigations
Retbleed: Not affected
Spec rstack overflow: Not affected
Spec store bypass: Vulnerable
Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP conditional, RSB filling, PBRSB-eIBRS Not affected
Srbds: Not affected
Tsx async abort: Not affected
```
Kernel and OS:
```
Linux srv27 6.5.11-7-pve #1 SMP PREEMPT_DYNAMIC PMX 6.5.11-7 (2023-12-05T09:44Z) x86_64 GNU/Linux
PRETTY_NAME="Debian GNU/Linux 12 (bookworm)"
NAME="Debian GNU/Linux"
VERSION_ID="12"
VERSION="12 (bookworm)"
VERSION_CODENAME=bookworm
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
```
Proxmox version 8.1.4
my worker node config:
```
balloon: 0
boot: order=scsi0;ide2;net0
cores: 16
cpu: host
ide2: local:iso/jammy-live-server-amd64.iso,media=cdrom,size=2074756K
memory: 23000
meta: creation-qemu=8.0.2,ctime=1700910378
name: k8s-worker-3
net0: virtio=C6:CA:39:F8:0C:19,bridge=vmbr0
numa: 0
ostype: l26
scsi0: local-lvm:vm-202-disk-0,backup=0,iothread=1,replicate=0,size=100G
scsihw: virtio-scsi-single
smbios1: uuid=333b40d8-bbee-42a7-ae5e-d03fbc0a16e8
sockets: 1
vmgenid: 8aaa1eee-2d78-4730-bc5c-26ae1e4f56ab
```
I tried with NUMA enabled/disabled and there's no difference.
numactl --hardware
```
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 12 13 14 15 16 17
node 0 size: 24084 MB
node 0 free: 20417 MB
node 1 cpus: 6 7 8 9 10 11 18 19 20 21 22 23
node 1 size: 24128 MB
node 1 free: 21646 MB
node distances:
node 0 1
0: 10 20
1: 20 10
```
ATM I'm updating to latest available kernel 6.5.13-1
--- UPDATE
upgraded to latest version and kernel and problem still exist
removed those 2x ram and 2x hard drives from server
I still have the issue (I hadn't it before adding new hardwares)
can anyone help me on this issue please?
Last edited: